FunctionSurvivalEstimationLibrary "FunctionSurvivalEstimation"
The Survival Estimation function, also known as Kaplan-Meier estimation or product-limit method, is a statistical technique used to estimate the survival probability of an individual over time. It's commonly used in medical research and epidemiology to analyze the survival rates of patients with different treatments, diseases, or risk factors.
What does it do?
The Survival Estimation function takes into account censored observations (i.e., individuals who are still alive at a certain point) and calculates the probability that an individual will survive beyond a specific time period. It's particularly useful when dealing with right-censoring, where some subjects are lost to follow-up or have not experienced the event of interest by the end of the study.
Interpretation
The Survival Estimation function provides a plot of the estimated survival probability over time, which can be used to:
1. Compare survival rates between different groups (e.g., treatment arms)
2. Identify patterns in the data that may indicate differences in mortality or disease progression
3. Make predictions about future outcomes based on historical data
4. In a trading context it may be used to ascertain the survival ratios of trading under specific conditions.
Reference:
www.global-developments.org
"Beyond GDP" ~ www.aeaweb.org
en.wikipedia.org
www.kdnuggets.com
survival_probability(alive_at_age, initial_alive)
Kaplan-Meier Survival Estimator.
Parameters:
alive_at_age (int) : The number of subjects still alive at a age.
initial_alive (int) : The Total number of initial subjects.
Returns: The probability that a subject lives longer than a certain age.
utility(c, l)
Captures the utility value from consumption and leisure.
Parameters:
c (float) : Consumption.
l (float) : Leisure.
Returns: Utility value from consumption and leisure.
welfare_utility(age, b, u, s)
Calculate the welfare utility value based age, basic needs and social interaction.
Parameters:
age (int) : Age of the subject.
b (float) : Value representing basic needs (food, shelter..).
u (float) : Value representing overall well-being and happiness.
s (float) : Value representing social interaction and connection with others.
Returns: Welfare utility value.
expected_lifetime_welfare(beta, consumption, leisure, alive_data, expectation)
Calculates the expected lifetime welfare of an individual based on their consumption, leisure, and survival probability over time.
Parameters:
beta (float) : Discount factor.
consumption (array) : List of consumption values at each step of the subjects life.
leisure (array) : List of leisure values at each step of the subjects life.
alive_data (array) : List of subjects alive at each age, the first element is the total or initial number of subjects.
expectation (float) : Optional, `defaut=1.0`. Expectation or weight given to this calculation.
Returns: Expected lifetime welfare value.
Estimation

Static price-range projection by symbolThis indicator shows you a predefined range to the right of the last candle of your chart. This range is custom and can be changed for a handful of symbols that you can choose. This scale will help you determining if the market is providing a reasonable range before you enter a trade or if the market isn't actually moving as much as you might think. This is particularly useful if you are into scalping and have to consider commission or spread in your trades.
Since all symbols have different price ranges in which they move this indicator doesn't make sense to just have "a one size fits all" approach. That's why you can choose up to 6 symbols and set the range that you want to have shown for each when you pull it up on the chart. Using my default values that means for when the NQ (Nasdaq future) is on the chart you will see a range of 20 handles projected. When you change the the ES (S&P500 future) you will instead see 5 handles. While the number is different that is somewhat of an equal move in both symbols.
There also is an option to set a default price range for all other symbols that are not selected if it is needed. However the display of the scale on anything else than the 6 selected symbols can also be turned off.
There are options provided on how exactly you want to indicator to determine if the chart symbol matches one of the selected symbols.
You can enable it to make sure the exchange/broker is the exact same as selected.
It can check for only the symbol root to match the selection. Specifically for futures this means that while ES1! might be selected, anything ES (ES1!, ES2!, ESH2025, ESM2025, ESM2022, ...) will be a match to the selection)
On the painted scale it is possible to not just show this range extended into each direction once. Per default you will have 3 segments of it in each direction. This can be reduced to just 1 or increased.
If you chose a high number of segments or a large range make sure to use the "Scale price chart only" option on your chart scale to not have the symbols price candles squished together by the charts auto scaling.
