Non-Psychological Levels🟩 Non-Psychological Levels is a structural analysis tool that segments price action into objective ranges, identifying Broken and Unbroken levels without relying on psychological or time-based assumptions. By emphasizing mechanically derived price behavior, it provides traders with a clear framework for analyzing support and resistance in a consistent and unbiased manner across various market conditions.
This indicator introduces a new approach to understanding market structure by focusing on price movement within defined segments, free from behavioral patterns, round numbers, or specific time intervals. While the indicator is time-agnostic in design, it works within the natural time progression of the chart, ensuring that segmentation aligns with the inherent structure of price movement. Broken levels, where price has breached a structural boundary, and Unbroken levels, which remain intact, are visualized with horizontal lines. These structural zones are complemented by dynamically boxed segments that contextualize both historical and ongoing price behavior.
By offering an objective perspective, the Non-Psychological Levels indicator complements psychology-based tools, helping traders explore market dynamics from multiple angles. When structural levels align with psychological zones, they reinforce critical price areas; when they differ, they provide opportunities to analyze price behavior from an alternative lens. This indicator is designed as both an educational framework and a practical tool, encouraging a deeper understanding of structural price behavior in technical analysis.
⭕ THEORY AND CONCEPT ⭕
The Non-Psychological Levels indicator is grounded in the principle of analyzing price behavior without reliance on psychological assumptions or time-based factors. Its primary purpose is to provide a structural framework for identifying support and resistance levels by focusing solely on price movement within mechanically defined segments. By removing external influences such as sentiment, time intervals, or market sessions, the indicator offers an unbiased lens through which traders can observe price dynamics.
Non-psychology, as defined here, refers to an approach that excludes behavioral and emotional patterns—like fear, greed, or herd mentality—from price analysis. Traditional tools often depend on these patterns to identify zones such as pivots or Fibonacci retracements, but these methods can be inconsistent in volatile markets. In contrast, the Non-Psychological Levels indicator focuses entirely on what price is doing, free from assumptions about trader behavior or external time constraints.
The indicator’s time-agnostic and mechanically driven design segments price action into consistent ranges, highlighting "Broken" levels (where price breaches structural boundaries) and "Unbroken" levels (where price holds). These structural zones remain unaffected by subjective or external influences, ensuring clarity and consistency across different markets and timeframes. By doing so, the indicator reveals a pure view of price structure, independent of psychological biases.
Importantly, the Non-Psychological Levels indicator is not intended to replace psychology-based tools but to complement them. When its structural levels align with psychological zones like round numbers or session highs/lows, the significance of these areas is reinforced. Conversely, when the levels differ, the contrast provides traders with alternative insights into market dynamics. This dual perspective—blending mechanical objectivity with behavioral analysis—enhances the depth and flexibility of market evaluation.
The following principles outline the theoretical foundation of the indicator and its unique contribution to structural price analysis:
Time-Agnostic Design : The indicator avoids reliance on time-based factors like daily opens, session intervals, or specific events. Instead, it segments price action using bar indexes, ensuring that structural levels are identified independently of external time variables. While the x-axis of a chart inherently represents time, this indicator abstracts away its influence, allowing traders to focus purely on price movement without the bias of temporal context.
Mechanical and Neutral Framework : Every calculation within the indicator is predetermined by a set of mechanical rules, ensuring no subjective input or interpretation affects the results. This objectivity guarantees that levels are derived solely from observed price behavior, providing a reliable framework that traders can trust to remain consistent across different assets, timeframes, and market conditions.
Broken and Unbroken Levels : Broken levels represent zones where price has breached a structural boundary, while Unbroken levels highlight areas where price has consistently respected its range. This distinction provides a clear and systematic method for identifying key support and resistance levels, offering insights into where future price interactions are most likely to occur.
Neutral Price Behavior : By dividing price action into equal segments, the indicator removes the influence of external factors like trader sentiment or psychological expectations. Each segment independently determines significant levels based purely on price action, enabling a structural view of the market that abstracts away behavioral or emotional biases.
Complement to Psychological Tools : While the indicator itself avoids behavioral assumptions, its levels can align with psychological zones like round numbers, pivots, or Fibonacci levels. When these structural and psychological levels overlap, it reinforces the importance of key areas, while divergences offer opportunities to examine price behavior from a new perspective.
Educational Value : The indicator encourages traders to explore the contrast between structural and psychological analysis. By introducing a framework that isolates price behavior from external influences, it challenges traditional methods of technical analysis, fostering deeper insights into market structure and behavior.
🔍 UNDERSTANDING STRUCTURAL LEVELS 🔍
The Non-Psychological Levels indicator offers a straightforward yet powerful way to understand market structure by segmenting price action into mechanically defined ranges. This segmentation highlights two key elements: "Broken" levels, where price has breached structural boundaries, and "Unbroken" levels, which remain intact and respected by price action. Together, these components create a framework for identifying potential areas of support and resistance.
Broken Levels : These are structural boundaries that price has surpassed, indicating areas where previous support or resistance failed. Broken levels often signal transitions in price behavior, such as shifts in momentum or the start of trending movements. They provide insight into zones where price has already tested and moved beyond.
Unbroken Levels : These levels remain intact within a given price segment, marking areas where price has consistently respected boundaries. Unbroken levels are particularly useful for identifying potential reversal points or zones of continued support or resistance. Their persistence across price action often makes them reliable indicators of market structure.
The visual segmentation of price action into distinct ranges allows traders to observe how price transitions between structural zones. For example:
- Clusters of Unbroken levels near the current price may suggest strong support or resistance, offering areas of interest for reversals or breakouts.
- Gaps between Unbroken levels highlight areas of price inefficiency or low interaction, which may become significant if revisited.
By focusing solely on structural price behavior, the Non-Psychological Levels indicator enables traders to analyze price independently of time or psychological factors. This makes it a valuable tool for understanding price dynamics objectively, whether used on its own or alongside other indicators.
🛠️ SETTINGS 🛠️
The Non-Psychological Levels indicator offers various customizable settings to help users tailor its visualization to their specific trading style and market conditions. These settings allow adjustments to sensitivity, level projection, and the source of price calculations (e.g., wicks or closing prices). Below, we outline each setting and its impact on the chart, along with examples to illustrate their functionality.
Custom Settings
Sensitivity : This setting adjusts the balance between detailed and broader structural levels by controlling the number of segments. Higher values result in more segments, revealing finer price levels, while lower values consolidate segments to highlight major price movements.
Source : Allows the user to choose between 'Wick' or 'Close' for detecting levels. Selecting 'Wick' emphasizes the absolute highs and lows of price action, while 'Close' focuses on closing prices within each segment.
Level Labels : Configures the visual representation of price levels, allowing users to toggle between price values, symbols (▲ ▼), or disabling labels altogether. This setting ensures clarity in how Broken and Unbroken levels are displayed on the chart.
Unbroken Levels : - - - Users can customize the colors and label styles for Unbroken levels, which highlight areas where price has respected structural boundaries.
Broken Levels : -|- Similar to Unbroken levels, users can specify the visual appearance of Broken levels, including color customization for Broken highs and lows. These settings help distinguish areas where price has breached a structural boundary.
Projection Options : This setting allows users to control how broken and unbroken levels are visually extended on the chart. The Future option projects lines forward to the right of the current price, showing potential future relevance of levels. The All option extends lines both forward and backward, providing a comprehensive view of how levels align with historical and potential future price action. The None option disables projections, keeping the chart focused solely on current segment levels without any extensions.
Segments : Includes options for customizing the segment visualization:
- Live Segment : Toggles the display of a highlighted box representing the current developing segment, helping users focus on ongoing price action.
- Boxes : Allows users to display filled boxes around each segment for additional visual emphasis.
- Segment Colors : Users can define separate colors for support (lower) and resistance (upper) segments, making it easier to interpret directional trends.
- Boundaries : Enables or disables vertical lines to mark segment boundaries, providing a clearer view of structural divisions.
Repaint : This setting allows users to enable or disable triangle labels within the live segment. When enabled, the triangles dynamically update to reflect real-time price behavior during the live bar but will repaint until the bar is fully confirmed. Disabling this option prevents the triangles from appearing during the live bar, reducing potential confusion as they may otherwise flash on and off during price updates. This setting ensures users can choose their preferred visualization while maintaining clarity in real-time analysis.
Color Settings : Offers extensive customization for all visual elements, including Broken and Unbroken levels, segment boundaries, and live segments. These settings ensure the indicator can adapt to individual preferences for chart readability.
🖼️ CHART EXAMPLES 🖼️
The following chart examples illustrate different configurations and features of the Non-Psychological Levels indicator. These examples highlight how the indicator’s settings influence the visualization of structural price behavior, helping traders understand its functionality in various scenarios.
Broken and Unbroken Levels : Orange prices are Broken HIghs. Blue prices are Broken Lows. Green and Red are Unbroken.
Boundaries : Enable Boundaries to visualize segments.
High Sensitivity Setting : A high sensitivity setting produces fewer segments and levels, emphasizing broader price ranges and major structural zones. This configuration is better suited for higher timeframes or identifying overarching trends.
Low Sensitivity Setting : A low sensitivity setting results in a greater number of segments and levels, offering a granular view of price structure. This configuration is ideal for analyzing detailed price movements on lower timeframes.
Live Segment with Triangles Enabled : This example shows the live segment box with triangle labels enabled. These triangles update dynamically during the live bar but may repaint until the bar is confirmed, helping traders observe real-time price behavior.
Broken and Unbroken Levels : This example highlights Broken levels (where price has breached structural boundaries and are drawn through subsequent price action) and Unbroken levels (where price has respected structural boundaries). These distinctions visually identify areas of potential support and resistance.
Broken and Unbroken Levels with Projection: All : This example demonstrates the "Project All" feature, where broken and unbroken levels are extended both forward and backward on the chart. This visualization highlights historical and potential future support and resistance zones, helping traders better understand how price interacts with these structural levels over time.
Segment Boxes with Boundaries : Filled boxes around individual segments visually distinguish each price interval, offering clarity in observing structural price transitions.
📊 SUMMARY 📊
The Non-Psychological Levels indicator provides a unique framework for analyzing structural price behavior through the identification of Broken and Unbroken levels. These levels act as a mechanical representation of support and resistance, independent of psychological biases or time-based factors. By focusing purely on price movement within defined segments, the indicator offers a neutral and consistent approach to understanding market dynamics.
This method complements traditional tools by providing an unbiased perspective. When structural levels align with psychological zones—such as round numbers or session-based highs and lows—they reinforce the significance of these areas as key price zones. When they diverge, the indicator introduces an alternative view, prompting further exploration of price behavior. This dual perspective enhances the depth of analysis by combining the mechanical and behavioral aspects of price action.
The Non-Psychological Levels indicator is not designed to generate trading signals or predict future price movements but serves as a visual and educational tool. Its adaptability across all markets and timeframes allows traders to integrate it into their broader strategies. By highlighting structural price dynamics, the indicator offers a fresh perspective on market analysis while remaining compatible with other technical tools.
⚙️ COMPATIBILITY AND LIMITATIONS ⚙️
Asset Compatibility :
The Non-Psychological Levels indicator is compatible with all asset classes, including cryptocurrencies, forex, stocks, and commodities. It can be applied to any chart or timeframe, making it a flexible tool for structural price analysis. Users should adjust the Sensitivity setting to ensure the segmentation aligns with the price behavior of the specific asset being analyzed. For instance, higher sensitivity values are more suitable for assets with large price ranges, while lower values work well for assets with tighter ranges.
Visual Range Dependency :
The indicator is optimized to perform calculations only within the visible range of the chart. This is a significant advantage, as it prevents unnecessary calculations and maintains efficient performance. However, because of this dependency, levels may appear to "recalculate" when the chart is zoomed in or out quickly or shifted abruptly. While this does not affect the integrity of the levels, it may cause a temporary lag as the indicator adjusts to the new visual range.
Persistence of Levels Beyond Visibility :
Even if levels are not visible on the chart due to zoom or scroll settings, they still exist in the background and are recalculated when revisited. This ensures that the structural price analysis remains consistent, regardless of the chart view.
Box Limitations in Pine Script :
The indicator is subject to Pine Script's inherent limitation of 500 boxes. This means that no more than 500 segments or level boxes can be drawn on the chart simultaneously. For most configurations, this limitation is mitigated by focusing on the visual range, but users employing very low sensitivity settings may exceed the limit. In such cases, only the most recent 500 boxes will be displayed, potentially omitting earlier segments.
Lag with Low Sensitivity Settings :
When sensitivity is set to a low value, the indicator creates many more segments, resulting in finer granularity and a higher number of boxes. While this provides detailed structural levels, it may increase the likelihood of exceeding Pine Script’s 500-box limit or cause a temporary lag when rendering a dense set of boxes over a wide visual range. Users should adjust sensitivity to balance detail with performance, especially on assets with high volatility or broad price ranges.
Live Segment Caution :
The live segment box updates in real time to reflect price movements as the segment is still developing. Since the segment high and segment low are not yet finalized, users should interpret this feature as a dynamic visualization of current price behavior rather than a definitive structural analysis. This ensures clarity during ongoing price action while maintaining the integrity of the indicator's framework.
Cross-Market Versatility :
The indicator’s time-agnostic and mechanical design ensures that it functions identically across all markets and timeframes. However, users should consider the unique characteristics of different markets when interpreting the results, as certain assets (e.g., highly volatile cryptocurrencies) may require sensitivity adjustments for optimal segmentation.
Visual Range Dependency: Levels recalculate efficiently within the chart's visible range but may lag temporarily when zooming or scrolling quickly.
These considerations ensure that the Non-Psychological Levels indicator remains robust and versatile while highlighting some inherent limitations of Pine Script and real-time recalculations. Users can mitigate these constraints by carefully adjusting sensitivity and understanding how the visual range dependency affects performance.
⚠️ DISCLAIMER ⚠️
The Non-Psychological Levels indicator is a visual analysis tool and is not designed as a predictive or trading signal indicator. Its primary purpose is to highlight structural price levels, providing an objective framework for understanding support and resistance within mechanically segmented price action.
The indicator operates within the visible range of the chart to ensure efficiency and adaptiveness, but this recalculation should not be interpreted as a forecast of future price behavior. While the structural levels may align with significant price zones in hindsight, they are purely a reflection of observed price dynamics and should not be used as standalone trading signals.
This indicator is intended as an educational and visual aid to complement other analysis methods. Users are encouraged to integrate it into a broader trading strategy and make adjustments to the settings based on their individual needs and market conditions.
🧠 BEYOND THE CODE 🧠
The Non-Psychological Levels indicator, like other xxattaxx indicators , is designed with education and community collaboration in mind. Its open-source nature encourages exploration, experimentation, and the development of new approaches to price analysis. By focusing on structural price behavior rather than psychological or time-based factors, this indicator introduces a fresh perspective for users to study.
Beyond its visual utility, the indicator serves as an educational framework for understanding the concept of non-psychological analysis. It offers traders an opportunity to explore price dynamics in a purely mechanical way, challenging conventional methods and fostering deeper insights into structural behavior. This approach is especially valuable for those interested in exploring new concepts or seeking alternative perspectives on market analysis.
Your comments, suggestions, and discussions are invaluable in shaping the future of this project. We actively encourage your feedback and contributions, which will directly help us refine and improve the Non-Psychological Levels indicator. We look forward to seeing the creative ways in which you use and enhance this tool. MVS
"ha溢价率"に関するスクリプトを検索

Simple Neural Network Transformed RSI [QuantraSystems]Simple Neural Network Transformed RSI
Introduction
The Simple Neural Network Transformed RSI (ɴɴᴛ ʀsɪ) stands out as a formidable tool for traders who specialize in lower timeframe trading.
It is an innovative enhancement of the traditional RSI readings with simple neural network smoothing techniques.
This unique blend results in fairly accurate signals, tailored for swift market movements. The ɴɴᴛ ʀsɪ is particularly resistant to the usual market noise found in lower timeframes, ensuring a clearer view of short-term trends.
Furthermore, its diverse range of visualization options adds versatility, making it a valuable tool for traders seeking to capitalize on short-duration market dynamics.
Legend
In the Image you can see the BTCUSD 1D Chart with the ɴɴᴛ ʀsɪ in Trend Following Mode to display the current trend. This is visualized with the barcoloring.
Its Overbought and Oversold zones start at 50% and end at 100% of the selected Standard Deviation (default σ = 2), which can indicate extremely rare situations which can lead to either a softening momentum in the trend or even a mean reversion situation.
Here you can also see the original Indicator line and the Heikin Ashi transformed Indicator bars - more on that now.
Notes
Quantra Standard Value Contents:
To draw out all the information from the indicator calculation we have added a Heikin-Ashi (HA) Candle Visualization.
This HA transformation smoothens out the indicator values and gives a more informative look into Momentum and Trend of the Indicator itself.
This allows early entries and exits by observing the HA transformed Indicator values.
To diversify, different visualization options are available, either a classic line, HA transformed or Hybrid, which contains both of the previous.
To make Quantra's Indicators as useful and versatile as possible we have created options
to change the barcoloring and thus the derived signal from the indicator based on different modes.
Option to choose different Modes:
Trend Following (Indicator above mid line counts as uptrend, below is downtrend)
Extremities (Everything going beyond the Deviation Bands in a Mean Reversion manner is highlighted)
Candles (Color of HA candles as barcolor)
Reversion (HA ONLY) (Reversion Signals via the triangles if HA candles change state outside of the Deviation Bands)
- Reversion Signals are indicated by the triangles in the Heikin-Ashi or Hybrid visualization when the HA Candles revert
from downwards to upwards or the other way around OUTSIDE of the SD Bands.
Depending on the Indicator they signal OB/OS areas and can either work as high probability entries and exits for Mean Reversion trades or
indicate Momentum slow downs and potential ranges.
Please use another indicator to confirm this.
Case Study
To effectively utilize the NNT-RSI, traders should know their style and familiarize themselves with the available options.
As stated above, you have multiple modes available that you can combine as you need and see fit.
In the given example mostly only the mode was used in an isolated fashion.
Trend Following:
Purely relied on State Change - Midline crossover
Could be combined with Momentum or Reversion analysis for better entries/exits.
Extremities:
Ideal entry/exit is in the accordingly colored OS/OB Area, the Reversion signaled the latest possible entry/exit.
HA Candles:
Specifically applicable for strong trends. Powerful and fast tool.
Can whip if used as sole condition.
Reversions:
Shows the single entry and exit bars which have a positive expected value outcome.
Can also be used as confirmation or as last signal.
Please note that we always advise to find more confluence by additional indicators.
Traders are encouraged to test and determine the most suitable settings for their specific trading strategies and timeframes.
In the showcased trades the default settings were used.
Methodology
The Simple Neural Network Transformed RSI uses a simple neural network logic to process RSI values, smoothing them for more accurate trend analysis.
This is achieved through a linear combination of RSI values over a specified input length, weighted evenly to produce a neural network output.
// Simple neural network logic (linear combination with weighted aggregation)
var float inputs = array.new_float(nnLength, na)
for i = 0 to nnLength - 1
array.set(inputs, i, rsi1 )
nnOutput = 0.0
for i = 0 to nnLength - 1
nnOutput := nnOutput + array.get(inputs, i) * (1 / nnLength)
nnOutput
This output is then compared against a standard or dynamic mean line to generate trend following signals.
Mean = ta.sma(nnOutput, sdLook)
cross = useMean? 50 : Mean
The indicator also incorporates Heikin Ashi candlestick calculations to provide additional insights into market dynamics, such as trend strength and potential reversals.
// Calculate Heikin Ashi representation
ha = ha(
na(nnOutput ) ? nnOutput : nnOutput ,
math.max(nnOutput, nnOutput ),
math.min(nnOutput, nnOutput ),
nnOutput)
Standard deviation bands are used to create dynamic overbought and oversold zones, further enhancing the tool's analytical capabilities.
// Calculate Dynamic OB/OS Zones
stdv_bands(_src, _length, _mult) =>
float basis = ta.sma(_src, _length)
float dev = _mult * ta.stdev(_src, _length)
= stdv_bands(nnOutput, sdLook,sdMult/2)
= stdv_bands(nnOutput, sdLook, sdMult)
The Standard Deviation bands take defined parameters from the user, in this case sigma of ideally between 2 to 3,
to help the indicator detect extremely improbable conditions and thus take an inversely probable signal from it to forward to the user.
The parameter settings and also the visualizations allow for ample customizations by the trader.
For questions or recommendations, please feel free to seek contact in the comments.

Goertzel Cycle Composite Wave [Loxx]As the financial markets become increasingly complex and data-driven, traders and analysts must leverage powerful tools to gain insights and make informed decisions. One such tool is the Goertzel Cycle Composite Wave indicator, a sophisticated technical analysis indicator that helps identify cyclical patterns in financial data. This powerful tool is capable of detecting cyclical patterns in financial data, helping traders to make better predictions and optimize their trading strategies. With its unique combination of mathematical algorithms and advanced charting capabilities, this indicator has the potential to revolutionize the way we approach financial modeling and trading.
