Educational Inidicators - Ichimoku CloudThis indicator is part of the Indicator Educational Series, intended to help newer traders understand and interact with various indicators. The goal is to allow users to gain a stronger understanding of an indicator's underlying philosophy, and visually see how changes to an indicator's parameters affects the trades suggested by that indicator.
The scripts in this series are all open source, with the code broken up into logical section and notated so beginner users can also understand some PineScript fundamentals.
Please understand that no indicator presented in and of itself constitutes a complete trading strategy. Rather, this series is to help users determine which indicators make sense to them, and which ones to combine to create their own trading strategy. All material presented is purely for educational purposes.
Presented here is the Ichimoku Cloud.
The Ichimoku Cloud was developed by Goichi Hosada, and first published in the late 1960s. It is used by traders to understand price momentum, and help forecast future price movements.
The indicator at its core can be understood from four component parts:
The Conversion Line - An average of the highest and lowest price in a given window. Typically, this is a "fast" average, and as such, this line has the lowest period
The Base Line - An average of the highest and lowest price in a given window. This is a "slower" average than the Conversion Line, and as such should have a larger period than the Conversion Line
Leading Span A - The average of the Conversion Line and the Base Line
[*}Leading Span B - An average of the highest and lowest price in a given window. This is the "slowest" average of all three, and as such should have the largest period
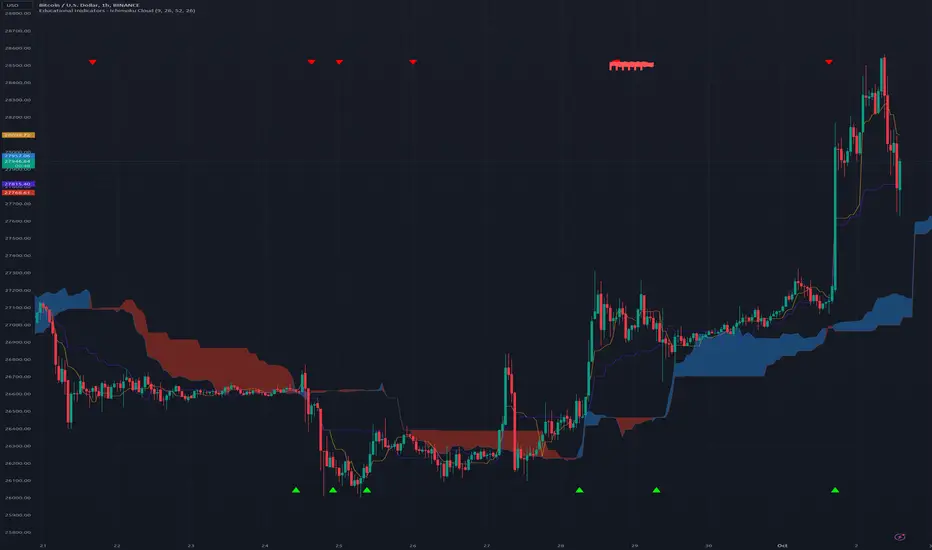
When plotted, the Conversion Line (orange by default), Base Line (purple by default), Leading Span A (blue by default), and Leading Span B (red by defaults) are all drawn on the chart along with the price candles. The area between the Leading Span A and Leading Span B lines are also shaded depending on which of the two lines is greater: whenever Leading Span A is greater the area is shaded positively (blue by default), whenever Leading Span B is greater the area is shaded negatively (red by defaults).
One interesting feature of the Ichimoku Cloud is that it drawn a certain number of candles forward. What this means is that where the cloud is drawn on the chart is reflective of prices that have occurred a number of candles in the past. This is done intentionally to help traders see how the current price is moving in relation to historical price movements on the asset.
See below for how the indicators look in their default colors on the chart
These indicators can then be used to start analyzing the price movement, and making trade decisions.