And last but not least the indicator options provide some possibilities to change the appearance of the printed price range scale in case you disagree with my design.

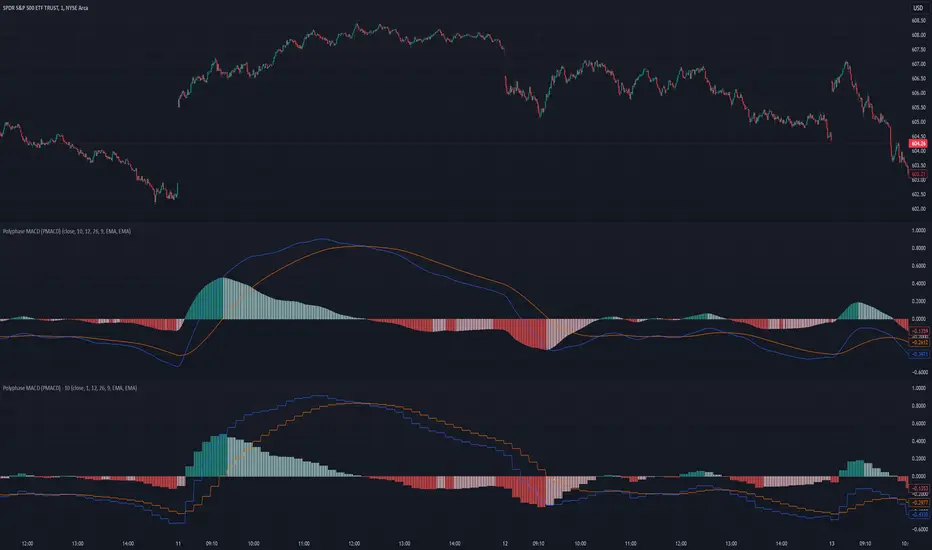
Polyphase MACD (PMACD)The Polyphase MACD (PMACD) uses polyphase decimation to create a continuous estimate of higher timeframe MACD behavior. The number of phases represents the timeframe multiplier - for example, 3 phases approximates a 3x higher timeframe.
Traditional higher timeframe MACD indicators update only when each higher timeframe bar completes, creating stepped signals that can miss intermediate price action. The PMACD addresses this by maintaining multiple phase-shifted MACD calculations and combining them with appropriate anti-aliasing filters. This approach eliminates the discrete jumps typically seen in higher timeframe indicators, though the resulting signal may sometimes deviate from the true higher timeframe values due to its estimative nature.
The indicator processes price data through parallel phase calculations, each analyzing a different time-offset subset of the data. These phases are filtered and combined to prevent aliasing artifacts that occur in simple timeframe conversions. The result is a smooth, continuous signal that begins providing meaningful values immediately, without requiring a warm-up period of higher timeframe bars.
The PMACD maintains the standard MACD components - the MACD line (fast MA - slow MA), signal line, and histogram - while providing a more continuous view of higher timeframe momentum. Users can select between EMA and SMA calculations for both the oscillator and signal components, with all calculations benefiting from the same polyphase processing technique.
Faytterro Oscillatorwhat is Faytterro oscillator?
An oscillator that perfectly identifies overbought and oversold zones.
what it does?
this places the price between 0 and 100 perfectly but with a little delay. To eliminate this delay, it predicts the price to come, and the indicator becomes clearer as the probability of its prediction increases.
how it does it?
This indicator is obtained with "faytterro bands", another indicator I designed. For more information about faytterro bands:
A kind of stochastic function is applied to the faytterro bands indicator, and then another transformation formula that I have designed and explained in detail in the link above is applied. These formulas are also applied again to calculate the prediction parts.
how to use it?
Use this indicator to see past overbought and oversold zones and to see future ones.
The input named source is used to change the source of the indicator.
The length serves to change the signal frequency of the indicator.