*** To decrease the load time of this indicator, only XX many bars back will render to the chart. You can control this value with the setting "Number of Bars to Render". This doesn't have anything to do with repainting or the indicator being endpointed***
█ Brief Overview of the Goertzel Cycle Composite Wave
The Goertzel Cycle Composite Wave is a sophisticated technical analysis tool that utilizes the Goertzel algorithm to analyze and visualize cyclical components within a financial time series. By identifying these cycles and their characteristics, the indicator aims to provide valuable insights into the market's underlying price movements, which could potentially be used for making informed trading decisions.
The Goertzel Cycle Composite Wave is considered a non-repainting and endpointed indicator. This means that once a value has been calculated for a specific bar, that value will not change in subsequent bars, and the indicator is designed to have a clear start and end point. This is an important characteristic for indicators used in technical analysis, as it allows traders to make informed decisions based on historical data without the risk of hindsight bias or future changes in the indicator's values. This means traders can use this indicator trading purposes.
The repainting version of this indicator with forecasting, cycle selection/elimination options, and data output table can be found here:
Goertzel Browser
The primary purpose of this indicator is to:
1. Detect and analyze the dominant cycles present in the price data.
2. Reconstruct and visualize the composite wave based on the detected cycles.
To achieve this, the indicator performs several tasks:
1. Detrending the price data: The indicator preprocesses the price data using various detrending techniques, such as Hodrick-Prescott filters, zero-lag moving averages, and linear regression, to remove the underlying trend and focus on the cyclical components.
2. Applying the Goertzel algorithm: The indicator applies the Goertzel algorithm to the detrended price data, identifying the dominant cycles and their characteristics, such as amplitude, phase, and cycle strength.
3. Constructing the composite wave: The indicator reconstructs the composite wave by combining the detected cycles, either by using a user-defined list of cycles or by selecting the top N cycles based on their amplitude or cycle strength.
4. Visualizing the composite wave: The indicator plots the composite wave, using solid lines for the cycles. The color of the lines indicates whether the wave is increasing or decreasing.
This indicator is a powerful tool that employs the Goertzel algorithm to analyze and visualize the cyclical components within a financial time series. By providing insights into the underlying price movements, the indicator aims to assist traders in making more informed decisions.
█ What is the Goertzel Algorithm?
The Goertzel algorithm, named after Gerald Goertzel, is a digital signal processing technique that is used to efficiently compute individual terms of the Discrete Fourier Transform (DFT). It was first introduced in 1958, and since then, it has found various applications in the fields of engineering, mathematics, and physics.
The Goertzel algorithm is primarily used to detect specific frequency components within a digital signal, making it particularly useful in applications where only a few frequency components are of interest. The algorithm is computationally efficient, as it requires fewer calculations than the Fast Fourier Transform (FFT) when detecting a small number of frequency components. This efficiency makes the Goertzel algorithm a popular choice in applications such as:
1. Telecommunications: The Goertzel algorithm is used for decoding Dual-Tone Multi-Frequency (DTMF) signals, which are the tones generated when pressing buttons on a telephone keypad. By identifying specific frequency components, the algorithm can accurately determine which button has been pressed.
2. Audio processing: The algorithm can be used to detect specific pitches or harmonics in an audio signal, making it useful in applications like pitch detection and tuning musical instruments.
3. Vibration analysis: In the field of mechanical engineering, the Goertzel algorithm can be applied to analyze vibrations in rotating machinery, helping to identify faulty components or signs of wear.
4. Power system analysis: The algorithm can be used to measure harmonic content in power systems, allowing engineers to assess power quality and detect potential issues.
The Goertzel algorithm is used in these applications because it offers several advantages over other methods, such as the FFT:
1. Computational efficiency: The Goertzel algorithm requires fewer calculations when detecting a small number of frequency components, making it more computationally efficient than the FFT in these cases.
2. Real-time analysis: The algorithm can be implemented in a streaming fashion, allowing for real-time analysis of signals, which is crucial in applications like telecommunications and audio processing.
3. Memory efficiency: The Goertzel algorithm requires less memory than the FFT, as it only computes the frequency components of interest.
4. Precision: The algorithm is less susceptible to numerical errors compared to the FFT, ensuring more accurate results in applications where precision is essential.
The Goertzel algorithm is an efficient digital signal processing technique that is primarily used to detect specific frequency components within a signal. Its computational efficiency, real-time capabilities, and precision make it an attractive choice for various applications, including telecommunications, audio processing, vibration analysis, and power system analysis. The algorithm has been widely adopted since its introduction in 1958 and continues to be an essential tool in the fields of engineering, mathematics, and physics.
█ Goertzel Algorithm in Quantitative Finance: In-Depth Analysis and Applications
The Goertzel algorithm, initially designed for signal processing in telecommunications, has gained significant traction in the financial industry due to its efficient frequency detection capabilities. In quantitative finance, the Goertzel algorithm has been utilized for uncovering hidden market cycles, developing data-driven trading strategies, and optimizing risk management. This section delves deeper into the applications of the Goertzel algorithm in finance, particularly within the context of quantitative trading and analysis.
Unveiling Hidden Market Cycles:
Market cycles are prevalent in financial markets and arise from various factors, such as economic conditions, investor psychology, and market participant behavior. The Goertzel algorithm's ability to detect and isolate specific frequencies in price data helps trader analysts identify hidden market cycles that may otherwise go unnoticed. By examining the amplitude, phase, and periodicity of each cycle, traders can better understand the underlying market structure and dynamics, enabling them to develop more informed and effective trading strategies.
Developing Quantitative Trading Strategies:
The Goertzel algorithm's versatility allows traders to incorporate its insights into a wide range of trading strategies. By identifying the dominant market cycles in a financial instrument's price data, traders can create data-driven strategies that capitalize on the cyclical nature of markets.
For instance, a trader may develop a mean-reversion strategy that takes advantage of the identified cycles. By establishing positions when the price deviates from the predicted cycle, the trader can profit from the subsequent reversion to the cycle's mean. Similarly, a momentum-based strategy could be designed to exploit the persistence of a dominant cycle by entering positions that align with the cycle's direction.
Enhancing Risk Management:
The Goertzel algorithm plays a vital role in risk management for quantitative strategies. By analyzing the cyclical components of a financial instrument's price data, traders can gain insights into the potential risks associated with their trading strategies.
By monitoring the amplitude and phase of dominant cycles, a trader can detect changes in market dynamics that may pose risks to their positions. For example, a sudden increase in amplitude may indicate heightened volatility, prompting the trader to adjust position sizing or employ hedging techniques to protect their portfolio. Additionally, changes in phase alignment could signal a potential shift in market sentiment, necessitating adjustments to the trading strategy.
Expanding Quantitative Toolkits:
Traders can augment the Goertzel algorithm's insights by combining it with other quantitative techniques, creating a more comprehensive and sophisticated analysis framework. For example, machine learning algorithms, such as neural networks or support vector machines, could be trained on features extracted from the Goertzel algorithm to predict future price movements more accurately.
Furthermore, the Goertzel algorithm can be integrated with other technical analysis tools, such as moving averages or oscillators, to enhance their effectiveness. By applying these tools to the identified cycles, traders can generate more robust and reliable trading signals.
The Goertzel algorithm offers invaluable benefits to quantitative finance practitioners by uncovering hidden market cycles, aiding in the development of data-driven trading strategies, and improving risk management. By leveraging the insights provided by the Goertzel algorithm and integrating it with other quantitative techniques, traders can gain a deeper understanding of market dynamics and devise more effective trading strategies.
█ Indicator Inputs
src: This is the source data for the analysis, typically the closing price of the financial instrument.
detrendornot: This input determines the method used for detrending the source data. Detrending is the process of removing the underlying trend from the data to focus on the cyclical components.
The available options are:
hpsmthdt: Detrend using Hodrick-Prescott filter centered moving average.
zlagsmthdt: Detrend using zero-lag moving average centered moving average.
logZlagRegression: Detrend using logarithmic zero-lag linear regression.
hpsmth: Detrend using Hodrick-Prescott filter.
zlagsmth: Detrend using zero-lag moving average.
DT_HPper1 and DT_HPper2: These inputs define the period range for the Hodrick-Prescott filter centered moving average when detrendornot is set to hpsmthdt.
DT_ZLper1 and DT_ZLper2: These inputs define the period range for the zero-lag moving average centered moving average when detrendornot is set to zlagsmthdt.
DT_RegZLsmoothPer: This input defines the period for the zero-lag moving average used in logarithmic zero-lag linear regression when detrendornot is set to logZlagRegression.
HPsmoothPer: This input defines the period for the Hodrick-Prescott filter when detrendornot is set to hpsmth.
ZLMAsmoothPer: This input defines the period for the zero-lag moving average when detrendornot is set to zlagsmth.
MaxPer: This input sets the maximum period for the Goertzel algorithm to search for cycles.
squaredAmp: This boolean input determines whether the amplitude should be squared in the Goertzel algorithm.
useAddition: This boolean input determines whether the Goertzel algorithm should use addition for combining the cycles.
useCosine: This boolean input determines whether the Goertzel algorithm should use cosine waves instead of sine waves.
UseCycleStrength: This boolean input determines whether the Goertzel algorithm should compute the cycle strength, which is a normalized measure of the cycle's amplitude.
WindowSizePast: These inputs define the window size for the composite wave.
FilterBartels: This boolean input determines whether Bartel's test should be applied to filter out non-significant cycles.
BartNoCycles: This input sets the number of cycles to be used in Bartel's test.
BartSmoothPer: This input sets the period for the moving average used in Bartel's test.
BartSigLimit: This input sets the significance limit for Bartel's test, below which cycles are considered insignificant.
SortBartels: This boolean input determines whether the cycles should be sorted by their Bartel's test results.
StartAtCycle: This input determines the starting index for selecting the top N cycles when UseCycleList is set to false. This allows you to skip a certain number of cycles from the top before selecting the desired number of cycles.
UseTopCycles: This input sets the number of top cycles to use for constructing the composite wave when UseCycleList is set to false. The cycles are ranked based on their amplitudes or cycle strengths, depending on the UseCycleStrength input.
SubtractNoise: This boolean input determines whether to subtract the noise (remaining cycles) from the composite wave. If set to true, the composite wave will only include the top N cycles specified by UseTopCycles.
█ Exploring Auxiliary Functions
The following functions demonstrate advanced techniques for analyzing financial markets, including zero-lag moving averages, Bartels probability, detrending, and Hodrick-Prescott filtering. This section examines each function in detail, explaining their purpose, methodology, and applications in finance. We will examine how each function contributes to the overall performance and effectiveness of the indicator and how they work together to create a powerful analytical tool.
Zero-Lag Moving Average:
The zero-lag moving average function is designed to minimize the lag typically associated with moving averages. This is achieved through a two-step weighted linear regression process that emphasizes more recent data points. The function calculates a linearly weighted moving average (LWMA) on the input data and then applies another LWMA on the result. By doing this, the function creates a moving average that closely follows the price action, reducing the lag and improving the responsiveness of the indicator.
The zero-lag moving average function is used in the indicator to provide a responsive, low-lag smoothing of the input data. This function helps reduce the noise and fluctuations in the data, making it easier to identify and analyze underlying trends and patterns. By minimizing the lag associated with traditional moving averages, this function allows the indicator to react more quickly to changes in market conditions, providing timely signals and improving the overall effectiveness of the indicator.
Bartels Probability:
The Bartels probability function calculates the probability of a given cycle being significant in a time series. It uses a mathematical test called the Bartels test to assess the significance of cycles detected in the data. The function calculates coefficients for each detected cycle and computes an average amplitude and an expected amplitude. By comparing these values, the Bartels probability is derived, indicating the likelihood of a cycle's significance. This information can help in identifying and analyzing dominant cycles in financial markets.
The Bartels probability function is incorporated into the indicator to assess the significance of detected cycles in the input data. By calculating the Bartels probability for each cycle, the indicator can prioritize the most significant cycles and focus on the market dynamics that are most relevant to the current trading environment. This function enhances the indicator's ability to identify dominant market cycles, improving its predictive power and aiding in the development of effective trading strategies.
Detrend Logarithmic Zero-Lag Regression:
The detrend logarithmic zero-lag regression function is used for detrending data while minimizing lag. It combines a zero-lag moving average with a linear regression detrending method. The function first calculates the zero-lag moving average of the logarithm of input data and then applies a linear regression to remove the trend. By detrending the data, the function isolates the cyclical components, making it easier to analyze and interpret the underlying market dynamics.
The detrend logarithmic zero-lag regression function is used in the indicator to isolate the cyclical components of the input data. By detrending the data, the function enables the indicator to focus on the cyclical movements in the market, making it easier to analyze and interpret market dynamics. This function is essential for identifying cyclical patterns and understanding the interactions between different market cycles, which can inform trading decisions and enhance overall market understanding.
Bartels Cycle Significance Test:
The Bartels cycle significance test is a function that combines the Bartels probability function and the detrend logarithmic zero-lag regression function to assess the significance of detected cycles. The function calculates the Bartels probability for each cycle and stores the results in an array. By analyzing the probability values, traders and analysts can identify the most significant cycles in the data, which can be used to develop trading strategies and improve market understanding.
The Bartels cycle significance test function is integrated into the indicator to provide a comprehensive analysis of the significance of detected cycles. By combining the Bartels probability function and the detrend logarithmic zero-lag regression function, this test evaluates the significance of each cycle and stores the results in an array. The indicator can then use this information to prioritize the most significant cycles and focus on the most relevant market dynamics. This function enhances the indicator's ability to identify and analyze dominant market cycles, providing valuable insights for trading and market analysis.
Hodrick-Prescott Filter:
The Hodrick-Prescott filter is a popular technique used to separate the trend and cyclical components of a time series. The function applies a smoothing parameter to the input data and calculates a smoothed series using a two-sided filter. This smoothed series represents the trend component, which can be subtracted from the original data to obtain the cyclical component. The Hodrick-Prescott filter is commonly used in economics and finance to analyze economic data and financial market trends.
The Hodrick-Prescott filter is incorporated into the indicator to separate the trend and cyclical components of the input data. By applying the filter to the data, the indicator can isolate the trend component, which can be used to analyze long-term market trends and inform trading decisions. Additionally, the cyclical component can be used to identify shorter-term market dynamics and provide insights into potential trading opportunities. The inclusion of the Hodrick-Prescott filter adds another layer of analysis to the indicator, making it more versatile and comprehensive.
Detrending Options: Detrend Centered Moving Average:
The detrend centered moving average function provides different detrending methods, including the Hodrick-Prescott filter and the zero-lag moving average, based on the selected detrending method. The function calculates two sets of smoothed values using the chosen method and subtracts one set from the other to obtain a detrended series. By offering multiple detrending options, this function allows traders and analysts to select the most appropriate method for their specific needs and preferences.
The detrend centered moving average function is integrated into the indicator to provide users with multiple detrending options, including the Hodrick-Prescott filter and the zero-lag moving average. By offering multiple detrending methods, the indicator allows users to customize the analysis to their specific needs and preferences, enhancing the indicator's overall utility and adaptability. This function ensures that the indicator can cater to a wide range of trading styles and objectives, making it a valuable tool for a diverse group of market participants.
The auxiliary functions functions discussed in this section demonstrate the power and versatility of mathematical techniques in analyzing financial markets. By understanding and implementing these functions, traders and analysts can gain valuable insights into market dynamics, improve their trading strategies, and make more informed decisions. The combination of zero-lag moving averages, Bartels probability, detrending methods, and the Hodrick-Prescott filter provides a comprehensive toolkit for analyzing and interpreting financial data. The integration of advanced functions in a financial indicator creates a powerful and versatile analytical tool that can provide valuable insights into financial markets. By combining the zero-lag moving average,
█ In-Depth Analysis of the Goertzel Cycle Composite Wave Code
The Goertzel Cycle Composite Wave code is an implementation of the Goertzel Algorithm, an efficient technique to perform spectral analysis on a signal. The code is designed to detect and analyze dominant cycles within a given financial market data set. This section will provide an extremely detailed explanation of the code, its structure, functions, and intended purpose.
Function signature and input parameters:
The Goertzel Cycle Composite Wave function accepts numerous input parameters for customization, including source data (src), the current bar (forBar), sample size (samplesize), period (per), squared amplitude flag (squaredAmp), addition flag (useAddition), cosine flag (useCosine), cycle strength flag (UseCycleStrength), past sizes (WindowSizePast), Bartels filter flag (FilterBartels), Bartels-related parameters (BartNoCycles, BartSmoothPer, BartSigLimit), sorting flag (SortBartels), and output buffers (goeWorkPast, cyclebuffer, amplitudebuffer, phasebuffer, cycleBartelsBuffer).
Initializing variables and arrays:
The code initializes several float arrays (goeWork1, goeWork2, goeWork3, goeWork4) with the same length as twice the period (2 * per). These arrays store intermediate results during the execution of the algorithm.
Preprocessing input data:
The input data (src) undergoes preprocessing to remove linear trends. This step enhances the algorithm's ability to focus on cyclical components in the data. The linear trend is calculated by finding the slope between the first and last values of the input data within the sample.
Iterative calculation of Goertzel coefficients:
The core of the Goertzel Cycle Composite Wave algorithm lies in the iterative calculation of Goertzel coefficients for each frequency bin. These coefficients represent the spectral content of the input data at different frequencies. The code iterates through the range of frequencies, calculating the Goertzel coefficients using a nested loop structure.
Cycle strength computation:
The code calculates the cycle strength based on the Goertzel coefficients. This is an optional step, controlled by the UseCycleStrength flag. The cycle strength provides information on the relative influence of each cycle on the data per bar, considering both amplitude and cycle length. The algorithm computes the cycle strength either by squaring the amplitude (controlled by squaredAmp flag) or using the actual amplitude values.
Phase calculation:
The Goertzel Cycle Composite Wave code computes the phase of each cycle, which represents the position of the cycle within the input data. The phase is calculated using the arctangent function (math.atan) based on the ratio of the imaginary and real components of the Goertzel coefficients.
Peak detection and cycle extraction:
The algorithm performs peak detection on the computed amplitudes or cycle strengths to identify dominant cycles. It stores the detected cycles in the cyclebuffer array, along with their corresponding amplitudes and phases in the amplitudebuffer and phasebuffer arrays, respectively.
Sorting cycles by amplitude or cycle strength:
The code sorts the detected cycles based on their amplitude or cycle strength in descending order. This allows the algorithm to prioritize cycles with the most significant impact on the input data.
Bartels cycle significance test:
If the FilterBartels flag is set, the code performs a Bartels cycle significance test on the detected cycles. This test determines the statistical significance of each cycle and filters out the insignificant cycles. The significant cycles are stored in the cycleBartelsBuffer array. If the SortBartels flag is set, the code sorts the significant cycles based on their Bartels significance values.
Waveform calculation:
The Goertzel Cycle Composite Wave code calculates the waveform of the significant cycles for specified time windows. The windows are defined by the WindowSizePast parameters, respectively. The algorithm uses either cosine or sine functions (controlled by the useCosine flag) to calculate the waveforms for each cycle. The useAddition flag determines whether the waveforms should be added or subtracted.
Storing waveforms in a matrix:
The calculated waveforms for the cycle is stored in the matrix - goeWorkPast. This matrix holds the waveforms for the specified time windows. Each row in the matrix represents a time window position, and each column corresponds to a cycle.
Returning the number of cycles:
The Goertzel Cycle Composite Wave function returns the total number of detected cycles (number_of_cycles) after processing the input data. This information can be used to further analyze the results or to visualize the detected cycles.
The Goertzel Cycle Composite Wave code is a comprehensive implementation of the Goertzel Algorithm, specifically designed for detecting and analyzing dominant cycles within financial market data. The code offers a high level of customization, allowing users to fine-tune the algorithm based on their specific needs. The Goertzel Cycle Composite Wave's combination of preprocessing, iterative calculations, cycle extraction, sorting, significance testing, and waveform calculation makes it a powerful tool for understanding cyclical components in financial data.
█ Generating and Visualizing Composite Waveform
The indicator calculates and visualizes the composite waveform for specified time windows based on the detected cycles. Here's a detailed explanation of this process:
Updating WindowSizePast:
The WindowSizePast is updated to ensure they are at least twice the MaxPer (maximum period).
Initializing matrices and arrays:
The matrix goeWorkPast is initialized to store the Goertzel results for specified time windows. Multiple arrays are also initialized to store cycle, amplitude, phase, and Bartels information.
Preparing the source data (srcVal) array:
The source data is copied into an array, srcVal, and detrended using one of the selected methods (hpsmthdt, zlagsmthdt, logZlagRegression, hpsmth, or zlagsmth).
Goertzel function call:
The Goertzel function is called to analyze the detrended source data and extract cycle information. The output, number_of_cycles, contains the number of detected cycles.
Initializing arrays for waveforms:
The goertzel array is initialized to store the endpoint Goertzel.
Calculating composite waveform (goertzel array):
The composite waveform is calculated by summing the selected cycles (either from the user-defined cycle list or the top cycles) and optionally subtracting the noise component.
Drawing composite waveform (pvlines):
The composite waveform is drawn on the chart using solid lines. The color of the lines is determined by the direction of the waveform (green for upward, red for downward).