The first inference we can make is the momentum of the price. Since the lines are drawn from averages of varying speeds, the shaded area between the Leading Span lines can tell us whether the momentum is bullish (up) or bearish (down).
Whenever Leading Span A, the faster of the two lines, is above Leading Span B, that means that price is moving upward faster than it typically has, ergo we are in Bullish Momentum. On the chart, this is indicated in two ways:
The area is shaded positively (blue by default)
A green upward triangle is added to the chart to indicate where the momentum first turned Bullish
Whenever Leading Span A is below Leading Span B, that means that price is moving downward faster than it typically has, ergo we are in Bearish Momentum. On the chart, this is indicated in two ways:
The area is shaded negatively (red by default)
A red downward triangle is added to the chart to indicate where the momentum first turned Bearish
The next inference we can make is possible trading points. When we're in a period of momentum, as determined above, we know that price is going up or down, depending on the momentum we're in. We can then use the Conversion Line, Base Line, and the Price itself to confirm a good trade price.
When the asset is in Bullish Momentum, and the Conversion Line, our fastest average, is above the Base Line, our mid speed average, we know that the price is coming up quickly in the short term. When the Base Line and current Price are also above the cloud, then we have triple confirmation that price is going up, and we should enter a Long position. On the chart, this point is indicated with a green flag.
When the asset is in Bearish Momentum, and the Conversion Line is below the Base Line, we know that the price is going down quickly in the short term. When the Base Line and current Price are also below the cloud, then we have triple confirmation that price is going down, and we should enter a Short position. On the chart, this point is indicated with a red flag.
The script presented here also allows users to customize the various parameters of the Ichimoku Cloud, and visually see how analysis is affected by these changes. This is designed to allow users to modify parameters as they see fit, within certain constraints, to find the best set for them. The lines, cloud, and chart indicators will all update automatically with the users' inputs.
"如何用wind搜索股票的发行价和份数"に関するスクリプトを検索
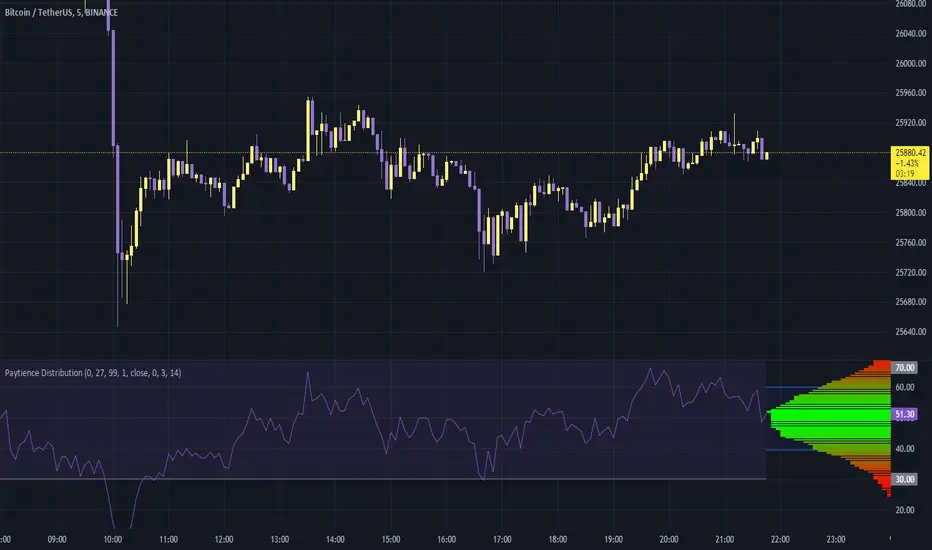
Paytience DistributionPaytience Distribution Indicator User Guide
Overview:
The Paytience Distribution indicator is designed to visualize the distribution of any chosen data source. By default, it visualizes the distribution of a built-in Relative Strength Index (RSI). This guide provides details on its functionality and settings.