Profit EstimateLibrary "profitestimate"
Simple profit Estimatr. Engages when Position != 0
and holds until posittion is na/0...
if position changes sizes, it will update automatically and adjust.
it has an input for comission to estmate exit fees
update_avgprice(_sizewas, _delta, _pricewas, _newprice)
Get a new Average position Price
Parameters:
_sizewas : (float) the position prior
_delta : (float) the order amount
_pricewas : (float) the prior price
_newprice : (float) the price of order
Returns: New Avg Price
amount(_position, _close, _commission, _leverage, _fullqty)
Position Net Profit Net Commission, automatic on/off if position != 0
Parameters:
_position : (float) position size (total or margin size)
_close
_commission : (float) % where (0.1 = 0.1%)
_leverage : (float) optional if leveraged, default 1x
_fullqty : (bool) if position entered is tottal trade size default is margin qty (1/lev)
Returns: quote value of profit
percent(_position, _close, _commission, _leverage, _fullqty)
Position Net Profit, automatic on/off if position != 0
Parameters:
_position : (float) position size (total or margin size)
_close
_commission : (float) % where (0.1 = 0.1%)
_leverage : (float) optional if leveraged, default 1x
_fullqty : (bool) if position entered is tottal trade size, default is margin qty (1/lev)
Returns: percentage profit (1% = 1)
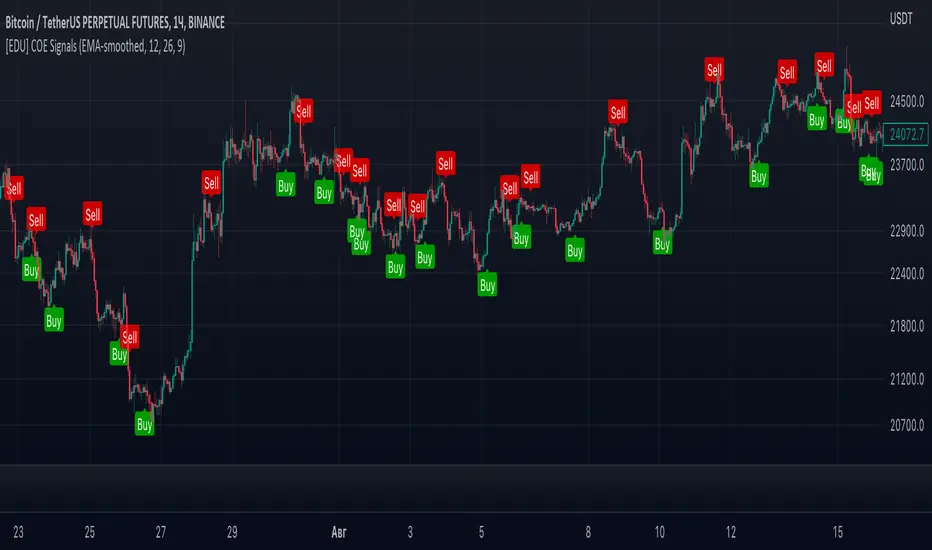
[EDU] Close Open Estimation Signals (COE Signals)EN:
Close Open Estimation ( aka COE ) is a very simple swing-trading indicator based on even simpler idea. This indicator is from my educational series, which means that I just want to share with another way to look at the market in order to broaden your knowledge .
Idea :
Let's take n previous bars and make a sum a of close - open -values of each bar. Knowledgeable of you may already see the similarity to RSI calculation idea . Now let's plot this sum and see what we have now.
We can see, that whenever COE crosses over 0-level, uptrend begins, and if COE crosses under 0-level, downtrend begins. The speed of such signals can be adjusted by changing lookback period: the lower the lookback, the faster signals you get, but high-quality ones can be obtained only via not-so-fast lookback as when the market is consolidating or volatility is to high, there can be many garbage signals, like 95+% of other indicators have.
Let's explore more and calculate volatility of COE(v_coe in the code): current COE - previous CEO .
Now it appears that when v_coe crosses over 0-level, it's a signal, that this is a new low and soon the uptrend will follow. Analogically for crossing under 0-level .
I guess now you understood what these all are about: COE crossings show global trend signals , while Volatility COE ( v_coe or VCOE ) crossings show reversal points .