To summarize, this indicator generates a composite waveform based on the detected cycles in the financial data. It calculates the composite waveforms and visualizes them on the chart using colored lines.
█ Enhancing the Goertzel Algorithm-Based Script for Financial Modeling and Trading
The Goertzel algorithm-based script for detecting dominant cycles in financial data is a powerful tool for financial modeling and trading. It provides valuable insights into the past behavior of these cycles. However, as with any algorithm, there is always room for improvement. This section discusses potential enhancements to the existing script to make it even more robust and versatile for financial modeling, general trading, advanced trading, and high-frequency finance trading.
Enhancements for Financial Modeling
Data preprocessing: One way to improve the script's performance for financial modeling is to introduce more advanced data preprocessing techniques. This could include removing outliers, handling missing data, and normalizing the data to ensure consistent and accurate results.
Additional detrending and smoothing methods: Incorporating more sophisticated detrending and smoothing techniques, such as wavelet transform or empirical mode decomposition, can help improve the script's ability to accurately identify cycles and trends in the data.
Machine learning integration: Integrating machine learning techniques, such as artificial neural networks or support vector machines, can help enhance the script's predictive capabilities, leading to more accurate financial models.
Enhancements for General and Advanced Trading
Customizable indicator integration: Allowing users to integrate their own technical indicators can help improve the script's effectiveness for both general and advanced trading. By enabling the combination of the dominant cycle information with other technical analysis tools, traders can develop more comprehensive trading strategies.
Risk management and position sizing: Incorporating risk management and position sizing functionality into the script can help traders better manage their trades and control potential losses. This can be achieved by calculating the optimal position size based on the user's risk tolerance and account size.
Multi-timeframe analysis: Enhancing the script to perform multi-timeframe analysis can provide traders with a more holistic view of market trends and cycles. By identifying dominant cycles on different timeframes, traders can gain insights into the potential confluence of cycles and make better-informed trading decisions.
Enhancements for High-Frequency Finance Trading
Algorithm optimization: To ensure the script's suitability for high-frequency finance trading, optimizing the algorithm for faster execution is crucial. This can be achieved by employing efficient data structures and refining the calculation methods to minimize computational complexity.
Real-time data streaming: Integrating real-time data streaming capabilities into the script can help high-frequency traders react to market changes more quickly. By continuously updating the cycle information based on real-time market data, traders can adapt their strategies accordingly and capitalize on short-term market fluctuations.
Order execution and trade management: To fully leverage the script's capabilities for high-frequency trading, implementing functionality for automated order execution and trade management is essential. This can include features such as stop-loss and take-profit orders, trailing stops, and automated trade exit strategies.
While the existing Goertzel algorithm-based script is a valuable tool for detecting dominant cycles in financial data, there are several potential enhancements that can make it even more powerful for financial modeling, general trading, advanced trading, and high-frequency finance trading. By incorporating these improvements, the script can become a more versatile and effective tool for traders and financial analysts alike.
█ Understanding the Limitations of the Goertzel Algorithm
While the Goertzel algorithm-based script for detecting dominant cycles in financial data provides valuable insights, it is important to be aware of its limitations and drawbacks. Some of the key drawbacks of this indicator are:
Lagging nature:
As with many other technical indicators, the Goertzel algorithm-based script can suffer from lagging effects, meaning that it may not immediately react to real-time market changes. This lag can lead to late entries and exits, potentially resulting in reduced profitability or increased losses.
Parameter sensitivity:
The performance of the script can be sensitive to the chosen parameters, such as the detrending methods, smoothing techniques, and cycle detection settings. Improper parameter selection may lead to inaccurate cycle detection or increased false signals, which can negatively impact trading performance.
Complexity:
The Goertzel algorithm itself is relatively complex, making it difficult for novice traders or those unfamiliar with the concept of cycle analysis to fully understand and effectively utilize the script. This complexity can also make it challenging to optimize the script for specific trading styles or market conditions.
Overfitting risk:
As with any data-driven approach, there is a risk of overfitting when using the Goertzel algorithm-based script. Overfitting occurs when a model becomes too specific to the historical data it was trained on, leading to poor performance on new, unseen data. This can result in misleading signals and reduced trading performance.
Limited applicability:
The Goertzel algorithm-based script may not be suitable for all markets, trading styles, or timeframes. Its effectiveness in detecting cycles may be limited in certain market conditions, such as during periods of extreme volatility or low liquidity.
While the Goertzel algorithm-based script offers valuable insights into dominant cycles in financial data, it is essential to consider its drawbacks and limitations when incorporating it into a trading strategy. Traders should always use the script in conjunction with other technical and fundamental analysis tools, as well as proper risk management, to make well-informed trading decisions.
█ Interpreting Results
The Goertzel Cycle Composite Wave indicator can be interpreted by analyzing the plotted lines. The indicator plots two lines: composite waves. The composite wave represents the composite wave of the price data.
The composite wave line displays a solid line, with green indicating a bullish trend and red indicating a bearish trend.
Interpreting the Goertzel Cycle Composite Wave indicator involves identifying the trend of the composite wave lines and matching them with the corresponding bullish or bearish color.
█ Conclusion
The Goertzel Cycle Composite Wave indicator is a powerful tool for identifying and analyzing cyclical patterns in financial markets. Its ability to detect multiple cycles of varying frequencies and strengths make it a valuable addition to any trader's technical analysis toolkit. However, it is important to keep in mind that the Goertzel Cycle Composite Wave indicator should be used in conjunction with other technical analysis tools and fundamental analysis to achieve the best results. With continued refinement and development, the Goertzel Cycle Composite Wave indicator has the potential to become a highly effective tool for financial modeling, general trading, advanced trading, and high-frequency finance trading. Its accuracy and versatility make it a promising candidate for further research and development.
█ Footnotes
What is the Bartels Test for Cycle Significance?
The Bartels Cycle Significance Test is a statistical method that determines whether the peaks and troughs of a time series are statistically significant. The test is named after its inventor, George Bartels, who developed it in the mid-20th century.
The Bartels test is designed to analyze the cyclical components of a time series, which can help traders and analysts identify trends and cycles in financial markets. The test calculates a Bartels statistic, which measures the degree of non-randomness or autocorrelation in the time series.
The Bartels statistic is calculated by first splitting the time series into two halves and calculating the range of the peaks and troughs in each half. The test then compares these ranges using a t-test, which measures the significance of the difference between the two ranges.
If the Bartels statistic is greater than a critical value, it indicates that the peaks and troughs in the time series are non-random and that there is a significant cyclical component to the data. Conversely, if the Bartels statistic is less than the critical value, it suggests that the peaks and troughs are random and that there is no significant cyclical component.
The Bartels Cycle Significance Test is particularly useful in financial analysis because it can help traders and analysts identify significant cycles in asset prices, which can in turn inform investment decisions. However, it is important to note that the test is not perfect and can produce false signals in certain situations, particularly in noisy or volatile markets. Therefore, it is always recommended to use the test in conjunction with other technical and fundamental indicators to confirm trends and cycles.
Deep-dive into the Hodrick-Prescott Fitler
The Hodrick-Prescott (HP) filter is a statistical tool used in economics and finance to separate a time series into two components: a trend component and a cyclical component. It is a powerful tool for identifying long-term trends in economic and financial data and is widely used by economists, central banks, and financial institutions around the world.
The HP filter was first introduced in the 1990s by economists Robert Hodrick and Edward Prescott. It is a simple, two-parameter filter that separates a time series into a trend component and a cyclical component. The trend component represents the long-term behavior of the data, while the cyclical component captures the shorter-term fluctuations around the trend.
The HP filter works by minimizing the following objective function:
Minimize: (Sum of Squared Deviations) + λ (Sum of Squared Second Differences)
Where:
1. The first term represents the deviation of the data from the trend.
2. The second term represents the smoothness of the trend.
3. λ is a smoothing parameter that determines the degree of smoothness of the trend.
The smoothing parameter λ is typically set to a value between 100 and 1600, depending on the frequency of the data. Higher values of λ lead to a smoother trend, while lower values lead to a more volatile trend.
The HP filter has several advantages over other smoothing techniques. It is a non-parametric method, meaning that it does not make any assumptions about the underlying distribution of the data. It also allows for easy comparison of trends across different time series and can be used with data of any frequency.
However, the HP filter also has some limitations. It assumes that the trend is a smooth function, which may not be the case in some situations. It can also be sensitive to changes in the smoothing parameter λ, which may result in different trends for the same data. Additionally, the filter may produce unrealistic trends for very short time series.
Despite these limitations, the HP filter remains a valuable tool for analyzing economic and financial data. It is widely used by central banks and financial institutions to monitor long-term trends in the economy, and it can be used to identify turning points in the business cycle. The filter can also be used to analyze asset prices, exchange rates, and other financial variables.
The Hodrick-Prescott filter is a powerful tool for analyzing economic and financial data. It separates a time series into a trend component and a cyclical component, allowing for easy identification of long-term trends and turning points in the business cycle. While it has some limitations, it remains a valuable tool for economists, central banks, and financial institutions around the world.

Goertzel Browser [Loxx]As the financial markets become increasingly complex and data-driven, traders and analysts must leverage powerful tools to gain insights and make informed decisions. One such tool is the Goertzel Browser indicator, a sophisticated technical analysis indicator that helps identify cyclical patterns in financial data. This powerful tool is capable of detecting cyclical patterns in financial data, helping traders to make better predictions and optimize their trading strategies. With its unique combination of mathematical algorithms and advanced charting capabilities, this indicator has the potential to revolutionize the way we approach financial modeling and trading.
█ Brief Overview of the Goertzel Browser
The Goertzel Browser is a sophisticated technical analysis tool that utilizes the Goertzel algorithm to analyze and visualize cyclical components within a financial time series. By identifying these cycles and their characteristics, the indicator aims to provide valuable insights into the market's underlying price movements, which could potentially be used for making informed trading decisions.
The primary purpose of this indicator is to:
1. Detect and analyze the dominant cycles present in the price data.
2. Reconstruct and visualize the composite wave based on the detected cycles.
3. Project the composite wave into the future, providing a potential roadmap for upcoming price movements.
To achieve this, the indicator performs several tasks:
1. Detrending the price data: The indicator preprocesses the price data using various detrending techniques, such as Hodrick-Prescott filters, zero-lag moving averages, and linear regression, to remove the underlying trend and focus on the cyclical components.
2. Applying the Goertzel algorithm: The indicator applies the Goertzel algorithm to the detrended price data, identifying the dominant cycles and their characteristics, such as amplitude, phase, and cycle strength.
3. Constructing the composite wave: The indicator reconstructs the composite wave by combining the detected cycles, either by using a user-defined list of cycles or by selecting the top N cycles based on their amplitude or cycle strength.
4. Visualizing the composite wave: The indicator plots the composite wave, using solid lines for the past and dotted lines for the future projections. The color of the lines indicates whether the wave is increasing or decreasing.
5. Displaying cycle information: The indicator provides a table that displays detailed information about the detected cycles, including their rank, period, Bartel's test results, amplitude, and phase.
This indicator is a powerful tool that employs the Goertzel algorithm to analyze and visualize the cyclical components within a financial time series. By providing insights into the underlying price movements and their potential future trajectory, the indicator aims to assist traders in making more informed decisions.
█ What is the Goertzel Algorithm?
The Goertzel algorithm, named after Gerald Goertzel, is a digital signal processing technique that is used to efficiently compute individual terms of the Discrete Fourier Transform (DFT). It was first introduced in 1958, and since then, it has found various applications in the fields of engineering, mathematics, and physics.
The Goertzel algorithm is primarily used to detect specific frequency components within a digital signal, making it particularly useful in applications where only a few frequency components are of interest. The algorithm is computationally efficient, as it requires fewer calculations than the Fast Fourier Transform (FFT) when detecting a small number of frequency components. This efficiency makes the Goertzel algorithm a popular choice in applications such as:
1. Telecommunications: The Goertzel algorithm is used for decoding Dual-Tone Multi-Frequency (DTMF) signals, which are the tones generated when pressing buttons on a telephone keypad. By identifying specific frequency components, the algorithm can accurately determine which button has been pressed.
2. Audio processing: The algorithm can be used to detect specific pitches or harmonics in an audio signal, making it useful in applications like pitch detection and tuning musical instruments.
3. Vibration analysis: In the field of mechanical engineering, the Goertzel algorithm can be applied to analyze vibrations in rotating machinery, helping to identify faulty components or signs of wear.
4. Power system analysis: The algorithm can be used to measure harmonic content in power systems, allowing engineers to assess power quality and detect potential issues.
The Goertzel algorithm is used in these applications because it offers several advantages over other methods, such as the FFT:
1. Computational efficiency: The Goertzel algorithm requires fewer calculations when detecting a small number of frequency components, making it more computationally efficient than the FFT in these cases.
2. Real-time analysis: The algorithm can be implemented in a streaming fashion, allowing for real-time analysis of signals, which is crucial in applications like telecommunications and audio processing.
3. Memory efficiency: The Goertzel algorithm requires less memory than the FFT, as it only computes the frequency components of interest.
4. Precision: The algorithm is less susceptible to numerical errors compared to the FFT, ensuring more accurate results in applications where precision is essential.
The Goertzel algorithm is an efficient digital signal processing technique that is primarily used to detect specific frequency components within a signal. Its computational efficiency, real-time capabilities, and precision make it an attractive choice for various applications, including telecommunications, audio processing, vibration analysis, and power system analysis. The algorithm has been widely adopted since its introduction in 1958 and continues to be an essential tool in the fields of engineering, mathematics, and physics.
█ Goertzel Algorithm in Quantitative Finance: In-Depth Analysis and Applications
The Goertzel algorithm, initially designed for signal processing in telecommunications, has gained significant traction in the financial industry due to its efficient frequency detection capabilities. In quantitative finance, the Goertzel algorithm has been utilized for uncovering hidden market cycles, developing data-driven trading strategies, and optimizing risk management. This section delves deeper into the applications of the Goertzel algorithm in finance, particularly within the context of quantitative trading and analysis.
Unveiling Hidden Market Cycles:
Market cycles are prevalent in financial markets and arise from various factors, such as economic conditions, investor psychology, and market participant behavior. The Goertzel algorithm's ability to detect and isolate specific frequencies in price data helps trader analysts identify hidden market cycles that may otherwise go unnoticed. By examining the amplitude, phase, and periodicity of each cycle, traders can better understand the underlying market structure and dynamics, enabling them to develop more informed and effective trading strategies.
Developing Quantitative Trading Strategies:
The Goertzel algorithm's versatility allows traders to incorporate its insights into a wide range of trading strategies. By identifying the dominant market cycles in a financial instrument's price data, traders can create data-driven strategies that capitalize on the cyclical nature of markets.
For instance, a trader may develop a mean-reversion strategy that takes advantage of the identified cycles. By establishing positions when the price deviates from the predicted cycle, the trader can profit from the subsequent reversion to the cycle's mean. Similarly, a momentum-based strategy could be designed to exploit the persistence of a dominant cycle by entering positions that align with the cycle's direction.
Enhancing Risk Management:
The Goertzel algorithm plays a vital role in risk management for quantitative strategies. By analyzing the cyclical components of a financial instrument's price data, traders can gain insights into the potential risks associated with their trading strategies.
By monitoring the amplitude and phase of dominant cycles, a trader can detect changes in market dynamics that may pose risks to their positions. For example, a sudden increase in amplitude may indicate heightened volatility, prompting the trader to adjust position sizing or employ hedging techniques to protect their portfolio. Additionally, changes in phase alignment could signal a potential shift in market sentiment, necessitating adjustments to the trading strategy.
Expanding Quantitative Toolkits:
Traders can augment the Goertzel algorithm's insights by combining it with other quantitative techniques, creating a more comprehensive and sophisticated analysis framework. For example, machine learning algorithms, such as neural networks or support vector machines, could be trained on features extracted from the Goertzel algorithm to predict future price movements more accurately.
Furthermore, the Goertzel algorithm can be integrated with other technical analysis tools, such as moving averages or oscillators, to enhance their effectiveness. By applying these tools to the identified cycles, traders can generate more robust and reliable trading signals.
The Goertzel algorithm offers invaluable benefits to quantitative finance practitioners by uncovering hidden market cycles, aiding in the development of data-driven trading strategies, and improving risk management. By leveraging the insights provided by the Goertzel algorithm and integrating it with other quantitative techniques, traders can gain a deeper understanding of market dynamics and devise more effective trading strategies.
█ Indicator Inputs
src: This is the source data for the analysis, typically the closing price of the financial instrument.
detrendornot: This input determines the method used for detrending the source data. Detrending is the process of removing the underlying trend from the data to focus on the cyclical components.
The available options are:
hpsmthdt: Detrend using Hodrick-Prescott filter centered moving average.
zlagsmthdt: Detrend using zero-lag moving average centered moving average.
logZlagRegression: Detrend using logarithmic zero-lag linear regression.
hpsmth: Detrend using Hodrick-Prescott filter.
zlagsmth: Detrend using zero-lag moving average.
DT_HPper1 and DT_HPper2: These inputs define the period range for the Hodrick-Prescott filter centered moving average when detrendornot is set to hpsmthdt.
DT_ZLper1 and DT_ZLper2: These inputs define the period range for the zero-lag moving average centered moving average when detrendornot is set to zlagsmthdt.
DT_RegZLsmoothPer: This input defines the period for the zero-lag moving average used in logarithmic zero-lag linear regression when detrendornot is set to logZlagRegression.
HPsmoothPer: This input defines the period for the Hodrick-Prescott filter when detrendornot is set to hpsmth.
ZLMAsmoothPer: This input defines the period for the zero-lag moving average when detrendornot is set to zlagsmth.
MaxPer: This input sets the maximum period for the Goertzel algorithm to search for cycles.
squaredAmp: This boolean input determines whether the amplitude should be squared in the Goertzel algorithm.
useAddition: This boolean input determines whether the Goertzel algorithm should use addition for combining the cycles.
useCosine: This boolean input determines whether the Goertzel algorithm should use cosine waves instead of sine waves.
UseCycleStrength: This boolean input determines whether the Goertzel algorithm should compute the cycle strength, which is a normalized measure of the cycle's amplitude.
WindowSizePast and WindowSizeFuture: These inputs define the window size for past and future projections of the composite wave.
FilterBartels: This boolean input determines whether Bartel's test should be applied to filter out non-significant cycles.
BartNoCycles: This input sets the number of cycles to be used in Bartel's test.
BartSmoothPer: This input sets the period for the moving average used in Bartel's test.
BartSigLimit: This input sets the significance limit for Bartel's test, below which cycles are considered insignificant.
SortBartels: This boolean input determines whether the cycles should be sorted by their Bartel's test results.
UseCycleList: This boolean input determines whether a user-defined list of cycles should be used for constructing the composite wave. If set to false, the top N cycles will be used.
Cycle1, Cycle2, Cycle3, Cycle4, and Cycle5: These inputs define the user-defined list of cycles when 'UseCycleList' is set to true. If using a user-defined list, each of these inputs represents the period of a specific cycle to include in the composite wave.
StartAtCycle: This input determines the starting index for selecting the top N cycles when UseCycleList is set to false. This allows you to skip a certain number of cycles from the top before selecting the desired number of cycles.
UseTopCycles: This input sets the number of top cycles to use for constructing the composite wave when UseCycleList is set to false. The cycles are ranked based on their amplitudes or cycle strengths, depending on the UseCycleStrength input.
SubtractNoise: This boolean input determines whether to subtract the noise (remaining cycles) from the composite wave. If set to true, the composite wave will only include the top N cycles specified by UseTopCycles.
█ Exploring Auxiliary Functions
The following functions demonstrate advanced techniques for analyzing financial markets, including zero-lag moving averages, Bartels probability, detrending, and Hodrick-Prescott filtering. This section examines each function in detail, explaining their purpose, methodology, and applications in finance. We will examine how each function contributes to the overall performance and effectiveness of the indicator and how they work together to create a powerful analytical tool.
Zero-Lag Moving Average:
The zero-lag moving average function is designed to minimize the lag typically associated with moving averages. This is achieved through a two-step weighted linear regression process that emphasizes more recent data points. The function calculates a linearly weighted moving average (LWMA) on the input data and then applies another LWMA on the result. By doing this, the function creates a moving average that closely follows the price action, reducing the lag and improving the responsiveness of the indicator.
The zero-lag moving average function is used in the indicator to provide a responsive, low-lag smoothing of the input data. This function helps reduce the noise and fluctuations in the data, making it easier to identify and analyze underlying trends and patterns. By minimizing the lag associated with traditional moving averages, this function allows the indicator to react more quickly to changes in market conditions, providing timely signals and improving the overall effectiveness of the indicator.
Bartels Probability:
The Bartels probability function calculates the probability of a given cycle being significant in a time series. It uses a mathematical test called the Bartels test to assess the significance of cycles detected in the data. The function calculates coefficients for each detected cycle and computes an average amplitude and an expected amplitude. By comparing these values, the Bartels probability is derived, indicating the likelihood of a cycle's significance. This information can help in identifying and analyzing dominant cycles in financial markets.