Distribution Explanation:
A distribution in statistics and data analysis represents the way values or a set of data are spread out or distributed over a range. The distribution can show where values are concentrated, values are absent or infrequent, or any other patterns. Visualizing distributions helps users understand underlying patterns and tendencies in the data.
Settings and Parameters:
Main Settings:
Window Size
- Description: This dictates the amount of data used to calculate the distribution.
- Options: A whole number (integer).
- Tooltip: A window size of 0 means it uses all the available data.
Scale
- Description: Adjusts the height of the distribution visualization.
- Options: Any integer between 20 and 499.
Round Source
- Description: Rounds the chosen data source to a specified number of decimal places.
- Options: Any whole number (integer).
Minimum Value
- Description: Specifies the minimum value you wish to account for in the distribution.
- Options: Any integer from 0 to 100.
- Tooltip: 0 being the lowest and 100 being the highest.
Smoothing
- Description: Applies a smoothing function to the distribution visualization to simplify its appearance.
- Options: Any integer between 1 and 20.
Include 0
- Description: Dictates whether zero should be included in the distribution visualization.
- Options: True (include) or False (exclude).
Standard Deviation
- Description: Enables the visualization of standard deviation, which measures the amount of variation or dispersion in the chosen data set.
- Tooltip: This is best suited for a source that has a vaguely Gaussian (bell-curved) distribution.
- Options: True (enable) or False (disable).
Color Options
- High Color and Low Color: Specifies colors for high and low data points.
- Standard Deviation Color: Designates a color for the standard deviation lines.
Example Settings:
Example Usage RSI
- Description: Enables the use of RSI as the data source.
- Options: True (enable) or False (disable).
RSI Length
- Description: Determines the period over which the RSI is calculated.
- Options: Any integer greater than 1.
Using an External Source:
To visualize the distribution of an external source:
Select the "Move to" option in the dropdown menu for the Paytience Distribution indicator on your chart.
Set it to the existing panel where your external data source is placed.
Navigate to "Pin to Scale" and pin the indicator to the same scale as your external source.
Indicator Logic and Functions:
Sinc Function: Used in signal processing, the sinc function ensures the elimination of aliasing effects.
Sinc Filter: A filtering mechanism which uses sinc function to provide estimates on the data.
Weighted Mean & Standard Deviation: These are statistical measures used to capture the central tendency and variability in the data, respectively.
Output and Visualization:
The indicator visualizes the distribution as a series of colored boxes, with the intensity of the color indicating the frequency of the data points in that range. Additionally, lines representing the standard deviation from the mean can be displayed if the "Standard Deviation" setting is enabled.
The example RSI, if enabled, is plotted along with its common threshold lines at 70 (upper) and 30 (lower).
Understanding the Paytience Distribution Indicator
1. What is a Distribution?
A distribution represents the spread of data points across different values, showing how frequently each value occurs. For instance, if you're looking at a stock's closing prices over a month, you may find that the stock closed most frequently around $100, occasionally around $105, and rarely around $110. Graphically visualizing this distribution can help you see the central tendencies, variability, and shape of your data distribution. This visualization can be essential in determining key trading points, understanding volatility, and getting an overview of the market sentiment.
2. The Rounding Mechanism
Every asset and dataset is unique. Some assets, especially cryptocurrencies or forex pairs, might have values that go up to many decimal places. Rounding these values is essential to generate a more readable and manageable distribution.
Why is Rounding Needed? If every unique value from a high-precision dataset was treated distinctly, the resulting distribution would be sparse and less informative. By rounding off, the values are grouped, making the distribution more consolidated and understandable.
Adjusting Rounding: The `Round Source` input allows users to determine the number of decimal places they'd like to consider. If you're working with an asset with many decimal places, adjust this setting to get a meaningful distribution. If the rounding is set too low for high precision assets, the distribution could lose its utility.