For signals I further calculated volatility of VCOE(VVCOE) and then volatility of VVCOE(VVVCOE). Why? Because for me they seem to be more accurate, but you are welcome to experiment and figure best setups for yourself and by yourself, I just share my opinion and experience .
COE can be helpful only in high liquidity markets with good trend or wide sideways .
If you want to experiment with COE, just copy the code and play with it. Curious of you will probably find it helpful eventhough the idea is way too simple.
By it's perfomance COE can probably beat QQE at open price settings.
(use open of the price at indicator to get zero repaint! )
Examples :
If you any questions, feel free to DM me or leave comments.
Good luck and take your profits!
- Fyodor Tarasenko
RU:
Close Open Estimation ( aka COE ) — это очень простой индикатор свинг-трейдинга, основанный на еще более простой идее. Этот индикатор из моей образовательной серии, а это значит, что я просто хочу поделиться с другим взглядом на рынок , чтобы расширить ваши знания .
Идея :
Возьмем n предыдущих баров и составим сумму a из close - open -значений каждого бара. Знающие люди могут уже заметить сходство с идеей расчета RSI . Теперь давайте построим эту сумму и посмотрим, что у нас сейчас есть.
Мы видим, что всякий раз, когда COE пересекает выше 0-уровня, начинается восходящий тренд , а если COE пересекает ниже 0-уровня, начинается нисходящий тренд. Скорость таких сигналов можно регулировать изменением ретроспективы: чем меньше ретроспектива, тем быстрее вы получаете сигналы, но качественные можно получить только через не- такой быстрый взгляд назад, как когда рынок консолидируется или волатильность слишком высока, может быть много мусорных сигналов, как у 95+% других индикаторов.
Давайте рассмотрим больше и рассчитаем волатильность COE(v_coe в коде): текущий COE - предыдущий CEO .
Теперь кажется, что когда v_coe пересекает уровень 0, это сигнал о том, что это новый минимум и вскоре последует восходящий тренд . Аналогично для пересечения под 0-уровнем .
Думаю, теперь вы поняли, о чем все это: COE пересечения показывают глобальные сигналы тренда , а пересечения Volatility COE ( v_coe или VCOE ) показывают точки разворота .
Для сигналов я дополнительно рассчитал волатильность VCOE(VVCOE), а затем волатильность VVCOE(VVVCOE). Почему? Потому что для меня они кажутся более точными, но вы можете поэкспериментировать и подобрать оптимальные настройки для себя и для себя, я просто делюсь своим мнением и опытом .
COE может быть полезен только на рынках с высокой ликвидностью и хорошим трендом или широким боковиком .
Если вы хотите поэкспериментировать с COE, просто скопируйте код и поэкспериментируйте с ним. Любознательные из вас, вероятно, сочтут это полезным, хотя идея слишком проста.
По своей результативности СОЕ может составить конкуренцию широко известному QQE, используя open цены.
(используйте open цены на индикаторе, чтобы получить нулевую перерисовку! )
Примеры :
Если у вас есть вопросы, пишите мне в личные сообщения или оставляйте комментарии.
Удачи и профита всем!
- Федор Тарасенко
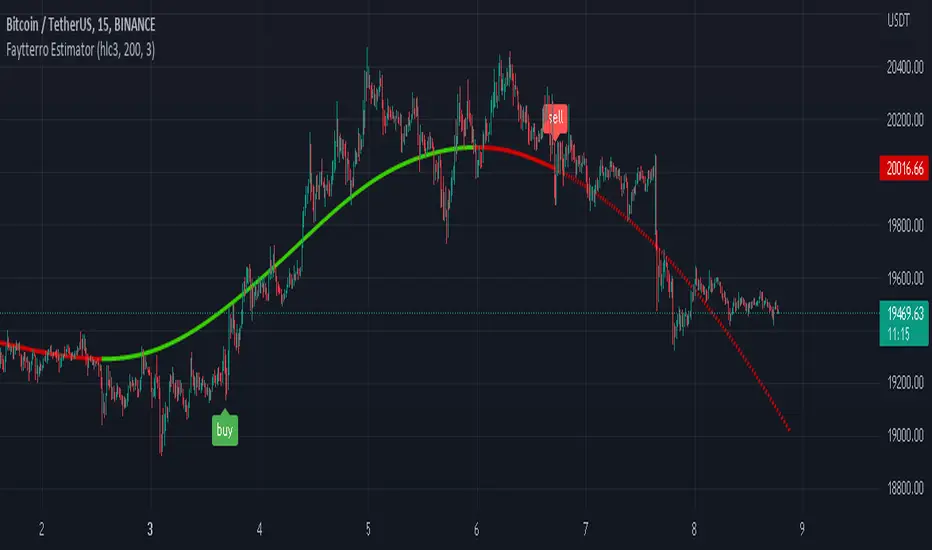
Faytterro EstimatorWhat is Faytterro Estimator?