The Bartels probability function is incorporated into the indicator to assess the significance of detected cycles in the input data. By calculating the Bartels probability for each cycle, the indicator can prioritize the most significant cycles and focus on the market dynamics that are most relevant to the current trading environment. This function enhances the indicator's ability to identify dominant market cycles, improving its predictive power and aiding in the development of effective trading strategies.
Detrend Logarithmic Zero-Lag Regression:
The detrend logarithmic zero-lag regression function is used for detrending data while minimizing lag. It combines a zero-lag moving average with a linear regression detrending method. The function first calculates the zero-lag moving average of the logarithm of input data and then applies a linear regression to remove the trend. By detrending the data, the function isolates the cyclical components, making it easier to analyze and interpret the underlying market dynamics.
The detrend logarithmic zero-lag regression function is used in the indicator to isolate the cyclical components of the input data. By detrending the data, the function enables the indicator to focus on the cyclical movements in the market, making it easier to analyze and interpret market dynamics. This function is essential for identifying cyclical patterns and understanding the interactions between different market cycles, which can inform trading decisions and enhance overall market understanding.
Bartels Cycle Significance Test:
The Bartels cycle significance test is a function that combines the Bartels probability function and the detrend logarithmic zero-lag regression function to assess the significance of detected cycles. The function calculates the Bartels probability for each cycle and stores the results in an array. By analyzing the probability values, traders and analysts can identify the most significant cycles in the data, which can be used to develop trading strategies and improve market understanding.
The Bartels cycle significance test function is integrated into the indicator to provide a comprehensive analysis of the significance of detected cycles. By combining the Bartels probability function and the detrend logarithmic zero-lag regression function, this test evaluates the significance of each cycle and stores the results in an array. The indicator can then use this information to prioritize the most significant cycles and focus on the most relevant market dynamics. This function enhances the indicator's ability to identify and analyze dominant market cycles, providing valuable insights for trading and market analysis.
Hodrick-Prescott Filter:
The Hodrick-Prescott filter is a popular technique used to separate the trend and cyclical components of a time series. The function applies a smoothing parameter to the input data and calculates a smoothed series using a two-sided filter. This smoothed series represents the trend component, which can be subtracted from the original data to obtain the cyclical component. The Hodrick-Prescott filter is commonly used in economics and finance to analyze economic data and financial market trends.
The Hodrick-Prescott filter is incorporated into the indicator to separate the trend and cyclical components of the input data. By applying the filter to the data, the indicator can isolate the trend component, which can be used to analyze long-term market trends and inform trading decisions. Additionally, the cyclical component can be used to identify shorter-term market dynamics and provide insights into potential trading opportunities. The inclusion of the Hodrick-Prescott filter adds another layer of analysis to the indicator, making it more versatile and comprehensive.
Detrending Options: Detrend Centered Moving Average:
The detrend centered moving average function provides different detrending methods, including the Hodrick-Prescott filter and the zero-lag moving average, based on the selected detrending method. The function calculates two sets of smoothed values using the chosen method and subtracts one set from the other to obtain a detrended series. By offering multiple detrending options, this function allows traders and analysts to select the most appropriate method for their specific needs and preferences.
The detrend centered moving average function is integrated into the indicator to provide users with multiple detrending options, including the Hodrick-Prescott filter and the zero-lag moving average. By offering multiple detrending methods, the indicator allows users to customize the analysis to their specific needs and preferences, enhancing the indicator's overall utility and adaptability. This function ensures that the indicator can cater to a wide range of trading styles and objectives, making it a valuable tool for a diverse group of market participants.
The auxiliary functions functions discussed in this section demonstrate the power and versatility of mathematical techniques in analyzing financial markets. By understanding and implementing these functions, traders and analysts can gain valuable insights into market dynamics, improve their trading strategies, and make more informed decisions. The combination of zero-lag moving averages, Bartels probability, detrending methods, and the Hodrick-Prescott filter provides a comprehensive toolkit for analyzing and interpreting financial data. The integration of advanced functions in a financial indicator creates a powerful and versatile analytical tool that can provide valuable insights into financial markets. By combining the zero-lag moving average,
█ In-Depth Analysis of the Goertzel Browser Code
The Goertzel Browser code is an implementation of the Goertzel Algorithm, an efficient technique to perform spectral analysis on a signal. The code is designed to detect and analyze dominant cycles within a given financial market data set. This section will provide an extremely detailed explanation of the code, its structure, functions, and intended purpose.
Function signature and input parameters:
The Goertzel Browser function accepts numerous input parameters for customization, including source data (src), the current bar (forBar), sample size (samplesize), period (per), squared amplitude flag (squaredAmp), addition flag (useAddition), cosine flag (useCosine), cycle strength flag (UseCycleStrength), past and future window sizes (WindowSizePast, WindowSizeFuture), Bartels filter flag (FilterBartels), Bartels-related parameters (BartNoCycles, BartSmoothPer, BartSigLimit), sorting flag (SortBartels), and output buffers (goeWorkPast, goeWorkFuture, cyclebuffer, amplitudebuffer, phasebuffer, cycleBartelsBuffer).
Initializing variables and arrays:
The code initializes several float arrays (goeWork1, goeWork2, goeWork3, goeWork4) with the same length as twice the period (2 * per). These arrays store intermediate results during the execution of the algorithm.
Preprocessing input data:
The input data (src) undergoes preprocessing to remove linear trends. This step enhances the algorithm's ability to focus on cyclical components in the data. The linear trend is calculated by finding the slope between the first and last values of the input data within the sample.
Iterative calculation of Goertzel coefficients:
The core of the Goertzel Browser algorithm lies in the iterative calculation of Goertzel coefficients for each frequency bin. These coefficients represent the spectral content of the input data at different frequencies. The code iterates through the range of frequencies, calculating the Goertzel coefficients using a nested loop structure.
Cycle strength computation:
The code calculates the cycle strength based on the Goertzel coefficients. This is an optional step, controlled by the UseCycleStrength flag. The cycle strength provides information on the relative influence of each cycle on the data per bar, considering both amplitude and cycle length. The algorithm computes the cycle strength either by squaring the amplitude (controlled by squaredAmp flag) or using the actual amplitude values.
Phase calculation:
The Goertzel Browser code computes the phase of each cycle, which represents the position of the cycle within the input data. The phase is calculated using the arctangent function (math.atan) based on the ratio of the imaginary and real components of the Goertzel coefficients.
Peak detection and cycle extraction:
The algorithm performs peak detection on the computed amplitudes or cycle strengths to identify dominant cycles. It stores the detected cycles in the cyclebuffer array, along with their corresponding amplitudes and phases in the amplitudebuffer and phasebuffer arrays, respectively.
Sorting cycles by amplitude or cycle strength:
The code sorts the detected cycles based on their amplitude or cycle strength in descending order. This allows the algorithm to prioritize cycles with the most significant impact on the input data.
Bartels cycle significance test:
If the FilterBartels flag is set, the code performs a Bartels cycle significance test on the detected cycles. This test determines the statistical significance of each cycle and filters out the insignificant cycles. The significant cycles are stored in the cycleBartelsBuffer array. If the SortBartels flag is set, the code sorts the significant cycles based on their Bartels significance values.
Waveform calculation:
The Goertzel Browser code calculates the waveform of the significant cycles for both past and future time windows. The past and future windows are defined by the WindowSizePast and WindowSizeFuture parameters, respectively. The algorithm uses either cosine or sine functions (controlled by the useCosine flag) to calculate the waveforms for each cycle. The useAddition flag determines whether the waveforms should be added or subtracted.
Storing waveforms in matrices:
The calculated waveforms for each cycle are stored in two matrices - goeWorkPast and goeWorkFuture. These matrices hold the waveforms for the past and future time windows, respectively. Each row in the matrices represents a time window position, and each column corresponds to a cycle.
Returning the number of cycles:
The Goertzel Browser function returns the total number of detected cycles (number_of_cycles) after processing the input data. This information can be used to further analyze the results or to visualize the detected cycles.
The Goertzel Browser code is a comprehensive implementation of the Goertzel Algorithm, specifically designed for detecting and analyzing dominant cycles within financial market data. The code offers a high level of customization, allowing users to fine-tune the algorithm based on their specific needs. The Goertzel Browser's combination of preprocessing, iterative calculations, cycle extraction, sorting, significance testing, and waveform calculation makes it a powerful tool for understanding cyclical components in financial data.
█ Generating and Visualizing Composite Waveform
The indicator calculates and visualizes the composite waveform for both past and future time windows based on the detected cycles. Here's a detailed explanation of this process:
Updating WindowSizePast and WindowSizeFuture:
The WindowSizePast and WindowSizeFuture are updated to ensure they are at least twice the MaxPer (maximum period).
Initializing matrices and arrays:
Two matrices, goeWorkPast and goeWorkFuture, are initialized to store the Goertzel results for past and future time windows. Multiple arrays are also initialized to store cycle, amplitude, phase, and Bartels information.
Preparing the source data (srcVal) array:
The source data is copied into an array, srcVal, and detrended using one of the selected methods (hpsmthdt, zlagsmthdt, logZlagRegression, hpsmth, or zlagsmth).
Goertzel function call:
The Goertzel function is called to analyze the detrended source data and extract cycle information. The output, number_of_cycles, contains the number of detected cycles.
Initializing arrays for past and future waveforms:
Three arrays, epgoertzel, goertzel, and goertzelFuture, are initialized to store the endpoint Goertzel, non-endpoint Goertzel, and future Goertzel projections, respectively.
Calculating composite waveform for past bars (goertzel array):
The past composite waveform is calculated by summing the selected cycles (either from the user-defined cycle list or the top cycles) and optionally subtracting the noise component.
Calculating composite waveform for future bars (goertzelFuture array):
The future composite waveform is calculated in a similar way as the past composite waveform.
Drawing past composite waveform (pvlines):
The past composite waveform is drawn on the chart using solid lines. The color of the lines is determined by the direction of the waveform (green for upward, red for downward).
Drawing future composite waveform (fvlines):
The future composite waveform is drawn on the chart using dotted lines. The color of the lines is determined by the direction of the waveform (fuchsia for upward, yellow for downward).
Displaying cycle information in a table (table3):
A table is created to display the cycle information, including the rank, period, Bartel value, amplitude (or cycle strength), and phase of each detected cycle.
Filling the table with cycle information:
The indicator iterates through the detected cycles and retrieves the relevant information (period, amplitude, phase, and Bartel value) from the corresponding arrays. It then fills the table with this information, displaying the values up to six decimal places.
To summarize, this indicator generates a composite waveform based on the detected cycles in the financial data. It calculates the composite waveforms for both past and future time windows and visualizes them on the chart using colored lines. Additionally, it displays detailed cycle information in a table, including the rank, period, Bartel value, amplitude (or cycle strength), and phase of each detected cycle.
█ Enhancing the Goertzel Algorithm-Based Script for Financial Modeling and Trading
The Goertzel algorithm-based script for detecting dominant cycles in financial data is a powerful tool for financial modeling and trading. It provides valuable insights into the past behavior of these cycles and potential future impact. However, as with any algorithm, there is always room for improvement. This section discusses potential enhancements to the existing script to make it even more robust and versatile for financial modeling, general trading, advanced trading, and high-frequency finance trading.
Enhancements for Financial Modeling
Data preprocessing: One way to improve the script's performance for financial modeling is to introduce more advanced data preprocessing techniques. This could include removing outliers, handling missing data, and normalizing the data to ensure consistent and accurate results.
Additional detrending and smoothing methods: Incorporating more sophisticated detrending and smoothing techniques, such as wavelet transform or empirical mode decomposition, can help improve the script's ability to accurately identify cycles and trends in the data.
Machine learning integration: Integrating machine learning techniques, such as artificial neural networks or support vector machines, can help enhance the script's predictive capabilities, leading to more accurate financial models.
Enhancements for General and Advanced Trading
Customizable indicator integration: Allowing users to integrate their own technical indicators can help improve the script's effectiveness for both general and advanced trading. By enabling the combination of the dominant cycle information with other technical analysis tools, traders can develop more comprehensive trading strategies.
Risk management and position sizing: Incorporating risk management and position sizing functionality into the script can help traders better manage their trades and control potential losses. This can be achieved by calculating the optimal position size based on the user's risk tolerance and account size.
Multi-timeframe analysis: Enhancing the script to perform multi-timeframe analysis can provide traders with a more holistic view of market trends and cycles. By identifying dominant cycles on different timeframes, traders can gain insights into the potential confluence of cycles and make better-informed trading decisions.
Enhancements for High-Frequency Finance Trading
Algorithm optimization: To ensure the script's suitability for high-frequency finance trading, optimizing the algorithm for faster execution is crucial. This can be achieved by employing efficient data structures and refining the calculation methods to minimize computational complexity.
Real-time data streaming: Integrating real-time data streaming capabilities into the script can help high-frequency traders react to market changes more quickly. By continuously updating the cycle information based on real-time market data, traders can adapt their strategies accordingly and capitalize on short-term market fluctuations.
Order execution and trade management: To fully leverage the script's capabilities for high-frequency trading, implementing functionality for automated order execution and trade management is essential. This can include features such as stop-loss and take-profit orders, trailing stops, and automated trade exit strategies.
While the existing Goertzel algorithm-based script is a valuable tool for detecting dominant cycles in financial data, there are several potential enhancements that can make it even more powerful for financial modeling, general trading, advanced trading, and high-frequency finance trading. By incorporating these improvements, the script can become a more versatile and effective tool for traders and financial analysts alike.
█ Understanding the Limitations of the Goertzel Algorithm
While the Goertzel algorithm-based script for detecting dominant cycles in financial data provides valuable insights, it is important to be aware of its limitations and drawbacks. Some of the key drawbacks of this indicator are:
Lagging nature:
As with many other technical indicators, the Goertzel algorithm-based script can suffer from lagging effects, meaning that it may not immediately react to real-time market changes. This lag can lead to late entries and exits, potentially resulting in reduced profitability or increased losses.
Parameter sensitivity:
The performance of the script can be sensitive to the chosen parameters, such as the detrending methods, smoothing techniques, and cycle detection settings. Improper parameter selection may lead to inaccurate cycle detection or increased false signals, which can negatively impact trading performance.
Complexity:
The Goertzel algorithm itself is relatively complex, making it difficult for novice traders or those unfamiliar with the concept of cycle analysis to fully understand and effectively utilize the script. This complexity can also make it challenging to optimize the script for specific trading styles or market conditions.
Overfitting risk:
As with any data-driven approach, there is a risk of overfitting when using the Goertzel algorithm-based script. Overfitting occurs when a model becomes too specific to the historical data it was trained on, leading to poor performance on new, unseen data. This can result in misleading signals and reduced trading performance.
No guarantee of future performance: While the script can provide insights into past cycles and potential future trends, it is important to remember that past performance does not guarantee future results. Market conditions can change, and relying solely on the script's predictions without considering other factors may lead to poor trading decisions.
Limited applicability: The Goertzel algorithm-based script may not be suitable for all markets, trading styles, or timeframes. Its effectiveness in detecting cycles may be limited in certain market conditions, such as during periods of extreme volatility or low liquidity.
While the Goertzel algorithm-based script offers valuable insights into dominant cycles in financial data, it is essential to consider its drawbacks and limitations when incorporating it into a trading strategy. Traders should always use the script in conjunction with other technical and fundamental analysis tools, as well as proper risk management, to make well-informed trading decisions.
█ Interpreting Results
The Goertzel Browser indicator can be interpreted by analyzing the plotted lines and the table presented alongside them. The indicator plots two lines: past and future composite waves. The past composite wave represents the composite wave of the past price data, and the future composite wave represents the projected composite wave for the next period.
The past composite wave line displays a solid line, with green indicating a bullish trend and red indicating a bearish trend. On the other hand, the future composite wave line is a dotted line with fuchsia indicating a bullish trend and yellow indicating a bearish trend.
The table presented alongside the indicator shows the top cycles with their corresponding rank, period, Bartels, amplitude or cycle strength, and phase. The amplitude is a measure of the strength of the cycle, while the phase is the position of the cycle within the data series.
Interpreting the Goertzel Browser indicator involves identifying the trend of the past and future composite wave lines and matching them with the corresponding bullish or bearish color. Additionally, traders can identify the top cycles with the highest amplitude or cycle strength and utilize them in conjunction with other technical indicators and fundamental analysis for trading decisions.
This indicator is considered a repainting indicator because the value of the indicator is calculated based on the past price data. As new price data becomes available, the indicator's value is recalculated, potentially causing the indicator's past values to change. This can create a false impression of the indicator's performance, as it may appear to have provided a profitable trading signal in the past when, in fact, that signal did not exist at the time.
The Goertzel indicator is also non-endpointed, meaning that it is not calculated up to the current bar or candle. Instead, it uses a fixed amount of historical data to calculate its values, which can make it difficult to use for real-time trading decisions. For example, if the indicator uses 100 bars of historical data to make its calculations, it cannot provide a signal until the current bar has closed and become part of the historical data. This can result in missed trading opportunities or delayed signals.
█ Conclusion
The Goertzel Browser indicator is a powerful tool for identifying and analyzing cyclical patterns in financial markets. Its ability to detect multiple cycles of varying frequencies and strengths make it a valuable addition to any trader's technical analysis toolkit. However, it is important to keep in mind that the Goertzel Browser indicator should be used in conjunction with other technical analysis tools and fundamental analysis to achieve the best results. With continued refinement and development, the Goertzel Browser indicator has the potential to become a highly effective tool for financial modeling, general trading, advanced trading, and high-frequency finance trading. Its accuracy and versatility make it a promising candidate for further research and development.
█ Footnotes
What is the Bartels Test for Cycle Significance?
The Bartels Cycle Significance Test is a statistical method that determines whether the peaks and troughs of a time series are statistically significant. The test is named after its inventor, George Bartels, who developed it in the mid-20th century.
The Bartels test is designed to analyze the cyclical components of a time series, which can help traders and analysts identify trends and cycles in financial markets. The test calculates a Bartels statistic, which measures the degree of non-randomness or autocorrelation in the time series.
The Bartels statistic is calculated by first splitting the time series into two halves and calculating the range of the peaks and troughs in each half. The test then compares these ranges using a t-test, which measures the significance of the difference between the two ranges.
If the Bartels statistic is greater than a critical value, it indicates that the peaks and troughs in the time series are non-random and that there is a significant cyclical component to the data. Conversely, if the Bartels statistic is less than the critical value, it suggests that the peaks and troughs are random and that there is no significant cyclical component.
The Bartels Cycle Significance Test is particularly useful in financial analysis because it can help traders and analysts identify significant cycles in asset prices, which can in turn inform investment decisions. However, it is important to note that the test is not perfect and can produce false signals in certain situations, particularly in noisy or volatile markets. Therefore, it is always recommended to use the test in conjunction with other technical and fundamental indicators to confirm trends and cycles.
Deep-dive into the Hodrick-Prescott Fitler
The Hodrick-Prescott (HP) filter is a statistical tool used in economics and finance to separate a time series into two components: a trend component and a cyclical component. It is a powerful tool for identifying long-term trends in economic and financial data and is widely used by economists, central banks, and financial institutions around the world.
The HP filter was first introduced in the 1990s by economists Robert Hodrick and Edward Prescott. It is a simple, two-parameter filter that separates a time series into a trend component and a cyclical component. The trend component represents the long-term behavior of the data, while the cyclical component captures the shorter-term fluctuations around the trend.
The HP filter works by minimizing the following objective function:
Minimize: (Sum of Squared Deviations) + λ (Sum of Squared Second Differences)
Where:
The first term represents the deviation of the data from the trend.
The second term represents the smoothness of the trend.
λ is a smoothing parameter that determines the degree of smoothness of the trend.
The smoothing parameter λ is typically set to a value between 100 and 1600, depending on the frequency of the data. Higher values of λ lead to a smoother trend, while lower values lead to a more volatile trend.
The HP filter has several advantages over other smoothing techniques. It is a non-parametric method, meaning that it does not make any assumptions about the underlying distribution of the data. It also allows for easy comparison of trends across different time series and can be used with data of any frequency.
However, the HP filter also has some limitations. It assumes that the trend is a smooth function, which may not be the case in some situations. It can also be sensitive to changes in the smoothing parameter λ, which may result in different trends for the same data. Additionally, the filter may produce unrealistic trends for very short time series.
Despite these limitations, the HP filter remains a valuable tool for analyzing economic and financial data. It is widely used by central banks and financial institutions to monitor long-term trends in the economy, and it can be used to identify turning points in the business cycle. The filter can also be used to analyze asset prices, exchange rates, and other financial variables.
The Hodrick-Prescott filter is a powerful tool for analyzing economic and financial data. It separates a time series into a trend component and a cyclical component, allowing for easy identification of long-term trends and turning points in the business cycle. While it has some limitations, it remains a valuable tool for economists, central banks, and financial institutions around the world.