3. Standard Deviation and Oscillators
Standard deviation is a measure of the amount of variation or dispersion of a set of values. In the context of this indicator:
Use with Oscillators: When using oscillators like RSI, the standard deviation can provide insights into the oscillator's range. This means you can determine how much the oscillator typically deviates from its average value.
Setting Bounds: By understanding this deviation, traders can better set reasonable upper and lower bounds, identifying overbought or oversold conditions in relation to the oscillator's historical behavior.
4. Resampling
Resampling is the process of adjusting the time frame or value buckets of your data. In the context of this indicator, resampling ensures that the distribution is manageable and visually informative.
Resample Size vs. Window Size: The `Resample Resolution` dictates the number of bins or buckets the distribution will be divided into. On the other hand, the `Window Size` determines how much of the recent data will be considered. It's crucial to ensure that the resample size is smaller than the window size, or else the distribution will not accurately reflect the data's behavior.
Why Use Resampling? Especially for price-based sources, setting the window size around 500 (instead of 0) ensures that the distribution doesn't become too overloaded with data. When set to 0, the window size uses all available data, which may not always provide an actionable insight.
5. Uneven Sample Bins and Gaps
You might notice that the width of sample bins in the distribution is not uniform, and there can be gaps.
Reason for Uneven Widths: This happens because the indicator uses a 'resampled' distribution. The width represents the range of values in each bin, which might not be constant across bins. Some value ranges might have more data points, while others might have fewer.
Gaps in Distribution: Sometimes, there might be no data points in certain value ranges, leading to gaps in the distribution. These gaps are not flaws but indicate ranges where no values were observed.
In conclusion, the Paytience Distribution indicator offers a robust mechanism to visualize the distribution of data from various sources. By understanding its intricacies, users can make better-informed trading decisions based on the distribution and behavior of their chosen data source.
Profitunity - Beginner [TC]This indicator aggregates the knowledges of the first level of the Trading Chaos approach by Bill Williams. It uses the Market Facilitation Index (MFI) in conjunction with the type of bar(candle) to generate strong long and strong short signals.
General information
Bars numeration
All bars or candles could be numbered with the following algorithm. If we divide the candle for 3 equal parts from high to low. The highest third have the number 1, the middle one - 2, the lowest one - 3. Hence we can define the first number as the number of the third where the price opened, second - where the price closed. For example, if the price opened at the highest third and closed at the lowest one this candle has the number 13.
Trend defining
Also candles could be divided into three groups according to the trend condition: uptrend, downtrend, sideways. If the middle of the candle's trading range is above the high of the previous candle - it's uptrend candle, if below the low of the previous candle - it's downtrend candle, sideways in other candles.
Profitunity windows
According to Bill Williams MFI has 4 windows - fake, green, fade and squat. I am not going to describe here the methodology of MFI, but one thing you should know that the most valuable windows are green and squat. Green state is an indication of the true move on the market. Squat the sign that the increase in volume have not triggered the trend continuation and reverse is about to happen.
How to use?
You can use this script as the helper in automatic defining the type of candle. Indicator shows only green (green candle color) and squat (red candle color) MFI states. Add script to any timeframe and asset chart to see labels.
The "strong long" label flashes when 3 conditions are met:
1. Squat candle
2. Candle number 13
3. Downtrend candle
"Strong short" label flashes when:
1. Squat candle
2. Candle number 31
3. Uptrend candle
This indicator helps to find the trend reversal points, can be used in conjunction with other TA tools to find the entry points.

Rolling MACDThis indicator displays a Rolling Moving Average Convergence Divergence . Contrary to MACD indicators which use a fix time segment, RMACD calculates using a moving window defined by a time period (not a simple number of bars), so it shows better results.
This indicator is inspired by and use the Close & Inventory Bar Retracement Price Line to create an MACD in different timeframes.