This indicator is an advanced moving average.
What it does?
This indicator is both a moving average and at the same time, it predicts the future values that the price may take based on the values it has taken before.
How it does it?
takes the weighted average of data of the selected length (reducing the weight from the middle to the ends). then draws a parabola through the last three values, creating a predicted line.
How to use it?
it is simple to use. You can use it both as a regression to review past prices, and to predict the future value of a price. uptrends are in green and downtrends are in red. color change indicates a possible trend change.
Nearest Neighbor Extrapolation of Price [Loxx]I wasn't going to post this because I don't like how this calculates by puling in the Open price, but I'm posting it anyway. This does work in it's current form but there is a. better way to do this. I'll revisit this in the future.
Anyway...
The k-Nearest Neighbor algorithm (k-NN) searches for k past patterns (neighbors) that are most similar to the current pattern and computes the future prices based on weighted voting of those neighbors. This indicator finds only one nearest neighbor. So, in essence, it is a 1-NN algorithm. It uses the Pearson correlation coefficient between the current pattern and all past patterns as the measure of distance between them. Also, this version of the nearest neighbor indicator gives larger weights to most recent prices while searching for the closest pattern in the past. It uses a weighted correlation coefficient, whose weight decays linearly from newer to older prices within a price pattern.
This indicator also includes an error window that shows whether the calculation is valid. If it's green and says "Passed", then the calculation is valid, otherwise it'll show a red background and and error message.
Inputs
Npast - number of past bars in a pattern;
Nfut -number of future bars in a pattern (must be < Npast).
lastbar - How many bars back to start forecast? Useful to show past prediction accuracy
barsbark - This prevents Pine from trying to calculate on all past bars
Related indicators
Hodrick-Prescott Extrapolation of Price
Itakura-Saito Autoregressive Extrapolation of Price
Helme-Nikias Weighted Burg AR-SE Extra. of Price
Weighted Burg AR Spectral Estimate Extrapolation of Price
Levinson-Durbin Autocorrelation Extrapolation of Price
Fourier Extrapolator of Price w/ Projection Forecast

test - delta distributiona test case for the KDE function on price delta.
the KDE function can be used to quickly check or confirm edge cases of the trading systems conditionals.

Function - Kernel Density Estimation (KDE)"In statistics, kernel density estimation (KDE) is a non-parametric way to estimate the probability density function of a random variable."
from wikipedia.com
KDE function with optional kernel:
Uniform
Triangle
Epanechnikov
Quartic
Triweight
Gaussian
Cosinus
Republishing due to change of function.
deprecated script:

KDE-Gaussian"In statistics, kernel density estimation (KDE) is a non-parametric way to estimate the probability density function of a random variable."
from wikipedia.com

Japanese Correlation CoefficientIntroduction
This indicator was asked and named by a trading meetup participant in Sevilla. The original question was "How to estimate the correlation between the price and a line as easy as possible", a question who got little attention. I previously proposed a correlation estimate using a modification of the standard score (see at the end of the post) for the estimation of a Savitzky-Golay moving average (LSMA) of order 1, however something faster could maybe be done and this is why i accepted the challenge.