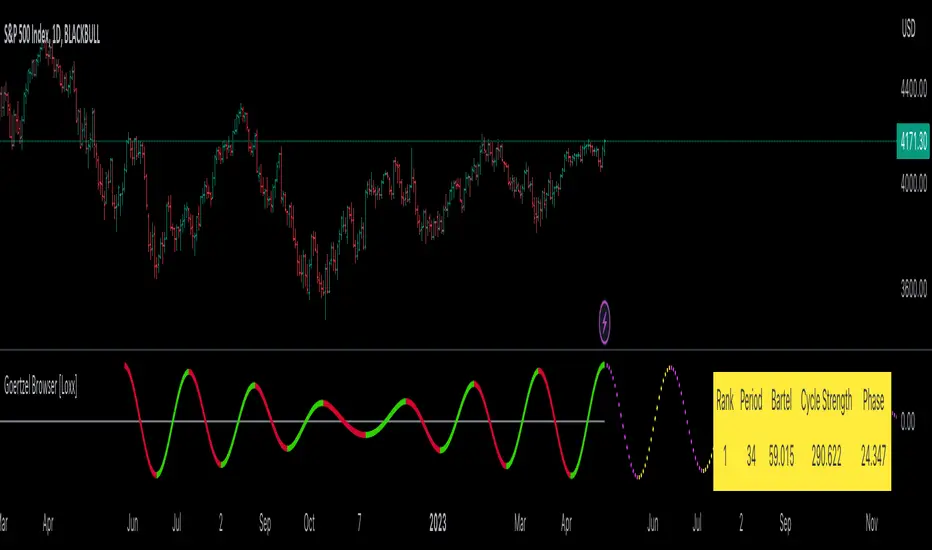
Adaptive Candlestick Pattern Recognition System█ INTRODUCTION
Nearly three years in the making, intermittently worked on in the few spare hours of weekends and time off, this is a passion project I undertook to flesh out my skills as a computer programmer. This script currently recognizes 85 different candlestick patterns ranging from one to five candles in length. It also performs statistical analysis on those patterns to determine prior performance and changes the coloration of those patterns based on that performance. In searching TradingView's script library for scripts similar to this one, I had found a handful. However, when I reviewed the ones which were open source, I did not see many that truly captured the power of PineScrypt or leveraged the way it works to create efficient and reliable code; one of the main driving factors for releasing this 5,000+ line behemoth open sourced.
Please take the time to review this description and source code to utilize this script to its fullest potential.
█ CONCEPTS
This script covers the following topics: Candlestick Theory, Trend Direction, Higher Timeframes, Price Analysis, Statistic Analysis, and Code Design.
Candlestick Theory - This script focuses solely on the concept of Candlestick Theory: arrangements of candlesticks may form certain patterns that can potentially influence the future price action of assets which experience those patterns. A full list of patterns (grouped by pattern length) will be in its own section of this description. This script contains two modes of operation for identifying candlestick patterns, 'CLASSIC' and 'BREAKOUT'.
CLASSIC: In this mode, candlestick patterns will be identified whenever they appear. The user has a wide variety of inputs to manipulate that can change how certain patterns are identified and even enable alerts to notify themselves when these patterns appear. Each pattern selected to appear will have their Profit or Loss (P/L) calculated starting from the first candle open succeeding the pattern to a candle close specified some number of candles ahead. These P/L calculations are then collected for each pattern, and split among partitions of prior price action of the asset the script is currently applied to (more on that in Higher Timeframes ).
BREAKOUT: In this mode, P/L calculations are held off until a breakout direction has been confirmed. The user may specify the number of candles ahead of a pattern's appearance (from one to five) that a pattern has to confirm a breakout in either an upward or downward direction. A breakout is constituted when there is a candle following the appearance of the pattern that closes above/at the highest high of the pattern, or below/at its lowest low. Only then will percent return calculations be performed for the pattern that's been identified, and these percent returns are broken up not only by the partition they had appeared in but also by the breakout direction itself. Patterns which do not breakout in either direction will be ignored, along with having their labels deleted.
In both of these modes, patterns may be overridden. Overrides occur when a smaller pattern has been detected and ends up becoming one (or more) of the candles of a larger pattern. A key example of this would be the Bearish Engulfing and the Three Outside Down patterns. A Three Outside Down necessitates a Bearish Engulfing as the first two candles in it, while the third candle closes lower. When a pattern is overridden, the return for that pattern will no longer be tracked. Overrides will not occur if the tail end of a larger pattern occurs at the beginning of a smaller pattern (Ex: a Bullish Engulfing occurs on the third candle of a Three Outside Down and the candle immediately following that pattern, the Three Outside Down pattern will not be overridden).
Important Functionality Note: These patterns are only searched for at the most recently closed candle, not on the currently closing candle, which creates an offset of one for this script's execution. (SEE LIMITATIONS)
Trend Direction - Many of the patterns require a trend direction prior to their appearance. Noting TradingView's own publication of candlestick patterns, I utilize a similar method for determining trend direction. Moving Averages are used to determine which trend is currently taking place for candlestick patterns to be sought out. The user has access to two Moving Averages which they may individually modify the following for each: Moving Average type (list of 9), their length, width, source values, and all variables associated with two special Moving Averages (Least Squares and Arnaud Legoux).
There are 3 settings for these Moving Averages, the first two switch between the two Moving Averages, and the third uses both. When using individual Moving Averages, the user may select a 'price point' to compare against the Moving Average (default is close). This price point is compared to the Moving Average at the candles prior to the appearance of candle patterns. Meaning: The close compared to the Moving Average two candles behind determines the trend direction used for Candlestick Analysis of one candle patterns; three candles behind for two candle patterns and so on. If the selected price point is above the Moving Average, then the current trend is an 'uptrend', 'downtrend' otherwise.
The third setting using both Moving Averages will compare the lengths of each, and trend direction is determined by the shorter Moving Average compared to the longer one. If the shorter Moving Average is above the longer, then the current trend is an 'uptrend', 'downtrend' otherwise. If the lengths of the Moving Averages are the same, or both Moving Averages are Symmetrical, then MA1 will be used by default. (SEE LIMITATIONS)
Higher Timeframes - This script employs the use of Higher Timeframes with a few request.security calls. The purpose of these calls is strictly for the partitioning of an asset's chart, splitting the returns of patterns into three separate groups. The four inputs in control of this partitioning split the chart based on: A given resolution to grab values from, the length of time in that resolution, and 'Upper' and 'Lower Limits' which split the trading range provided by that length of time in that resolution that forms three separate groups. The default values for these four inputs will partition the current chart by the yearly high-low range where: the 'Upper' partition is the top 20% of that trading range, the 'Middle' partition is 80% to 33% of the trading range, and the 'Lower' partition covers the trading range within 33% of the yearly low.
Patterns which are identified by this script will have their returns grouped together based on which partition they had appeared in. For example, a Bullish Engulfing which occurs within a third of the yearly low will have its return placed separately from a Bullish Engulfing that occurred within 20% of the yearly high. The idea is that certain patterns may perform better or worse depending on when they had occurred during an asset's trading range.
Price Analysis - Price Analysis is a major part of this script's functionality as it can fundamentally change how patterns are shown to the user. The settings related to Price Analysis include setting the number of candles ahead of a pattern's appearance to determine the return of that pattern. In 'BREAKOUT' mode, an additional setting allows the user to specify where the P/L calculation will begin for a pattern that had appeared and confirmed. (SEE LIMITATIONS)
The calculation for percent returns of patterns is illustrated with the following pseudo-code (CLASSIC mode, this is a simplified version of the actual code):
type patternObj
int ID
int partition
type returnsArray
float returns
// No pattern found = na returned
patternObj TEST_VAL = f_FindPattern()
priorTestVal = TEST_VAL
if not na( priorTestVal )
pnlMatrixRow = priorTestVal.ID
pnlMatrixCol = priorTestVal.partition
matrixReturn = matrix.get(PERCENT_RETURNS, pnlMatrixRow, pnlMatrixCol)
percentReturn = ( (close - open ) / open ) * 100%
array.push(matrixReturn.returns, percentReturn)
Statistic Analysis - This script uses Pine's built-in array functions to conduct the Statistic Analysis for patterns. When a pattern is found and its P/L calculation is complete, its return is added to a 'Return Array' User-Defined-Type that contains numerous fields which retain information on a pattern's prior performance. The actual UDT is as follows:
type returnArray
float returns = na
int size = 0
float avg = 0
float median = 0
float stdDev = 0
int polarities = na
All values within this UDT will be updated when a return is added to it (some based on user input). The array.avg , array.median and array.stdev will be ran and saved into their respective fields after a return is placed in the 'returns' array. The 'polarities' integer array is what will be changed based on user input. The user specifies two different percentages that declare 'Positive' and 'Negative' returns for patterns. When a pattern returns above, below, or in between these two values, different indices of this array will be incremented to reflect the kind of return that pattern had just experienced.
These values (plus the full name, partition the pattern occurred in, and a 95% confidence interval of expected returns) will be displayed to the user on the tooltip of the labels that identify patterns. Simply scroll over the pattern label to view each of these values.
Code Design - Overall this script is as much of an art piece as it is functional. Its design features numerous depictions of ASCII Art that illustrate what is being attempted by the functions that identify patterns, and an incalculable amount of time was spent rewriting portions of code to improve its efficiency. Admittedly, this final version is nearly 1,000 lines shorter than a previous version (one which took nearly 30 seconds after compilation to run, and didn't do nearly half of what this version does). The use of UDTs, especially the 'patternObj' one crafted and redesigned from the Hikkake Hunter 2.0 I published last month, played a significant role in making this script run efficiently. There is a slight rigidity in some of this code mainly around pattern IDs which are responsible for displaying the abbreviation for patterns (as well as the full names under the tooltips, and the matrix row position for holding returns), as each is hard-coded to correspond to that pattern.
However, one thing I would like to mention is the extensive use of global variables for pattern detection. Many scripts I had looked over for ideas on how to identify candlestick patterns had the same idea; break the pattern into a set of logical 'true/false' statements derived from historically referencing candle OHLC values. Some scripts which identified upwards of 20 to 30 patterns would reference Pine's built-in OHLC values for each pattern individually, potentially requesting information from TradingView's servers numerous times that could easily be saved into a variable for re-use and only requested once per candle (what this script does).
█ FEATURES
This script features a massive amount of switches, options, floating point values, detection settings, and methods for identifying/tailoring pattern appearances. All modifiable inputs for patterns are grouped together based on the number of candles they contain. Other inputs (like those for statistics settings and coloration) are grouped separately and presented in a way I believe makes the most sense.
Not mentioned above is the coloration settings. One of the aims of this script was to make patterns visually signify their behavior to the user when they are identified. Each pattern has its own collection of returns which are analyzed and compared to the inputs of the user. The user may choose the colors for bullish, neutral, and bearish patterns. They may also choose the minimum number of patterns needed to occur before assigning a color to that pattern based on its behavior; a color for patterns that have not met this minimum number of occurrences yet, and a color for patterns that are still processing in BREAKOUT mode.
There are also an additional three settings which alter the color scheme for patterns: Statistic Point-of-Reference, Adaptive coloring, and Hard Limiting. The Statistic Point-of-Reference decides which value (average or median) will be compared against the 'Negative' and 'Positive Return Tolerance'(s) to guide the coloration of the patterns (or for Adaptive Coloring, the generation of a color gradient).
Adaptive Coloring will have this script produce a gradient that patterns will be colored along. The more bullish or bearish a pattern is, the further along the gradient those patterns will be colored starting from the 'Neutral' color (hard lined at the value of 0%: values above this will be colored bullish, bearish otherwise). When Adaptive Coloring is enabled, this script will request the highest and lowest values (these being the Statistic Point-of-Reference) from the matrix containing all returns and rewrite global variables tied to the negative and positive return tolerances. This means that all patterns identified will be compared with each other to determine bullish/bearishness in Adaptive Coloring.
Hard Limiting will prevent these global variables from being rewritten, so patterns whose Statistic Point-of-Reference exceed the return tolerances will be fully colored the bullish or bearish colors instead of a generated gradient color. (SEE LIMITATIONS)
Apart from the Candle Detection Modes (CLASSIC and BREAKOUT), there's an additional two inputs which modify how this script behaves grouped under a "MASTER DETECTION SETTINGS" tab. These two "Pattern Detection Settings" are 'SWITCHBOARD' and 'TARGET MODE'.
SWITCHBOARD: Every single pattern has a switch that is associated with its detection. When a switch is enabled, the code which searches for that pattern will be run. With the Pattern Detection Setting set to this, all patterns that have their switches enabled will be sought out and shown.
TARGET MODE: There is an additional setting which operates on top of 'SWITCHBOARD' that singles out an individual pattern the user specifies through a drop down list. The names of every pattern recognized by this script will be present along with an identifier that shows the number of candles in that pattern (Ex: " (# candles)"). All patterns enabled in the switchboard will still have their returns measured, but only the pattern selected from the "Target Pattern" list will be shown. (SEE LIMITATIONS)
The vast majority of other features are held in the one, two, and three candle pattern sections.
For one-candle patterns, there are:
3 — Settings related to defining 'Tall' candles:
The number of candles to sample for previous candle-size averages.
The type of comparison done for 'Tall' Candles: Settings are 'RANGE' and 'BODY'.
The 'Tolerance' for tall candles, specifying what percent of the 'average' size candles must exceed to be considered 'Tall'.
When 'Tall Candle Setting' is set to RANGE, the high-low ranges are what the current candle range will be compared against to determine if a candle is 'Tall'. Otherwise the candle bodies (absolute value of the close - open) will be compared instead. (SEE LIMITATIONS)
Hammer Tolerance - How large a 'discarded wick' may be before it disqualifies a candle from being a 'Hammer'.
Discarded wicks are compared to the size of the Hammer's candle body and are dependent upon the body's center position. Hammer bodies closer to the high of the candle will have the upper wick used as its 'discarded wick', otherwise the lower wick is used.
9 — Doji Settings, some pulled from an old Doji Hunter I made a while back:
Doji Tolerance - How large the body of a candle may be compared to the range to be considered a 'Doji'.
Ignore N/S Dojis - Turns off Trend Direction for non-special Dojis.
GS/DF Doji Settings - 2 Inputs that enable and specify how large wicks that typically disqualify Dojis from being 'Gravestone' or 'Dragonfly' Dojis may be.
4 Settings related to 'Long Wick Doji' candles detailed below.
A Tolerance for 'Rickshaw Man' Dojis specifying how close the center of the body must be to the range to be valid.
The 4 settings the user may modify for 'Long Legged' Dojis are: A Sample Base for determining the previous average of wicks, a Sample Length specifying how far back to look for these averages, a Behavior Setting to define how 'Long Legged' Dojis are recognized, and a tolerance to specify how large in comparison to the prior wicks a Doji's wicks must be to be considered 'Long Legged'.
The 'Sample Base' list has two settings:
RANGE: The wicks of prior candles are compared to their candle ranges and the 'wick averages' will be what the average percent of ranges were in the sample.
WICKS: The size of the wicks themselves are averaged and returned for comparing against the current wicks of a Doji.
The 'Behavior' list has three settings:
ONE: Only one wick length needs to exceed the average by the tolerance for a Doji to be considered 'Long Legged'.
BOTH: Both wick lengths need to exceed the average of the tolerance of their respective wicks (upper wicks are compared to upper wicks, lower wicks compared to lower) to be considered 'Long Legged'.
AVG: Both wicks and the averages of the previous wicks are added together, divided by two, and compared. If the 'average' of the current wicks exceeds this combined average of prior wicks by the tolerance, then this would constitute a valid 'Long Legged' Doji. (For Dojis in general - SEE LIMITATIONS)
The final input is one related to candle patterns which require a Marubozu candle in them. The two settings for this input are 'INCLUSIVE' and 'EXCLUSIVE'. If INCLUSIVE is selected, any opening/closing variant of Marubozu candles will be allowed in the patterns that require them.
For two-candle patterns, there are:
2 — Settings which define 'Engulfing' parameters:
Engulfing Setting - Two options, RANGE or BODY which sets up how one candle may 'engulf' the previous.
Inclusive Engulfing - Boolean which enables if 'engulfing' candles can be equal to the values needed to 'engulf' the prior candle.
For the 'Engulfing Setting':
RANGE: If the second candle's high-low range completely covers the high-low range of the prior candle, this is recognized as 'engulfing'.
BODY: If the second candle's open-close completely covers the open-close of the previous candle, this is recognized as 'engulfing'. (SEE LIMITATIONS)
4 — Booleans specifying different settings for a few patterns:
One which allows for 'opens within body' patterns to let the second candle's open/close values match the prior candles' open/close.
One which forces 'Kicking' patterns to have a gap if the Marubozu setting is set to 'INCLUSIVE'.
And Two which dictate if the individual candles in 'Stomach' patterns need to be 'Tall'.
8 — Floating point values which affect 11 different patterns:
One which determines the distance the close of the first candle in a 'Hammer Inverted' pattern must be to the low to be considered valid.
One which affects how close the opens/closes need to be for all 'Lines' patterns (Bull/Bear Meeting/Separating Lines).
One that allows some leeway with the 'Matching Low' pattern (gives a small range the second candle close may be within instead of needing to match the previous close).
Three tolerances for On Neck/In Neck patterns (2 and 1 respectively).
A tolerance for the Thrusting pattern which give a range the close the second candle may be between the midpoint and close of the first to be considered 'valid'.
A tolerance for the two Tweezers patterns that specifies how close the highs and lows of the patterns need to be to each other to be 'valid'.
The first On Neck tolerance specifies how large the lower wick of the first candle may be (as a % of that candle's range) before the pattern is invalidated. The second tolerance specifies how far up the lower wick to the close the second candle's close may be for this pattern. The third tolerance for the In Neck pattern determines how far into the body of the first candle the second may close to be 'valid'.
For the remaining patterns (3, 4, and 5 candles), there are:
3 — Settings for the Deliberation pattern:
A boolean which forces the open of the third candle to gap above the close of the second.
A tolerance which changes the proximity of the third candle's open to the second candle's close in this pattern.
A tolerance that sets the maximum size the third candle may be compared to the average of the first two candles.
One boolean value for the Two Crows patterns (standard and Upside Gapping) that forces the first two candles in the patterns to completely gap if disabled (candle 1's close < candle 2's low).
10 — Floating point values for the remaining patterns:
One tolerance for defining how much the size of each candle in the Identical Black Crows pattern may deviate from the average of themselves to be considered valid.
One tolerance for setting how close the opens/closes of certain three candle patterns may be to each other's opens/closes.*
Three floating point values that affect the Three Stars in the South pattern.
One tolerance for the Side-by-Side patterns - looks at the second and third candle closes.
One tolerance for the Stick Sandwich pattern - looks at the first and third candle closes.
A floating value that sizes the Concealing Baby Swallow pattern's 3rd candle wick.
Two values for the Ladder Bottom pattern which define a range that the third candle's wick size may be.
* This affects the Three Black Crows (non-identical) and Three White Soldiers patterns, each require the opens and closes of every candle to be near each other.
The first tolerance of the Three Stars in the South pattern affects the first candle body's center position, and defines where it must be above to be considered valid. The second tolerance specifies how close the second candle must be to this same position, as well as the deviation the ratio the candle body to its range may be in comparison to the first candle. The third restricts how large the second candle range may be in comparison to the first (prevents this pattern from being recognized if the second candle is similar to the first but larger).
The last two floating point values define upper and lower limits to the wick size of a Ladder Bottom's fourth candle to be considered valid.
█ HOW TO USE
While there are many moving parts to this script, I attempted to set the default values with what I believed may help identify the most patterns within reasonable definitions. When this script is applied to a chart, the Candle Detection Mode (along with the BREAKOUT settings) and all candle switches must be confirmed before patterns are displayed. All switches are on by default, so this gives the user an opportunity to pick which patterns to identify first before playing around in the settings.
All of the settings/inputs described above are meant for experimentation. I encourage the user to tweak these values at will to find which set ups work best for whichever charts they decide to apply these patterns to.
Refer to the patterns themselves during experimentation. The statistic information provided on the tooltips of the patterns are meant to help guide input decisions. The breadth of candlestick theory is deep, and this was an attempt at capturing what I could in its sea of information.
█ LIMITATIONS
DISCLAIMER: While it may seem a bit paradoxical that this script aims to use past performance to potentially measure future results, past performance is not indicative of future results . Markets are highly adaptive and often unpredictable. This script is meant as an informational tool to show how patterns may behave. There is no guarantee that confidence intervals (or any other metric measured with this script) are accurate to the performance of patterns; caution must be exercised with all patterns identified regardless of how much information regarding prior performance is available.
Candlestick Theory - In the name, Candlestick Theory is a theory , and all theories come with their own limits. Some patterns identified by this script may be completely useless/unprofitable/unpredictable regardless of whatever combination of settings are used to identify them. However, if I truly believed this theory had no merit, this script would not exist. It is important to understand that this is a tool meant to be utilized with an array of others to procure positive (or negative, looking at you, short sellers ) results when navigating the complex world of finance.
To address the functionality note however, this script has an offset of 1 by default. Patterns will not be identified on the currently closing candle, only on the candle which has most recently closed. Attempting to have this script do both (offset by one or identify on close) lead to more trouble than it was worth. I personally just want users to be aware that patterns will not be identified immediately when they appear.