█ CONCEPTS
If you are not already familiar with MACD, so look at Help Center will get you started www.tradingview.com
The typical MACD, short for moving average convergence/divergence, is a trading indicator used in technical analysis of stock prices, created by Gerald Appel in the late 1970s. It is designed to reveal changes in the strength, direction, momentum, and duration of a trend in a stock's price.
The MACD indicator(or "oscillator") is a collection of three time series calculated from historical price data, most often the closing price. These three series are: the MACD series proper, the "signal" or "average" series, and the "divergence" series which is the difference between the two. The MACD series is the difference between a "fast" (short period) exponential moving average (EMA), and a "slow" (longer period) EMA of the price series. The average series is an EMA of the MACD series itself.
Because RMACD uses a moving window, it does not exhibit the jumpiness of MACD plots. You can see the more jagged MACD on the chart above. I think both can be useful to traders; up to you to decide which flavor works for you.
█ HOW TO USE IT
Load the indicator on an active chart (see the Help Center if you don't know how).
Time period
By default, the script uses an auto-stepping mechanism to adjust the time period of its moving window to the chart's timeframe. The following table shows chart timeframes and the corresponding time period used by the script. When the chart's timeframe is less than or equal to the timeframe in the first column, the second column's time period is used to calculate RMACD:
Chart Time
timeframe period
1min 🠆 1H
5min 🠆 4H
1H 🠆 1D
4H 🠆 3D
12H 🠆 1W
1D 🠆 1M
1W 🠆 3M
You can use the script's inputs to specify a fixed time period, which you can express in any combination of days, hours and minutes.
By default, the time period currently used is displayed in the lower-right corner of the chart. The script's inputs allow you to hide the display or change its size and location.
Minimum Window Size
This input field determines the minimum number of values to keep in the moving window, even if these values are outside the prescribed time period. This mitigates situations where a large time gap between two bars would cause the time window to be empty, which can occur in non-24x7 markets where large time gaps may separate contiguous chart bars, namely across holidays or trading sessions. For example, if you were using a 1D time period and there is a two-day gap between two bars, then no chart bars would fit in the moving window after the gap. The default value is 10 bars.
//
This indicator should make trading easier and improve analysis. Nothing is worse than indicators that give confusingly different signals.
I hope you enjoy my new ideas
best regards
Chervolino

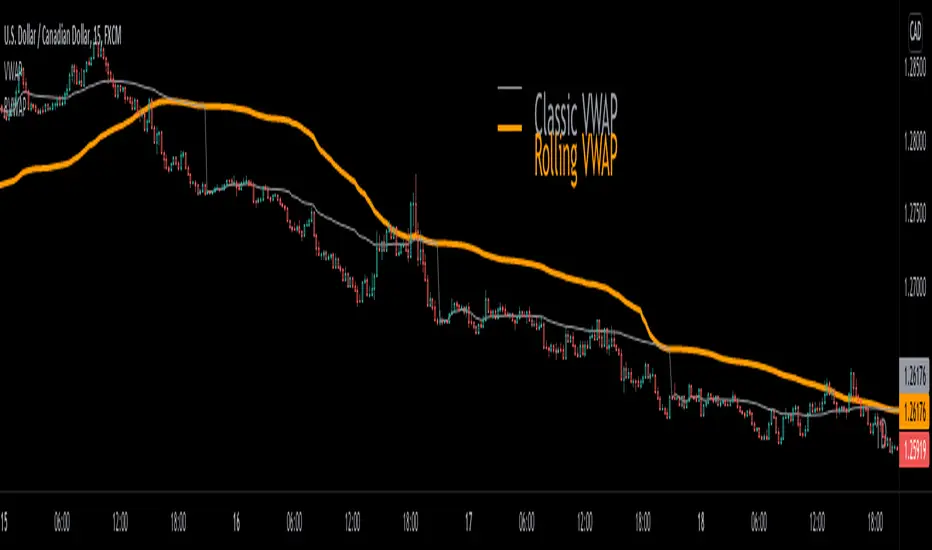
Rolling VWAP█ OVERVIEW
This indicator displays a Rolling Volume-Weighted Average Price. Contrary to VWAP indicators which reset at the beginning of a new time segment, RVWAP calculates using a moving window defined by a time period (not a simple number of bars), so it never resets.