Japanese Correlation
Correlation is defined as the linear relationship between two variables x and y , if x and y follow the same direction then the correlation increase else decrease. The correlation coefficient is always equal or below 1 and equal or above -1, it also have to be taken into account that this coefficient is quite smooth. Smoothing is not a problem, scaling however require more attention, high price > closing price > low price, therefore scaling can be done. First we smooth the closing/high/low price with a simple moving average of period p/2 , then we take the difference of the smoothed close with the smoothed close p/2 bars back, this result is then divided by the difference between the highest smoothed high's with the lowest smoothed low's over period p/2 .
Since we use information provided by candlesticks (close/high/low) i have been asked to publish this estimator with the name Japanese correlation coefficient , this name don't imply the use of data from Japanese markets, "Japanese" is used because of the candlestick method coming from Japan.
Comparison
I compare this estimation with the correlation coefficient provided in pinescript by the correlation function.
The estimation in orange with the original correlation coefficient using n as independent variable in blue with both length = 50.
comparison with length = 200.
Conclusion
I have shown that it is possible to roughly estimate the correlation coefficient between price and a linear function by using different price information. Correlation can be further estimated by using homogeneous bridge OHLC volatility estimators thus making able the use of different independent variables. I really hope you like this indicator and thanks to the meetup participant asking the question, i had a lot of fun making the indicator.
An alternative method

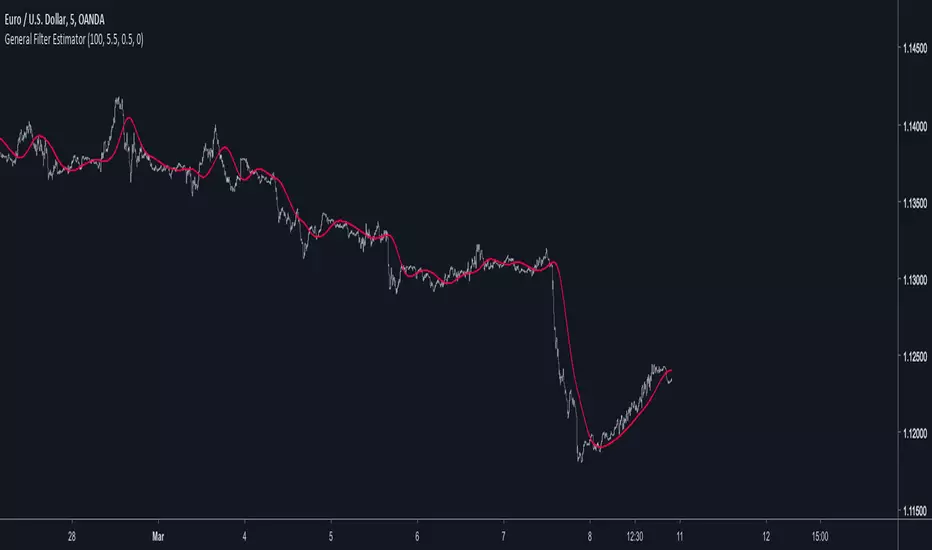
General Filter Estimator-An Experiment on Estimating EverythingIntroduction
The last indicators i posted where about estimating the least squares moving average, the task of estimating a filter is a funny one because its always a challenge and it require to be really creative. After the last publication of the 1LC-LSMA , who estimate the lsma with 1 line of code and only 3 functions i felt like i could maybe make something more flexible and less complex with the ability to approximate any filter output. Its possible, but the methods to do so are not something that pinescript can do, we have to use another base for our estimation using coefficients, so i inspired myself from the alpha-beta filter and i started writing the code.
Calculation and The Estimation Coefficients
Simplicity is the key word, its also my signature style, if i want something good it should be simple enough, so my code look like that :
p = length/beta
a = close - nz(b ,close)
b = nz(b ,close) + a/p*gamma
3 line, 2 function, its a good start, we could put everything in one line of code but its easier to see it this way. length control the smoothing amount of the filter, for any filter f(Period) Period should be equal to length and f(Period) = p , it would be inconvenient to have to use a different length period than the one used in the filter we want to estimate (imagine our estimation with length = 50 estimating an ema with period = 100) , this is where the first coefficients beta will be useful, it will allow us to leave length as it is. In general beta will be greater than 1, the greater it will be the less lag the filter will have, this coefficient will be useful to estimate low lagging filters, gamma however is the coefficient who will estimate lagging filters, in general it will range around .