Trend Direction - Moving Averages - There is a small quirk with how MA settings will be adjusted if the user inputs two moving averages of the same length when the "MA Setting" is set to 'BOTH'. If Moving Averages have the same length, this script will default to only using MA 1 regardless of if the types of Moving Averages are different . I will experiment in the future to alleviate/reduce this restriction.
Price Analysis - BREAKOUT mode - With how identifying patterns with a look-ahead confirmation works, the percent returns for patterns that break out in either direction will be calculated on the same candle regardless of if P/L Offset is set to 'FROM CONFIRMATION' or 'FROM APPEARANCE'. This same issue is present in the Hikkake Hunter script mentioned earlier. This does not mean the P/L calculations are incorrect , the offset for the calculation is set by the number of candles required to confirm the pattern if 'FROM APPEARANCE' is selected. It just means that these two different P/L calculations will complete at the same time independent of the setting that's been selected.
Adaptive Coloring/Hard Limiting - Hard Limiting is only used with Adaptive Coloring and has no effect outside of it. If Hard Limiting is used, it is recommended to increase the 'Positive' and 'Negative' return tolerance values as a pattern's bullish/bearishness may be disproportionately represented with the gradient generated under a hard limit.
TARGET MODE - This mode will break rules regarding patterns that are overridden on purpose. If a pattern selected in TARGET mode would have otherwise been absorbed by a larger pattern, it will have that pattern's percent return calculated; potentially leading to duplicate returns being included in the matrix of all returns recognized by this script.
'Tall' Candle Setting - This is a wide-reaching setting, as approximately 30 different patterns or so rely on defining 'Tall' candles. Changing how 'Tall' candles are defined whether by the tolerance value those candles need to exceed or by the values of the candle used for the baseline comparison (RANGE/BODY) can wildly affect how this script functions under certain conditions. Refer to the tooltip of these settings for more information on which specific patterns are affected by this.
Doji Settings - There are roughly 10 or so two to three candle patterns which have Dojis as a part of them. If all Dojis are disabled, it will prevent some of these larger patterns from being recognized. This is a dependency issue that I may address in the future.
'Engulfing' Setting - Functionally, the two 'Engulfing' settings are quite different. Because of this, the 'RANGE' setting may cause certain patterns that would otherwise be valid under textbook and online references/definitions to not be recognized as such (like the Upside Gap Two Crows or Three Outside down).
█ PATTERN LIST
This script recognizes 85 patterns upon initial release. I am open to adding additional patterns to it in the future and any comments/suggestions are appreciated. It recognizes:
15 — 1 Candle Patterns
4 Hammer type patterns: Regular Hammer, Takuri Line, Shooting Star, and Hanging Man
9 Doji Candles: Regular Dojis, Northern/Southern Dojis, Gravestone/Dragonfly Dojis, Gapping Up/Down Dojis, and Long-Legged/Rickshaw Man Dojis
White/Black Long Days
32 — 2 Candle Patterns
4 Engulfing type patterns: Bullish/Bearish Engulfing and Last Engulfing Top/Bottom
Dark Cloud Cover
Bullish/Bearish Doji Star patterns
Hammer Inverted
Bullish/Bearish Haramis + Cross variants
Homing Pigeon
Bullish/Bearish Kicking
4 Lines type patterns: Bullish/Bearish Meeting/Separating Lines
Matching Low
On/In Neck patterns
Piercing pattern
Shooting Star (2 Lines)
Above/Below Stomach patterns
Thrusting
Tweezers Top/Bottom patterns
Two Black Gapping
Rising/Falling Window patterns
29 — 3 Candle Patterns
Bullish/Bearish Abandoned Baby patterns
Advance Block
Collapsing Doji Star
Deliberation
Upside/Downside Gap Three Methods patterns
Three Inside/Outside Up/Down patterns (4 total)
Bullish/Bearish Side-by-Side patterns
Morning/Evening Star patterns + Doji variants
Stick Sandwich
Downside/Upside Tasuki Gap patterns
Three Black Crows + Identical variation
Three White Soldiers
Three Stars in the South
Bullish/Bearish Tri-Star patterns
Two Crows + Upside Gap variant
Unique Three River Bottom
3 — 4 Candle Patterns
Concealing Baby Swallow
Bullish/Bearish Three Line Strike patterns
6 — 5 Candle Patterns
Bullish/Bearish Breakaway patterns
Ladder Bottom
Mat Hold
Rising/Falling Three Methods patterns
█ WORKS CITED
Because of the amount of time needed to complete this script, I am unable to provide exact dates for when some of these references were used. I will also not provide every single reference, as citing a reference for each individual pattern and the place it was reviewed would lead to a bibliography larger than this script and its description combined. There were five major resources I used when building this script, one book, two websites (for various different reasons including patterns, moving averages, and various other articles of information), various scripts from TradingView's public library (including TradingView's own source code for *all* candle patterns ), and PineScrypt's reference manual.
Bulkowski, Thomas N. Encyclopedia of Candlestick Patterns . Hoboken, New Jersey: John Wiley & Sons Inc., 2008. E-book (google books).
Various. Numerous webpages. CandleScanner . 2023. online. Accessed 2020 - 2023.
Various. Numerous webpages. Investopedia . 2023. online. Accessed 2020 - 2023.
█ AKNOWLEDGEMENTS
I want to take the time here to thank all of my friends and family, both online and in real life, for the support they've given me over the last few years in this endeavor. My pets who tried their hardest to keep me from completing it. And work for the grit to continue pushing through until this script's completion.
This belongs to me just as much as it does anyone else. Whether you are an institutional trader, gold bug hedging against the dollar, retail ape who got in on a squeeze, or just parents trying to grow their retirement/save for the kids. This belongs to everyone.
Private Beta for new features to be tested can be found here .
Vires In Numeris
STD-Adaptive T3 [Loxx]STD-Adaptive T3 is a standard deviation adaptive T3 moving average filter. This indicator acts more like a trend overlay indicator with gradient coloring.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included
Bar coloring
Loxx's Expanded Source Types

Softmax Normalized T3 Histogram [Loxx]Softmax Normalized T3 Histogram is a T3 moving average that is morphed into a normalized oscillator from -1 to 1.
What is the Softmax function?
The softmax function, also known as softargmax: or normalized exponential function, converts a vector of K real numbers into a probability distribution of K possible outcomes. It is a generalization of the logistic function to multiple dimensions, and used in multinomial logistic regression. The softmax function is often used as the last activation function of a neural network to normalize the output of a network to a probability distribution over predicted output classes, based on Luce's choice axiom.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types
T3 Velocity Candles [Loxx]T3 Velocity Candles is a candle coloring overlay that calculates its gradient coloring using T3 velocity.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.

R-squared Adaptive T3 Ribbon Filled Simple [Loxx]R-squared Adaptive T3 Ribbon Filled Simple is a T3 ribbons indicator that uses a special implementation of T3 that is R-squared adaptive.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
What is R-squared Adaptive?
One tool available in forecasting the trendiness of the breakout is the coefficient of determination ( R-squared ), a statistical measurement.
The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average .
R-squared is used here to derive a T3 factor used to modify price before passing price through a six-pole non-linear Kalman filter.
Included:
Alerts
Signals
Loxx's Expanded Source Types
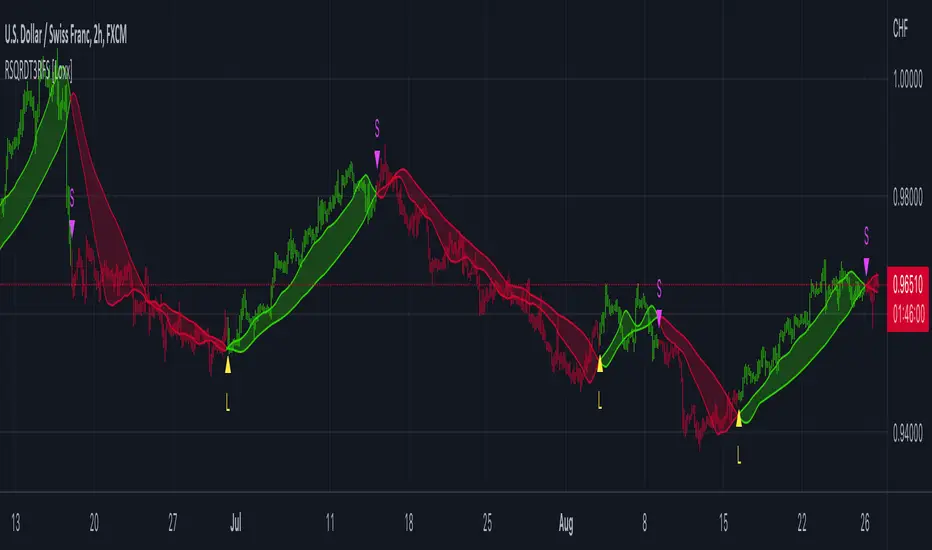
T3 Slope Variation [Loxx]T3 Slope Variation is an indicator that uses T3 moving average to calculate a slope that is then weighted to derive a signal.
The center line
The center line changes color depending on the value of the:
Slope
Signal line
Threshold
If the value is above a signal line (it is not visible on the chart) and the threshold is greater than the required, then the main trend becomes up. And reversed for the trend down.
Colors and style of the histogram
The colors and style of the histogram will be drawn if the value is at the right side, if the above described trend "agrees" with the value (above is green or below zero is red) and if the High is higher than the previous High or Low is lower than the previous low, then the according type of histogram is drawn.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included
Alets
Signals
Bar coloring
Loxx's Expanded Source Types
Multi T3 Slopes [Loxx]Multi T3 Slopes is an indicator that checks slopes of 5 (different period) T3 Moving Averages and adds them up to show overall trend. To us this, check for color changes from red to green where there is no red if green is larger than red and there is no red when red is larger than green. When red and green both show up, its a sign of chop.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included
Signals: long, short, continuation long, continuation short.
Alerts
Bar coloring
Loxx's expanded source types
T3 Volatility Quality Index (VQI) w/ DSL & Pips Filtering [Loxx]T3 Volatility Quality Index (VQI) w/ DSL & Pips Filtering is a VQI indicator that uses T3 smoothing and discontinued signal lines to determine breakouts and breakdowns. This also allows filtering by pips.***
What is the Volatility Quality Index ( VQI )?
The idea behind the volatility quality index is to point out the difference between bad and good volatility in order to identify better trade opportunities in the market. This forex indicator works using the True Range algorithm in combination with the open, close, high and low prices.
What are DSL Discontinued Signal Line?
A lot of indicators are using signal lines in order to determine the trend (or some desired state of the indicator) easier. The idea of the signal line is easy : comparing the value to it's smoothed (slightly lagging) state, the idea of current momentum/state is made.
Discontinued signal line is inheriting that simple signal line idea and it is extending it : instead of having one signal line, more lines depending on the current value of the indicator.
"Signal" line is calculated the following way :
When a certain level is crossed into the desired direction, the EMA of that value is calculated for the desired signal line
When that level is crossed into the opposite direction, the previous "signal" line value is simply "inherited" and it becomes a kind of a level
This way it becomes a combination of signal lines and levels that are trying to combine both the good from both methods.
In simple terms, DSL uses the concept of a signal line and betters it by inheriting the previous signal line's value & makes it a level.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included
Signals
Alerts
Related indicators
Zero-line Volatility Quality Index (VQI)
Volatility Quality Index w/ Pips Filtering
Variety Moving Average Waddah Attar Explosion (WAE)
***This indicator is tuned to Forex. If you want to make it useful for other tickers, you must change the pip filtering value to match the asset. This means that for BTC, for example, you likely need to use a value of 10,000 or more for pips filter.

T3 PPO [Loxx]T3 PPO is a percentage price oscillator indicator using T3 moving average. This indicator is used to spot reversals. Dark red is upward price exhaustion, dark green is downward price exhaustion.
What is Percentage Price Oscillator (PPO)?
The percentage price oscillator (PPO) is a technical momentum indicator that shows the relationship between two moving averages in percentage terms. The moving averages are a 26-period and 12-period exponential moving average (EMA).
The PPO is used to compare asset performance and volatility, spot divergence that could lead to price reversals, generate trade signals, and help confirm trend direction.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
VHF-Adaptive T3 iTrend [Loxx]VHF-Adaptive T3 iTrend is an iTrend indicator with T3 smoothing and Vertical Horizontal Filter Adaptive period input. iTrend is used to determine where the trend starts and ends. You'll notice that the noise filter on this one is extreme. Adjust the period inputs accordingly to suit your take and your backtest requirements. This is also useful for scalping lower timeframes. Enjoy!
What is VHF Adaptive Period?
Vertical Horizontal Filter (VHF) was created by Adam White to identify trending and ranging markets. VHF measures the level of trend activity, similar to ADX DI. Vertical Horizontal Filter does not, itself, generate trading signals, but determines whether signals are taken from trend or momentum indicators. Using this trend information, one is then able to derive an average cycle length.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included
Bar coloring
Alerts
Signals
Loxx's Expanded Source Types
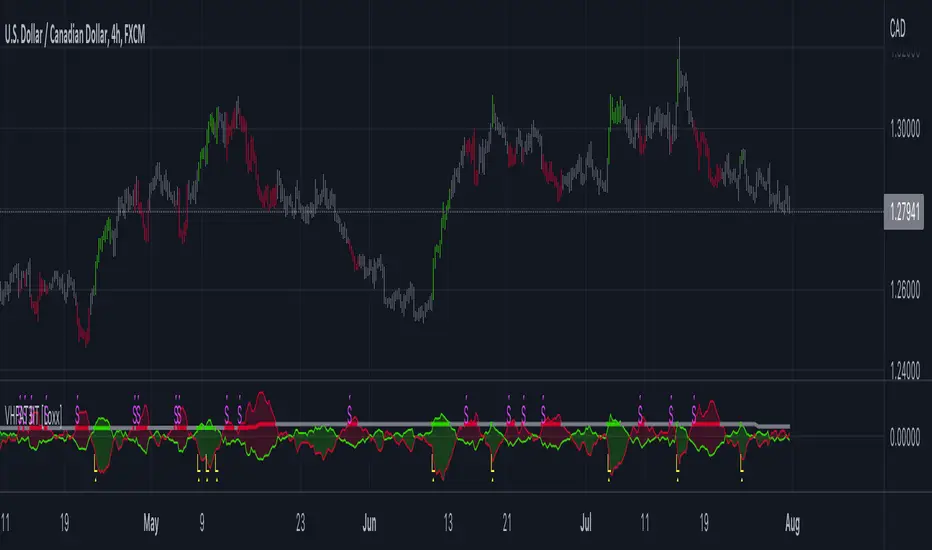
STD-Adaptive T3 Channel w/ Ehlers Swiss Army Knife Mod. [Loxx]STD-Adaptive T3 Channel w/ Ehlers Swiss Army Knife Mod. is an adaptive T3 indicator using standard deviation adaptivity and Ehlers Swiss Army Knife indicator to adjust the alpha value of the T3 calculation. This helps identify trends and reduce noise. In addition. I've included a Keltner Channel to show reversal/exhaustion zones.
What is the Swiss Army Knife Indicator?
John Ehlers explains the calculation here: www.mesasoftware.com
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types
T3 Velocity [Loxx]T3 Velocity is a simple velocity indicator using T3 moving average that uses gradient colors to better identify trends.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types

R-squared Adaptive T3 w/ DSL [Loxx]R-squared Adaptive T3 w/ DSL is the following T3 indicator but with Discontinued Signal Lines added to reduce noise and thereby increase signal accuracy. This adaptation makes this indicator lower TF scalp friendly.
What is R-squared Adaptive?
One tool available in forecasting the trendiness of the breakout is the coefficient of determination ( R-squared ), a statistical measurement.
The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average .
R-squared is used here to derive a T3 factor used to modify price before passing price through a six-pole non-linear Kalman filter.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts
EMA and FEMA Signla/DSL smoothing
Loxx's Expanded Source Types
Pips-Stepped, R-squared Adaptive T3 [Loxx]Pips-Stepped, R-squared Adaptive T3 is a a T3 moving average with optional adaptivity, trend following, and pip-stepping. This indicator also uses optional flat coloring to determine chops zones. This indicator is R-squared adaptive. This is also an experimental indicator.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
What is R-squared Adaptive?
One tool available in forecasting the trendiness of the breakout is the coefficient of determination (R-squared), a statistical measurement.
The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average.
R-squared is used here to derive a T3 factor used to modify price before passing price through a six-pole non-linear Kalman filter.
Included:
Bar coloring
Signals
Alerts
Flat coloring
R-squared Adaptive T3 [Loxx]R-squared Adaptive T3 is an R-squared adaptive version of Tilson's T3 moving average. This adaptivity was originally proposed by mladen on various forex forums. This is considered experimental but shows how to use r-squared adapting methods to moving averages. In theory, the T3 is a six-pole non-linear Kalman filter.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis. Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD, Momentum, Relative Strength Index) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA (simple moving average) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA(n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA.
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE/2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE/2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE/2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA, popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE/2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA(3) has lag 1, and EMA(11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA(3) through itself 5 times than if I just take EMA(11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA(3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA(7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA(n) = EMA(n) + EMA(time series - EMA(n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA. The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA(n) + EMA(time series - EMA(n))*.7;
This is algebraically the same as:
EMA(n)*1.7-EMA(EMA(n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD(n,v) = EMA(n)*(1+v)-EMA(EMA(n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA, and when v=1, GD is DEMA. In between, GD is a cooler DEMA. By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD(GD(GD(n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA(n)) to correct themselves. In Technical Analysis, these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types
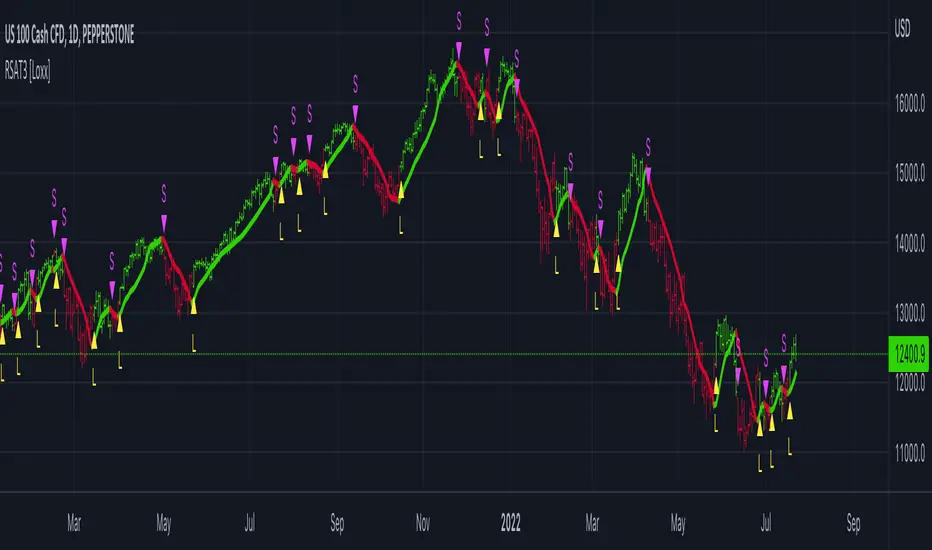
Drawdown RangeHello death eaters, presenting a unique script which can be used for fundamental analysis or mean reversion based trades.
Process of deriving this table is as below:
Find out ATH for given day
Calculate the drawdown from ATH for the day and drawdown percentage
Based on the drawdown percentage, increment the count of basket which is based on input iNumber of ranges . For example, if number of ranges is 5, then there will be 5 baskets. First basket will fit drawdown percentage 0-20% and each subsequent ones will accommodate next 20% range.
Repeat the process from start to last bar. Once done, table will plot how much percentage of days belong to which basket.
For example, from the below chart of NASDAQ:AAPL
We can deduce following,
Historically stock has traded within 1% drawdown from ATH for 6.59% of time. This is the max amount of time stock has stayed in specific range of drawdown from ATH.
Stock has traded at the drawdown range of 82-83% from ATH for 0.17% of time. This is the least amount of time the stock has stayed in specific range of drawdown from ATH.
At present, stock is trading 2-3% below ATH and this has happened for about 2.46% of total days in trade
Maximum drawdown the stock has suffered is 83%
Lets take another example of NASDAQ:TSLA
Stock is trading at 21-22% below ATH. But, historically the max drawdown range where stock has traded is within 0-1%. Now, if we make this range to show 20 divisions instead of 100, it will look something like this:
Table suggests that stock is trading about 20-25% below ATH - which is right. But, table also suggests that stock has spent most number of days within this drawdown range when we divide it by 20 baskets instad of 100. I would probably wait for price to break out of this range before going long or short. At present, it seems a stage ranging stage. I might think about selling PUTs or covered CALLs outside this range.
Similarly, if you look at AMEX:SPY , 36% of the time, price has stayed within 5% from ATH - makes it a compelling bull case!!
NYSE:BABA is trading at 50-55% below ATH - which is the most it has retraced so far. In general, it is used to be within 15-20% from ATH
NOW, Bit of explanation on input options.
Number of Ranges : Says how many baskets the drawdown map needs to be divided into.