We can get loose easily with those coefficients estimation but i will leave a coefficients table in the code for estimating popular filters, and some comparison below.
Estimating a Simple Moving Average
Of course, the boxcar filter, the running mean, the simple moving average, its an easy filter to use and calculate.
For an SMA use the following coefficients :
beta = 2
gamma = 0.5
Our filter is in red and the moving average in white with both length at 50 (This goes for every comparison we will do)
Its a bit imprecise but its a simple moving average, not the most interesting thing to estimate.
Estimating an Exponential Moving Average
The ema is a great filter because its length times more computing efficient than a simple moving average. For the EMA use the following coefficients :
beta = 3
gamma = 0.4
N.B : The EMA is rougher than the SMA, so it filter less, this is why its faster and closer to the price
Estimating The Hull Moving Average
Its a good filter for technical analysis with tons of use, lets try to estimate it ! For the HMA use the following coefficients :
beta = 4
gamma = 0.85
Looks ok, of course if you find better coefficients i will test them and actualize the coefficient table, i will also put a thank message.
Estimating a LSMA
Of course i was gonna estimate it, but this time this estimation does not have anything a lsma have, no moving average, no standard deviation, no correlation coefficient, lets do it.
For the LSMA use the following coefficients :
beta = 3.5
gamma = 0.9
Its far from being the best estimation, but its more efficient than any other i previously made.
Estimating the Quadratic Least Square Moving Average
I doubted about this one but it can be approximated as well. For the QLSMA use the following coefficients :
beta = 5.25
gamma = 1
Another ok estimate, the estimate filter a bit more than needed but its ok.
Jurik Moving Average
Its far from being a filter that i like and its a bit old. For the comparison i will use the JMA provided by @everget described in this article : c.mql5.com
For the JMA use the following coefficients :
for phase = 0
beta = pow*2 (pow is a parameter in the Jma)
gamma = 0.5
Here length = 50, phase = 0, pow = 5 so beta = 10
Looks pretty good considering the fact that the Jma use an adaptive architecture.
Discussion
I let you the task to judge if the estimation is good or not, my motivation was to estimate such filters using the less amount of calculations as possible, in itself i think that the code is quite elegant like all the codes of IIR filters (IIR Filters = Infinite Impulse Response : Filters using recursion) .
It could be possible to have a better estimate of the coefficients using optimization methods like the gradient descent. This is not feasible in pinescript but i could think about it using python or R.
Coefficients should be dependant of length but this would lead to a massive work, the variation of the estimation using fixed coefficients when using different length periods is just ok if we can allow some errors of precision.
I dont think it should be possible to estimate adaptive filter relying a lot on their adaptive parameter/smoothing constant except by making our coefficients adaptive (gamma could be)
So at the end ? What make a filter truly unique ? From my point of sight the architecture of a filter and the problem he is trying to solve is what make him unique rather than its output result. If you become a signal, hide yourself into noise, then look at the filters trying to find you, what a challenging game, this is why we need filters.
Conclusion
I wanted to give a simple filter estimator relying on two coefficients in order to estimate both lagging and low-lagging filters. I will try to give more precise estimate and update the indicator with new coefficients.
Thanks for reading !
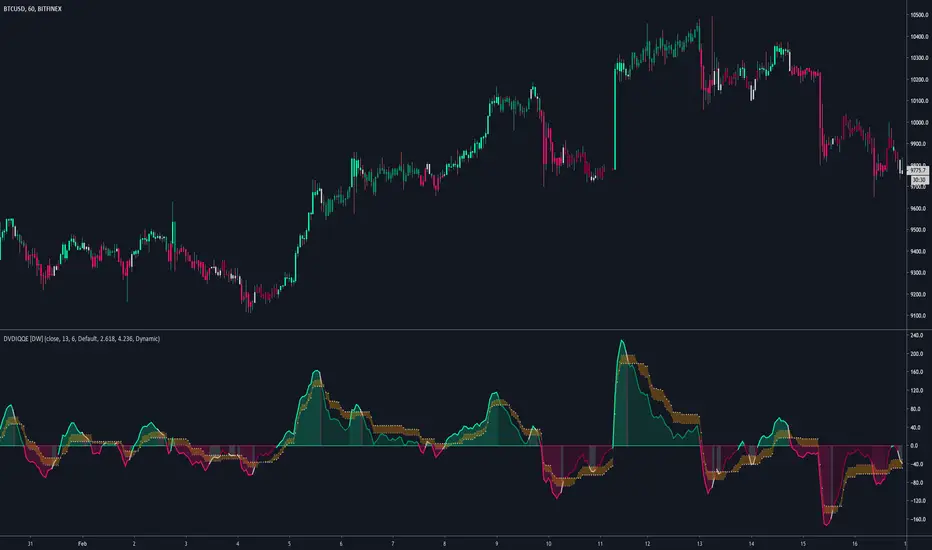
DVDIQQE [DW]This is an experimental study inspired by the Quantitative Qualitative Estimation indicator designed to identify trend and wave activity.
In this study, rather than using RSI for the calculation, the Dual Volume Divergence Index oscillator is utilized.
First, the DVDI oscillator is calculated by taking the difference between PVI and its EMA, and NVI and its EMA, then taking the difference between the two results.
Optional parameters for DVDI calculation are included within this script:
- An option to use tick volume rather than real volume for the volume source
- An option to use cumulative data, which sums the movements of the oscillator from the beginning to the end of TradingView's maximum window to give a more broad picture of market sentiment
Next, two trailing levels are calculated using the average true range of the oscillator. The levels are then used to determine wave direction.
Lastly, rather than using 0 as the center line, it is instead calculated by taking a cumulative average of the oscillator.
Custom bar colors are included.
Note: For charts that have no real volume component, use tick volume as the volume source.
Price Regression AgreggatorPrice Estimator with aggregated linear regresion
---------------------------------------------------------------------------
How it works:
It uses 6 linear regression from time past to get an estimated point in future time, and using transparency, those areas that are move "visited" by those 6 different regressions and maybe more probable to be visited by the price (in fact if you zoom out you will see that price normally is around the lighter zones) have more aggregated painted colors, the transparency is lower and well, the lighter area should be more probable to be visited by the price should we put any faith on linear regression estimations and even more when many of them coincide in several points where the color is more aggregated.
If the "I" (the previous regressions increment) is too low, then we will have huge spikes as the only info gathered from the oldest linear regresssion will be within the very same trend we are now, resulting in "predictions" of huge spikes in the trend direction. (all regressions estimating on a line pointing to infinite)
If the "I" is high enough (not very or TV won't be able to display it) then you will get somewhat a "vectorial" resultant force of many linear regressions giving a more "real prediction" as it comes from tendencies from higher timeframes. E.g. 12 hours could be going down, 4h could be going sideways, 30m could be going up.
contact tradingview -> hecate . The idea and implementation is mine.
Note: transparency + 10 * tranparencygradient cannot be > 100 or nothing will be displayed
Note2: if the Future increment (how many lines are displayed to the right of the actual price ) are excessive, it will start to do weird things.
Note3: two times the standard deviation statistically correponds to a probability of 95%. We are calculating Top and Bot with that amount above and below. So anything inside those limits is more probable and if we are out of those limits it should fall back soon. Increase the number of times the std deviation as desired. There are calculators in the web to translate number of times std dev to their correspondent probability.
Note4: As we use backwards in time linear regressions for our "predictions" we lose responsiveness. Those old linear regressions are weighted with less value than more recent ones.
Note5: In the code i have included many color combinations (some horrible :-) )
Note6: This was an experiment while i was quite bored although ended enjoying playing with it.
Have fun! :-)
I leave it here because i am getting dizzy.