Reference : You can take ATH as reference or chose a time window between which the highest need to be considered for drawdown. This can be useful for megacaps which has gone beyond initial phase of uncertainity. There is no point looking at 80% drawdown AAPL had during 1990s. More approriate to look at it post 2000s where it started making higher impact and growth.
Cumulative Percentage : When this is unchecked, percentage division shows 0-nth percentage instad of percentage ranges. For example this is how it looks on SPY:
We can see that SPY has remained within 6% from ATH for more than 50% of the time.
Hope this is helpful. Happy trading :)
PS: this can be used in conjunction with Drawdown-Price-vs-Fundamentals to pick value stocks at discounted price while also keeping an eye on range tendencies of it.
Thanks to @mattX5 for the ideas and discussion today :)

Hybrid Heiken AshiThis indicator displays real price candles colored by Heiken Ashi trend direction, giving you the noise reduction benefits of HA without the price distortion.
Key Features:
Real candles with HA-based coloring (see actual price action with trend smoothing)
Gradient coloring based on trend strength (darker = stronger trend)
Optional HA close line overlay
Transition markers when HA flips bullish/bearish
Higher timeframe HA background for multi-timeframe confluence
Optional HA ribbon (HA close vs HA EMA)
Info panel showing current HA status, strength, and HTF alignment
Built-in alerts for HA transitions and timeframe alignment
Use Case:
Ideal for traders who want Heiken Ashi's trend-following benefits without losing sight of real price levels for entries and exits. The strength gradient helps identify conviction moves vs weak trends. HTF background helps avoid counter-trend trades.
Settings:
All visual elements are toggleable. Customize colors, choose your higher timeframe, and enable only the features you need.
Luxy Sector & Industry RS AnalyzerEver wonder why some stocks soar while others in the same sector barely move? Or why your perfectly timed entry still loses money? Possibly the answer can be found in Relative Strength.
The Luxy Sector & Industry RS Analyzer solves a critical problem that most traders overlook: picking strong stocks in strong sectors AND strong industries . It's not enough for a stock to go up - you want stocks that are crushing their competition at both the sector AND industry level. This indicator does the heavy lifting by automatically comparing your stock against its sector ETF, industry ETF, the broader market, sector leader, and industry leader, giving you a complete multi-level picture of relative performance.
What makes this different?
- Automatic sector AND industry detection - no manual setup required
- Multi-level hierarchy analysis: Market → Sector → Industry → Stock
- Multi-timeframe analysis (1 month to 1 year) in one glance
- Industry ETF mapping (30+ industries covered)
- Clear 0-100 scoring system with letter grades (A+ to F)
- Works on stocks, crypto, forex, and commodities
- Real-time updates with anti-repaint protection
Think of it as your performance dashboard - instantly showing you if you're trading a champion or a laggard at every level of the market hierarchy.
METHODOLOGY & ATTRIBUTION
This indicator is based on classical Relative Strength (RS) analysis principles from technical analysis. RS methodology compares an asset's price performance against a benchmark to identify relative outperformance or underperformance. This concept has been used by professional traders and institutions for decades.
Key Concepts Used:
Relative Strength (RS) - Classical technical analysis concept measuring comparative performance
Multi-Level Hierarchy Analysis - Market → Sector → Industry → Stock comparison
Sector Rotation Analysis - Identifying which sectors are leading or lagging the market
Industry Rotation Analysis - Identifying which industries are leading within their sectors
Multi-period Performance Analysis - Evaluating strength across multiple timeframes
Beta Calculation - Standard statistical measure of volatility relative to a benchmark
DISCLAIMER: This indicator is for educational and informational purposes only. It should not be considered financial advice or a recommendation to buy or sell. Past performance does not guarantee future results. Trading involves risk and may not be suitable for all investors. Always do your own research and consult with a financial advisor before making investment decisions.
with all rows visible - capture when stock has strong RS score (70+) so users can see what a "good" setup looks like]
WHAT THE INDICATOR SHOWS
1. AUTOMATIC ASSET TYPE DETECTION
The indicator automatically identifies what you're analyzing and adjusts accordingly:
Stocks - Compares to sector ETF (XLK, XLF, XLV, etc.) and SPY
Crypto - Compares to Total Crypto Market Cap and Bitcoin
Forex - Compares to relevant currency index (DXY, EXY, etc.)
Commodities - Compares to Gold (GLD) as benchmark
Indices - Compares to broader market indices
How it works: The indicator reads your chart's asset type and ticker, then automatically maps it to the correct sector or benchmark. For stocks, it uses intelligent sector detection (looking at the sector field) to match you with the right sector ETF. For example:
- Technology stocks get compared to XLK (Technology Select Sector SPDR)
- Financial stocks get compared to XLF (Financial Select Sector SPDR)
- Healthcare stocks get compared to XLV (Health Care Select Sector SPDR)
This happens instantly when you add the indicator to any chart - no configuration needed.
2. SECTOR & MARKET BENCHMARKS
What is a Sector ETF?
A sector ETF is an exchange-traded fund that tracks a specific industry group. For example, XLK contains all major technology companies. By comparing your stock to its sector ETF, you can see if your stock is outperforming or underperforming its peers.
The indicator shows three key comparison points:
Stock vs Sector (Benchmark)
This tells you how your stock performs compared to companies in the same industry. Positive numbers mean your stock is beating the sector average. Negative numbers mean it's lagging behind.
Stock vs Market (SPY)
This shows performance against the broader S&P 500 index. This is important because even if a stock beats its sector, the entire sector might be weak. You want stocks that beat both their sector AND the market.
Sector vs Market
This reveals "sector rotation" - whether money is flowing into or out of this sector. When this number is positive, the whole sector is hot and leading the market. This is powerful because strong sectors tend to lift all boats, making it easier to find winners.
3. MULTI-PERIOD PERFORMANCE ANALYSIS
The indicator calculates performance across four timeframes simultaneously:
1 Month (1M) - Recent short-term momentum
3 Months (3M) - Medium-term trend strength
6 Months (6M) - Longer-term positioning
1 Year (1Y) - Full-cycle performance view
Why multiple periods matter:
A stock might look great over 1 month but terrible over 6 months - that's a red flag. The best stocks show consistent strength across all timeframes . When you see positive RS (Relative Strength) values across all four periods, you've found a stock with sustained outperformance.
Each row in the table shows:
- Raw performance percentage for that period
- RS value (the difference compared to benchmark)
- Color coding: Green for positive, red for negative, white for neutral
4. SECTOR LEADER COMPARISON
The indicator automatically identifies and compares your stock to the sector leader - the dominant stock in that industry.
Sector leaders by industry:
Technology: Apple (AAPL)
Healthcare: UnitedHealth (UNH)
Financial: JPMorgan Chase (JPM)
Energy: ExxonMobil (XOM)
Consumer Discretionary: Amazon (AMZN)
Consumer Staples: Walmart (WMT)
And more...
Why this matters:
Comparing to the leader shows you if you're trading a champion or a follower. If your stock consistently beats the sector leader, you've found something special. If it's lagging the leader, you might want to trade the leader instead.
Optional Custom Leader:
You can override the automatic leader and compare to any stock you choose. This is useful if you want to benchmark against a specific competitor or reference stock.
NEW! INDUSTRY ANALYSIS (STOCKS ONLY)
The indicator now provides multi-level analysis by automatically detecting and comparing your stock to its specific industry , not just the broad sector.
Why Industry matters:
Technology sector (XLK) contains many different industries: Software, Semiconductors, Hardware, etc. A software stock might beat the broad tech sector but lag behind other software companies. Industry analysis provides this granular view.
Industry ETF Mapping (30+ industries):
Software/Applications: IGV (iShares Software ETF)
Semiconductors: SMH (VanEck Semiconductor ETF)
Biotech: IBB (iShares Biotechnology ETF)
Pharmaceuticals: XPH (SPDR Pharmaceuticals ETF)
Banks: KBE (SPDR S&P Bank ETF)
Regional Banks: KRE (SPDR Regional Banking ETF)
Oil & Gas Exploration: XOP (SPDR Oil & Gas Exploration ETF)
Homebuilders: XHB (SPDR Homebuilders ETF)
Retail: XRT (SPDR S&P Retail ETF)
Aerospace & Defense: ITA (iShares U.S. Aerospace & Defense ETF)
And many more...
Industry Leader Mapping:
The indicator also identifies the leader within each industry:
Software: Microsoft (MSFT)
Semiconductors: NVIDIA (NVDA)
Biotech: Amgen (AMGN)
Pharmaceuticals: Eli Lilly (LLY)
Banks: JPMorgan (JPM)
Oil Exploration: ConocoPhillips (COP)
And more...
New Table Rows for Stocks:
Industry ETF Performance - How the specific industry performed (green background)
Industry Leader Performance - How the top stock in the industry performed
vs Industry RS - Your stock's outperformance vs its industry ETF
Industry vs Sector RS - Is this industry hot or cold within its sector?
vs Industry Leader RS - Your stock's performance vs the industry's best
Why this is powerful:
A stock that beats both its sector AND its industry is showing strength at every level. This indicates true relative strength, not just riding sector-wide momentum.
Optional Custom Industry:
You can override automatic detection for both Industry ETF and Industry Leader in settings.
5. RS SCORE & GRADING SYSTEM (0-100)
The heart of the indicator is the RS Score - a weighted calculation that distills all the performance data into one clear number from 0 to 100.
How the score is calculated:
FOR STOCKS (with Industry data):
The indicator splits the weight between Sector (60%) and Industry (40%):
SECTOR RS (60% of total weight):
1 Month RS: 24% weight (40% × 0.6)
3 Month RS: 18% weight (30% × 0.6)
6 Month RS: 12% weight (20% × 0.6)
1 Year RS: 6% weight (10% × 0.6)
INDUSTRY RS (40% of total weight):
1 Month RS: 16% weight (40% × 0.4)
3 Month RS: 12% weight (30% × 0.4)
6 Month RS: 8% weight (20% × 0.4)
1 Year RS: 4% weight (10% × 0.4)
FOR OTHER ASSETS (Crypto, Forex, Commodities):
Uses full 100% weight on benchmark:
1 Month RS: 40% weight
3 Month RS: 30% weight
6 Month RS: 20% weight
1 Year RS: 10% weight
It starts at 50 (neutral) and adds or subtracts points based on your asset's relative strength in each period.
Bonus points:
+5 points if the sector is outperforming the market (sector rotation is bullish)
+5 points if the industry is outperforming its sector (hot industry) - STOCKS ONLY
+5 points if RS momentum is improving (getting stronger over time)
-5 points if RS momentum is declining (getting weaker)
The final score is capped between 0-100.
Letter Grade System:
90-100: A+ - Elite performer, crushing the sector
85-89: A - Excellent, strong outperformer
80-84: A- - Very good, above average
75-79: B+ - Good, solid performer
70-74: B - Above average, decent strength
65-69: B- - Slightly above average
60-64: C+ - Average, neutral strength
55-59: C - Below average
50-54: C- - Weak, slight underperformance
45-49: D+ - Concerning weakness
40-44: D - Poor, significant underperformance
0-39: F - Failing, avoid this stock
What scores mean for trading:
- RS Score above 70: Strong stocks worth considering for long positions
- RS Score 50-70: Average stocks, better opportunities elsewhere
- RS Score below 50: Weak stocks, avoid or consider for shorts
6. CONSISTENCY SCORE
This metric shows what percentage of time periods show positive RS .
For STOCKS (with Industry data):
Counts both Sector RS periods AND Industry RS periods (up to 8 total periods):
- If a stock beats both sector and industry in all 4 periods each: Consistency = 100% (8/8)
- If it beats in 6 out of 8 total periods: Consistency = 75%
- If it beats in 4 out of 8 total periods: Consistency = 50%
For OTHER ASSETS:
Counts benchmark periods only (4 total):
- If it beats benchmark in all 4 periods (1M, 3M, 6M, 1Y): Consistency = 100%
- If it beats in 3 out of 4 periods: Consistency = 75%
- If it beats in 2 out of 4 periods: Consistency = 50%
Why consistency matters:
A high RS Score with low consistency might indicate a recent spike that could fade. The best stocks show both high RS Score AND high consistency - they're strong now AND have been strong historically at both the sector AND industry level.
Look for stocks with:
Consistency above 75%: Very reliable strength across all levels
Consistency 50-75%: Decent but check other metrics
Consistency below 50%: Weak or erratic, proceed with caution
7. BETA CALCULATION (Volatility Measure)
Beta measures how much more volatile your stock is compared to its sector.
Beta > 1.2 : High volatility - stock moves more aggressively than sector (marked as "High")
Beta 0.8-1.2 : Normal volatility - moves roughly in line with sector
Beta < 0.8 : Low volatility - stock is more stable than sector (marked as "Low")
Formula used:
Beta = Correlation(Stock, Sector) × (Standard Deviation of Stock / Standard Deviation of Sector)
This uses a 20-period calculation for reliability.
How to use Beta:
- High Beta stocks offer bigger gains but also bigger risks - good for aggressive traders
- Low Beta stocks are more defensive - good for conservative positions
- Match Beta to your risk tolerance and strategy
8. DAYS ABOVE/BELOW SECTOR
This tracks consecutive periods (bars) where your stock outperforms or underperforms its sector.
Days Above Sector:
Counts how many bars in a row your stock has beaten the sector.
10+ days: Strong sustained strength (shown in bright green)
5-9 days: Building momentum (shown in yellow)
1-4 days: Early strength (shown in white)
0 days: Not currently outperforming
Days Below Sector:
Counts how many bars in a row your stock has lagged the sector.
10+ days: Sustained weakness (shown in bright red)
5-9 days: Losing momentum (shown in orange)
1-4 days: Minor weakness (shown in white)
0 days: Not underperforming (this is good!)
Why this matters:
Long streaks show trend persistence. A stock with 15+ days above sector is riding strong momentum. A stock with 15+ days below sector is in a sustained downtrend relative to peers.
9. PRICE VS 52-WEEK HIGH
Shows where current price sits relative to its 52-week high (or equivalent for your timeframe).
95%+ (green) : Stock is near all-time highs - strong positioning
80-94% (yellow) : Stock is in a pullback but still relatively strong
Below 80% : Stock has pulled back significantly from highs
Why this matters:
The strongest stocks stay near their highs. When you see a stock with high RS Score AND price near 52W high, you've found a stock with institutional support and strong buying pressure.
10. RELATIVE VOLUME
Compares current volume to the 20-period average volume.
1.5x+ (green) : High volume - significant interest and participation
Around 1.0x : Average volume - normal trading activity
Below 1.0x : Low volume - less interest or inactive period
Why volume matters:
High relative volume confirms price moves. When a stock makes a strong move on 2x or 3x normal volume, it's more likely to sustain. Low volume moves are often just noise.
11. AVERAGE RS STRENGTH
This calculates the average absolute value of all RS readings across the four timeframes.
It shows the magnitude of divergence from the sector, regardless of direction. A high number means the stock moves very differently from its sector (could be much stronger or much weaker). A low number means it tracks closely with the sector.
High Average RS: Stock has strong character, moves independently
Low Average RS: Stock follows sector closely, lacks individual strength
12. SECTOR ROTATION SIGNAL
This indicator automatically detects when a sector is experiencing bullish rotation - meaning money is flowing into the sector and it's outperforming the broader market.
Condition for bullish rotation:
Sector must be beating SPY (market) in both 1-month AND 3-month periods.
Why this matters:
Stocks in hot sectors tend to perform better because they have tailwinds from sector-wide buying. When sector rotation is bullish and your stock has a high RS Score, you've found an ideal setup.
The indicator adds +5 bonus points to the RS Score when sector rotation is bullish.
13. MOMENTUM DETECTION
The indicator compares 1-month RS to 3-month RS to detect if momentum is improving or declining.
RS Momentum Improving: 1M RS is better than 3M RS - stock is getting stronger (adds +5 to score)
RS Momentum Declining: 1M RS is worse than 3M RS - stock is getting weaker (subtracts -5 from score)
Why momentum matters:
You want to catch stocks as momentum is building, not after it's already peaked. Improving momentum suggests the strength is accelerating, not fading.
14. OVERALL ASSESSMENT & RECOMMENDATION
The indicator provides two quick summary rows:
Overall Rating:
Based on grade and RS Score, you get an instant quality rating:
Strong Leader (A/A+) - Top tier stock, crushing it
Above Average (A-/B+) - Solid performer, better than most
Average (B/B-) - Middle of the pack
Below Average (C/C+) - Struggling, watch carefully
Underperformer (D/F) - Weak stock, underperforming badly
Trading Signal:
Combines multiple factors to give setup quality:
STRONG BUY SETUP - RS Score 70+, Consistency 75+, AND sector rotation bullish. This is the perfect storm - strong stock, consistent strength, hot sector.
BULLISH - RS Score 60+, Consistency 50+. Good quality stock worth considering.
NEUTRAL - RS Score 50+. Okay but not exciting, better opportunities exist.
WEAK - RS Score 40-49. Below average, risky.
AVOID - RS Score below 40. Stay away, too weak.
IMPORTANT: These are educational signals only, not financial advice. Always do your own analysis and risk management.
KEY FEATURES
1. AUTOMATIC EVERYTHING
- Auto-detects asset type (stock, crypto, forex, commodity, index)
- Auto-maps stocks to correct sector ETF (11 sectors covered)
- Auto-maps stocks to correct industry ETF (30+ industries covered)
- Auto-identifies sector leader AND industry leader
- Auto-selects appropriate market benchmark
- Zero configuration required - just add to chart
2. MULTI-ASSET SUPPORT
Works on all asset classes:
US Stocks - Compares to sector ETFs (XLK, XLF, XLV, etc.)
Crypto - Compares to Total Crypto Market Cap
Forex - Compares to currency indices (DXY, EXY, etc.)
Commodities - Compares to Gold (GLD)
Indices - Compares to broader market benchmarks
3. FLEXIBLE DISPLAY
9 table positions (top/middle/bottom, left/center/right)
4 size options (tiny, small, normal, large)
Show/hide table completely
Real-time indicator toggle
4. TIMEFRAME FLEXIBILITY
Choose your analysis timeframe:
Chart Timeframe (default) - Uses whatever timeframe your chart is on
Fixed: 1 Hour, 4 Hours, Daily, Weekly - Forces calculations to specific timeframe
This means you can be on a 5-minute chart but analyze RS on Daily timeframe if you prefer.
5. RS SCORE FILTERING
Set a minimum RS Score threshold to only see strong stocks:
Set to 0 - Shows all stocks
Set to 70 - Only displays stocks with RS Score 70+ (strong stocks only)
Warning message displays if stock doesn't meet threshold
Perfect for screening - quickly scan multiple charts and the indicator only shows tables for stocks that pass your quality filter.
6. CUSTOM LEADER COMPARISON
Override automatic leader detection:
Compare to any ticker you choose
Benchmark against specific competitors
Use your own reference stocks
7. COMPREHENSIVE TOOLTIPS
Every input parameter and every table row has detailed tooltips explaining:
What the metric measures
How to interpret the values
What thresholds indicate strength/weakness
Why it matters for trading
Hover over any element to learn - it's like having a trading coach built in.
8. SMART ALERTS
Built-in alert system for key events:
Divergence Alerts:
Get notified when your stock diverges significantly from its sector.
Bullish Divergence: Stock beating sector by threshold percentage
Bearish Divergence: Stock losing to sector by threshold percentage
Set your threshold (default 5%) - this determines how big a divergence triggers the alert.
RS Score Alerts:
Get notified when RS Score crosses your threshold:
Crossed Above: RS Score went from below to above your threshold (bullish)
Crossed Below: RS Score dropped from above to below threshold (bearish)
Set your threshold (default 70) to focus on strong stocks.
Sector Rotation Alert:
Fires when sector shows bullish rotation (outperforming market).
HOW TO USE THE INDICATOR
FOR SWING TRADERS:
1. Add indicator to your watchlist stocks
2. Look for RS Score 70+ with Consistency 75%+
3. Check if sector rotation is bullish (bonus!)
4. Verify price is near 52W high (95%+)
5. Wait for entry setup on your chart
6. Use stop loss below key support
Example Setup:
Stock shows:
- RS Score: 82 (Grade: A-)
- Consistency: 100% (strong across all periods)
- Sector Rotation: Bullish
- Price vs 52W High: 96%
- Days Above Sector: 12 days
- Relative Volume: 1.8x
This is a textbook strong stock in a hot sector near highs - ideal for swing long.
FOR POSITION TRADERS:
1. Focus on 6-month and 1-year RS values
2. Look for sustained outperformance (Consistency 75%+)
3. Prefer lower Beta stocks (less volatility)
4. Check Days Above Sector for trend persistence
5. Monitor RS Score monthly, exit if drops below 60
FOR ACTIVE TRADERS:
1. Use on intraday timeframes (1H or 4H)
2. Set RS Score filter to 60+ for quick screening
3. Enable Divergence Alerts
4. Watch for momentum improving signal
5. Higher Beta stocks offer more movement
FOR SHORT SELLERS:
1. Look for RS Score below 40 (Grade: D or F)
2. Check for declining momentum
3. Verify Days Below Sector is increasing (10+)
4. Sector rotation should be bearish
5. Price should be well off 52W high
WHAT MAKES A PERFECT SETUP:
The holy grail combination:
RS Score: 75+ (A- or better)
Consistency: 80%+ (strong across time - beats sector AND industry)
Sector Rotation: Bullish (hot sector)
Industry vs Sector: Positive (hot industry within sector)
Days Above Sector: 10+ (sustained strength)
Momentum: Improving (getting stronger)
Price vs 52W High: 90%+ (near highs)
Relative Volume: 1.5x+ (volume confirmation)
When you find this combination, you've located a stock with every advantage in its favor - strong at the stock level, industry level, AND sector level. That's multi-level confirmation of relative strength.
IMPORTANT NOTES
Data Reliability:
All calculations use lookahead=off for anti-repaint protection
Historical values will never change
Real-time indicator toggle only affects the visual clock icon, not data reliability
All security requests are properly configured to prevent future data leakage
Sector Mapping Notes:
Sector detection uses TradingView's sector field
Some stocks may not have sector data - indicator will adapt
Sector ETFs used: XLK, XLF, XLV, XLE, XLY, XLP, XLI, XLB, XLRE, XLU, XLC
Major market ETFs (SPY, QQQ, DIA) are treated as market benchmarks, not stocks
Multi-Asset Notes:
Crypto compares to CRYPTOCAP:TOTAL (total crypto market cap)
Forex compares to relevant currency index based on base currency
Commodities compare to Gold (GLD) as primary commodity benchmark
Custom leaders can be set for any asset type
FREQUENTLY ASKED QUESTIONS
Q: What does RS Score of 75 actually mean?
A: It means your stock is strongly outperforming its sector across multiple timeframes. The score is weighted toward recent performance (1-month gets 40% weight), so 75 indicates sustained relative strength with emphasis on current momentum.
Q: My stock has high RS Score but is going down. Why?
A: RS Score measures relative performance (vs sector/market), not absolute price direction. A stock can fall 5% while its sector falls 10% - that's still positive relative strength. In bear markets or sector corrections, high RS stocks often fall less than peers.
Q: Should I only trade stocks with RS Score above 70?
A: For long positions, yes - focus on 70+ scores. These stocks have proven they can beat their sector. However, for pairs trading or relative value plays, you might also short stocks with scores below 40 while longing stocks above 70.
Q: What if my stock doesn't have a sector?
A: The indicator handles this gracefully. If no sector is detected, it will compare directly to the market (SPY for stocks). Some rows may show N/A, but the indicator will still provide useful market-relative data.
Q: Why does the sector sometimes show N/A?
A: This happens when: 1) Your asset has no sector classification, 2) The stock IS the sector ETF itself, 3) You're analyzing a non-stock asset (crypto, forex, commodity). The indicator adapts by focusing on market-relative metrics instead.
Q: Can I use this on cryptocurrencies?
A: Yes! The indicator automatically detects crypto and compares to the Total Crypto Market Cap (CRYPTOCAP:TOTAL). You can also set a custom leader like Bitcoin (BTCUSD) to compare against the dominant crypto.
Q: What's the difference between RS Score and Consistency?
A: RS Score is the weighted average of how much you're beating the sector (magnitude). Consistency is what percentage of time periods show outperformance (reliability). You want both high - that means strong AND consistent.
Q: Do the alerts repaint?
A: No. All alerts fire only on bar close (barstate.isconfirmed) and use properly configured data with lookahead=off. Once an alert fires, it's final and won't change.
Q: What timeframe should I use?
A: For swing trading: Daily or Weekly. For day trading: 1H or 4H. For position trading: Weekly. Use "Chart Timeframe" mode and switch your chart timeframe to change the analysis period easily.
Q: Why is Days Above Sector showing 0?
A: This means your stock is not currently outperforming its sector. If Days Below Sector is also 0, it means the RS is exactly neutral (very rare). Check the actual RS values to see current standing.
Q: Can I compare to a different market benchmark than SPY?
A: Currently the indicator uses SPY (S&P 500) as the default US stock market benchmark. For crypto it uses CRYPTOCAP:TOTAL, for forex it uses currency indices, etc. The benchmark auto-adjusts based on asset type.
Q: What's a good Beta value?
A: It depends on your strategy. Aggressive traders prefer Beta above 1.2 (more volatility = bigger moves). Conservative traders prefer Beta 0.8-1.0 (more stable). Beta is neutral - it's about matching your risk tolerance.
Q: How often does the table update?
A: With Real-time Indicator enabled: Every tick (constant updates). With it disabled: Only on bar close. Either way, the underlying data is identical and non-repainting - the toggle only affects update frequency and the clock icon display.
Q: My stock is showing "AVOID" but it's up 50% this year. Is the indicator wrong?
A: Not necessarily. The indicator measures RELATIVE performance. If your stock is up 50% but the sector is up 100%, your stock is actually underperforming by 50%. The indicator helps you identify when you should switch to stronger stocks in the same sector.
Q: What does "Strong Buy Setup" really mean?
A: It means three things aligned: 1) RS Score above 70 (strong stock), 2) Consistency above 75% (reliable strength), 3) Sector rotation is bullish (hot sector). This combination historically correlates with stocks that continue outperforming. However, this is NOT financial advice - always do your own analysis.
Q: Can I use this for options trading?
A: Yes! High RS Score stocks make good candidates for call options (bullish bets) while low RS Score stocks may work for puts (bearish bets). Higher Beta stocks will have more volatile options (higher premiums but more movement).
Q: Why is my crypto showing N/A for sector?
A: Cryptocurrencies don't have "sectors" like stocks do. Instead, the indicator compares crypto to the total crypto market cap. This is normal and expected behavior.
Q: What happens if I'm analyzing an ETF?
A: If you're analyzing a sector ETF (like XLK), it will compare to SPY (market). If you're analyzing SPY itself, some comparisons won't be available (can't compare SPY to itself). The indicator intelligently adapts to avoid circular comparisons.
Q: What if my stock doesn't have industry data?
A: Not all stocks are mapped to specific industries (only 30+ major industries are covered). If no industry is detected, the indicator will still work using only sector analysis. The RS Score calculation will use 100% sector weight instead of the 60%/40% split.
Q: Why does Industry vs Sector matter?
A: Industry vs Sector shows if your specific industry is hot or cold within its broader sector. For example, Semiconductors (SMH) might be outperforming Technology sector (XLK) even though both are up. This helps you find not just strong sectors, but the strongest industries within those sectors.
Q: Can I disable Industry analysis?
A: Yes! In the "Industry Analysis" settings group, you can toggle off "Show Industry Analysis in Table" to hide all industry rows. However, even when hidden, industry data still contributes to the RS Score calculation for stocks.
Q: Why is my Consistency Score lower for stocks than other assets?
A: For stocks with industry data, Consistency counts 8 periods (4 Sector + 4 Industry periods) instead of just 4. This means the bar is higher - your stock needs to beat both sector AND industry consistently. A stock that beats sector in all 4 periods but lags industry in 2 periods will show 75% consistency (6/8), not 100%.
BEST PRACTICES
Use as a screening tool - Set RS Score filter to 70+ and quickly scan your watchlist. Only strong stocks will show the table.
Combine with technical analysis - RS Score tells you WHAT to trade, your chart tells you WHEN to enter.
Check multiple timeframes - Switch between Daily and Weekly to see if strength holds across different time horizons.
Monitor sector rotation - When sector goes from bearish to bullish rotation, it's often a great time to enter stocks in that sector.
Watch Industry vs Sector - Stocks in hot industries within hot sectors have double tailwinds. Prioritize Industry vs Sector positive values.
Pay attention to consistency - High RS Score with low consistency might be a spike that fades. Look for 70%+ consistency across BOTH sector and industry.
Use the leader comparison - If your stock consistently beats both sector leader AND industry leader, you may have found the next champion.
Watch days above/below sector - Long streaks (15+ days) indicate strong trends. Look for these in conjunction with high RS Score.
Set alerts on key stocks - Enable RS Score alerts at 70 threshold to get notified when watchlist stocks become strong.
Consider Beta for position sizing - Size smaller positions in high Beta stocks, larger in low Beta stocks for balanced risk.
Exit when RS Score drops - If a stock's RS Score falls below 60, consider reducing or exiting - the strength may be fading.
Leverage industry-level insight - If Industry ETF is weak but stock is strong, that's standout strength. If Industry is hot but stock is lagging, consider switching to the industry leader instead.
SETTINGS EXPLAINED
Display Settings:
Show Performance Table - Master on/off switch for the table
Table Position - 9 positions available (corners, edges, center)
Table Size - 4 sizes (tiny, small, normal, large) for different screen sizes
Timeframe Settings:
Chart Timeframe (recommended) - Dynamic, uses whatever chart TF you're on
Fixed Timeframes - Locks analysis to 1H, 4H, Daily, or Weekly regardless of chart
Filtering Settings:
Minimum RS Score - Set threshold (0-100) for displaying table
Show Warning - When enabled, displays message if stock doesn't meet filter
Alert Settings:
Divergence Alerts - Enable alerts when stock diverges from sector
Threshold (%) - How big a divergence triggers alert (default 5%)
RS Score Alerts - Enable alerts when RS Score crosses threshold
Threshold - What RS Score level triggers alert (default 70)
Sector Analysis Settings:
Use Custom Sector ETF - Override automatic sector ETF detection
Sector ETF Symbol - Enter any sector ETF to compare against
Use Custom Sector Leader - Override automatic sector leader detection
Sector Leader Symbol - Enter any ticker as sector leader
Industry Analysis Settings:
Use Custom Industry ETF - Override automatic industry ETF detection
Industry ETF Symbol - Enter specific industry ETF (e.g., IGV, SMH)
Use Custom Industry Leader - Override automatic industry leader detection
Industry Leader Symbol - Enter specific industry leader
Show Industry Analysis - Toggle all industry rows on/off
Display Settings:
Show Real-time Indicator - Toggle clock icon in header (doesn't affect data)
WHAT THIS INDICATOR DOESN'T DO
To set proper expectations:
Does NOT provide entry/exit signals - this is a strength analyzer, not a trading system
Does NOT predict future price movement - shows current and historical relative strength
Does NOT guarantee profits - strong RS stocks can still decline
Does NOT replace your own analysis - use as one tool among many
Does NOT work on stocks with no sector data - will adapt but some rows show N/A
This indicator is a decision support tool . It helps you identify which stocks are showing relative strength so you can make more informed trading decisions. You still need your own entry strategy, risk management, and position sizing rules.
SUPPORT & CONTACT
Questions or feedback? Use the comments section below or send me a message.
If you find this indicator useful, please give it a boost and share with other traders who might benefit from relative strength analysis.
FINAL REMINDER
This indicator is a tool for analyzing relative strength - it shows you which stocks are outperforming their sector and market. It does NOT provide financial advice or trade signals. Always conduct your own research, manage your risk appropriately, and consult with a financial advisor before making investment decisions.
Past performance of relative strength does not guarantee future results. Strong stocks can become weak, and sectors rotate in and out of favor. Use this indicator as part of a comprehensive trading strategy, not as a standalone decision-making system.
Trade smart, manage risk, and may your RS Scores stay high!
If you got till here and you like my work a BOOST and a COMMENT would make me happy

AO/AC Trading Zones Strategy [Skyrexio] Overview
AO/AC Trading Zones Strategy leverages the combination of Awesome Oscillator (AO), Acceleration/Deceleration Indicator (AC), Williams Fractals, Williams Alligator and Exponential Moving Average (EMA) to obtain the high probability long setups. Moreover, strategy uses multi trades system, adding funds to long position if it considered that current trend has likely became stronger. Combination of AO and AC is used for creating so-called trading zones to create the signals, while Alligator and Fractal are used in conjunction as an approximation of short-term trend to filter them. At the same time EMA (default EMA's period = 100) is used as high probability long-term trend filter to open long trades only if it considers current price action as an uptrend. More information in "Methodology" and "Justification of Methodology" paragraphs. The strategy opens only long trades.
Unique Features
No fixed stop-loss and take profit: Instead of fixed stop-loss level strategy utilizes technical condition obtained by Fractals and Alligator to identify when current uptrend is likely to be over. In some special cases strategy uses AO and AC combination to trail profit (more information in "Methodology" and "Justification of Methodology" paragraphs)
Configurable Trading Periods: Users can tailor the strategy to specific market windows, adapting to different market conditions.
Multilayer trades opening system: strategy uses only 10% of capital in every trade and open up to 5 trades at the same time if script consider current trend as strong one.
Short and long term trend trade filters: strategy uses EMA as high probability long-term trend filter and Alligator and Fractal combination as a short-term one.
Methodology
The strategy opens long trade when the following price met the conditions:
1. Price closed above EMA (by default, period = 100). Crossover is not obligatory.
2. Combination of Alligator and Williams Fractals shall consider current trend as an upward (all details in "Justification of Methodology" paragraph)
3. Both AC and AO shall print two consecutive increasing values. At the price candle close which corresponds to this condition algorithm opens the first long trade with 10% of capital.
4. If combination of Alligator and Williams Fractals shall consider current trend has been changed from up to downtrend, all long trades will be closed, no matter how many trades has been opened.
5. If AO and AC both continue printing the rising values strategy opens the long trade on each candle close with 10% of capital while number of opened trades reaches 5.
6. If AO and AC both has printed 5 rising values in a row algorithm close all trades if candle's low below the low of the 5-th candle with rising AO and AC values in a row.
Script also has additional visuals. If second long trade has been opened simultaneously the Alligator's teeth line is plotted with the green color. Also for every trade in a row from 2 to 5 the label "Buy More" is also plotted just below the teeth line. With every next simultaneously opened trade the green color of the space between teeth and price became less transparent.
Strategy settings
In the inputs window user can setup strategy setting:
EMA Length (by default = 100, period of EMA, used for long-term trend filtering EMA calculation).
User can choose the optimal parameters during backtesting on certain price chart.
Justification of Methodology
Let's explore the key concepts of this strategy and understand how they work together. We'll begin with the simplest: the EMA.
The Exponential Moving Average (EMA) is a type of moving average that assigns greater weight to recent price data, making it more responsive to current market changes compared to the Simple Moving Average (SMA). This tool is widely used in technical analysis to identify trends and generate buy or sell signals. The EMA is calculated as follows:
1.Calculate the Smoothing Multiplier:
Multiplier = 2 / (n + 1), Where n is the number of periods.
2. EMA Calculation
EMA = (Current Price) × Multiplier + (Previous EMA) × (1 − Multiplier)
In this strategy, the EMA acts as a long-term trend filter. For instance, long trades are considered only when the price closes above the EMA (default: 100-period). This increases the likelihood of entering trades aligned with the prevailing trend.
Next, let’s discuss the short-term trend filter, which combines the Williams Alligator and Williams Fractals. Williams Alligator
Developed by Bill Williams, the Alligator is a technical indicator that identifies trends and potential market reversals. It consists of three smoothed moving averages:
Jaw (Blue Line): The slowest of the three, based on a 13-period smoothed moving average shifted 8 bars ahead.
Teeth (Red Line): The medium-speed line, derived from an 8-period smoothed moving average shifted 5 bars forward.
Lips (Green Line): The fastest line, calculated using a 5-period smoothed moving average shifted 3 bars forward.
When the lines diverge and align in order, the "Alligator" is "awake," signaling a strong trend. When the lines overlap or intertwine, the "Alligator" is "asleep," indicating a range-bound or sideways market. This indicator helps traders determine when to enter or avoid trades.
Fractals, another tool by Bill Williams, help identify potential reversal points on a price chart. A fractal forms over at least five consecutive bars, with the middle bar showing either:
Up Fractal: Occurs when the middle bar has a higher high than the two preceding and two following bars, suggesting a potential downward reversal.
Down Fractal: Happens when the middle bar shows a lower low than the surrounding two bars, hinting at a possible upward reversal.
Traders often use fractals alongside other indicators to confirm trends or reversals, enhancing decision-making accuracy.
How do these tools work together in this strategy? Let’s consider an example of an uptrend.
When the price breaks above an up fractal, it signals a potential bullish trend. This occurs because the up fractal represents a shift in market behavior, where a temporary high was formed due to selling pressure. If the price revisits this level and breaks through, it suggests the market sentiment has turned bullish.
The breakout must occur above the Alligator’s teeth line to confirm the trend. A breakout below the teeth is considered invalid, and the downtrend might still persist. Conversely, in a downtrend, the same logic applies with down fractals.
In this strategy if the most recent up fractal breakout occurs above the Alligator's teeth and follows the last down fractal breakout below the teeth, the algorithm identifies an uptrend. Long trades can be opened during this phase if a signal aligns. If the price breaks a down fractal below the teeth line during an uptrend, the strategy assumes the uptrend has ended and closes all open long trades.
By combining the EMA as a long-term trend filter with the Alligator and fractals as short-term filters, this approach increases the likelihood of opening profitable trades while staying aligned with market dynamics.
Now let's talk about the trading zones concept and its signals. To understand this we need to briefly introduce what is AO and AC. The Awesome Oscillator (AO), developed by Bill Williams, is a momentum indicator designed to measure market momentum by contrasting recent price movements with a longer-term historical perspective. It helps traders detect potential trend reversals and assess the strength of ongoing trends.
The formula for AO is as follows:
AO = SMA5(Median Price) − SMA34(Median Price)
where:
Median Price = (High + Low) / 2
SMA5 = 5-period Simple Moving Average of the Median Price
SMA 34 = 34-period Simple Moving Average of the Median Price
The Acceleration/Deceleration (AC) Indicator, introduced by Bill Williams, measures the rate of change in market momentum. It highlights shifts in the driving force of price movements and helps traders spot early signs of trend changes. The AC Indicator is particularly useful for identifying whether the current momentum is accelerating or decelerating, which can indicate potential reversals or continuations. For AC calculation we shall use the AO calculated above is the following formula:
AC = AO − SMA5(AO) , where SMA5(AO)is the 5-period Simple Moving Average of the Awesome Oscillator
When the AC is above the zero line and rising, it suggests accelerating upward momentum.
When the AC is below the zero line and falling, it indicates accelerating downward momentum.
When the AC is below zero line and rising it suggests the decelerating the downtrend momentum. When AC is above the zero line and falling, it suggests the decelerating the uptrend momentum.
Now let's discuss the trading zones concept and how it can create the signal. Zones are created by the combination of AO and AC. We can divide three zone types:
Greed zone: when the AO and AC both are rising
Red zone: when the AO and AC both are decreasing
Gray zone: when one of AO or AC is rising, the other is falling
Gray zone is considered as uncertainty. AC and AO are moving in the opposite direction. Strategy skip such price action to decrease the chance to stuck in the losing trade during potential sideways. Red zone is also not interesting for the algorithm because both indicators consider the trend as bearish, but strategy opens only long trades. It is waiting for the green zone to increase the chance to open trade in the direction of the potential uptrend. When we have 2 candles in a row in the green zone script executes a long trade with 10% of capital.
Two green zone candles in a row is considered by algorithm as a bullish trend, but now so strong, that's the reason why trade is going to be closed when the combination of Alligator and Fractals will consider the the trend change from bullish to bearish. If id did not happens, algorithm starts to count the green zone candles in a row. When we have 5 in a row script change the trade closing condition. Such situation is considered is a high probability strong bull market and all trades will be closed if candle's low will be lower than fifth green zone candle's low. This is used to increase probability to secure the profit. If long trades are initiated, the strategy continues utilizing subsequent signals until the total number of trades reaches a maximum of 5. Each trade uses 10% of capital.
Why we use trading zones signals? If currently strategy algorithm considers the high probability of the short-term uptrend with the Alligator and Fractals combination pointed out above and the long-term trend is also suggested by the EMA filter as bullish. Rising AC and AO values in the direction of the most likely main trend signaling that we have the high probability of the fastest bullish phase on the market. The main idea is to take part in such rapid moves and add trades if this move continues its acceleration according to indicators.
Backtest Results
Operating window: Date range of backtests is 2023.01.01 - 2024.12.31. It is chosen to let the strategy to close all opened positions.
Commission and Slippage: Includes a standard Binance commission of 0.1% and accounts for possible slippage over 5 ticks.
Initial capital: 10000 USDT
Percent of capital used in every trade: 10%
Maximum Single Position Loss: -9.49%
Maximum Single Profit: +24.33%
Net Profit: +4374.70 USDT (+43.75%)
Total Trades: 278 (39.57% win rate)
Profit Factor: 2.203
Maximum Accumulated Loss: 668.16 USDT (-5.43%)
Average Profit per Trade: 15.74 USDT (+1.37%)
Average Trade Duration: 60 hours
How to Use
Add the script to favorites for easy access.
Apply to the desired timeframe and chart (optimal performance observed on 4h BTC/USDT).
Configure settings using the dropdown choice list in the built-in menu.
Set up alerts to automate strategy positions through web hook with the text: {{strategy.order.alert_message}}
Disclaimer:
Educational and informational tool reflecting Skyrex commitment to informed trading. Past performance does not guarantee future results. Test strategies in a simulated environment before live implementation
These results are obtained with realistic parameters representing trading conditions observed at major exchanges such as Binance and with realistic trading portfolio usage parameters.