█ CONCEPTS
If you are not already familiar with VWAP, our Help Center will get you started.
The typical VWAP is designed to be used on intraday charts, as it resets at the beginning of the day. Such VWAPs cannot be used on daily, weekly or monthly charts. Instead, this rolling VWAP uses a time period that automatically adjusts to the chart's timeframe. You can thus use RVWAP on any chart that includes volume information in its data feed.
Because RVWAP uses a moving window, it does not exhibit the jumpiness of VWAP plots that reset. You can see the more jagged VWAP on the chart above. We think both can be useful to traders; up to you to decide which flavor works for you.
█ HOW TO USE IT
Load the indicator on an active chart (see the Help Center if you don't know how).
Time period
By default, the script uses an auto-stepping mechanism to adjust the time period of its moving window to the chart's timeframe. The following table shows chart timeframes and the corresponding time period used by the script. When the chart's timeframe is less than or equal to the timeframe in the first column, the second column's time period is used to calculate RVWAP:
Chart Time
timeframe period
1min 🠆 1H
5min 🠆 4H
1H 🠆 1D
4H 🠆 3D
12H 🠆 1W
1D 🠆 1M
1W 🠆 3M
You can use the script's inputs to specify a fixed time period, which you can express in any combination of days, hours and minutes.
By default, the time period currently used is displayed in the lower-right corner of the chart. The script's inputs allow you to hide the display or change its size and location.
Minimum Window Size
This input field determines the minimum number of values to keep in the moving window, even if these values are outside the prescribed time period. This mitigates situations where a large time gap between two bars would cause the time window to be empty, which can occur in non-24x7 markets where large time gaps may separate contiguous chart bars, namely across holidays or trading sessions. For example, if you were using a 1D time period and there is a two-day gap between two bars, then no chart bars would fit in the moving window after the gap. The default value is 10 bars.
█ NOTES
If you are interested in VWAP indicators, you may find the VWAP Auto Anchored built-in indicator worth a try.
For Pine Script™ coders
The heart of this script's calculations uses the `totalForTimeWhen()` function from the ConditionalAverages library published by PineCoders . It works by maintaining an array of values included in a time period, but without a for loop requiring a lookback from the current bar, so it is much more efficient.
We write our Pine Script™ code using the recommendations in the User Manual's Style Guide .
Look first. Then leap.
Adaptive MA constructor [lastguru]Adaptive Moving Averages are nothing new, however most of them use EMA as their MA of choice once the preferred smoothing length is determined. I have decided to make an experiment and separate length generation from smoothing, offering multiple alternatives to be combined. Some of the combinations are widely known, some are not. This indicator is based on my previously published public libraries and also serve as a usage demonstration for them. I will try to expand the collection (suggestions are welcome), however it is not meant as an encyclopaedic resource, so you are encouraged to experiment yourself: by looking on the source code of this indicator, I am sure you will see how trivial it is to use the provided libraries and expand them with your own ideas and combinations. I give no recommendation on what settings to use, but if you find some useful setting, combination or application ideas (or bugs in my code), I would be happy to read about them in the comments section.
The indicator works in three stages: Prefiltering, Length Adaptation and Moving Averages.
Prefiltering is a fast smoothing to get rid of high-frequency (2, 3 or 4 bar) noise.
Adaptation algorithms are roughly subdivided in two categories: classic Length Adaptations and Cycle Estimators (they are also implemented in separate libraries), all are selected in Adaptation dropdown. Length Adaptation used in the Adaptive Moving Averages and the Adaptive Oscillators try to follow price movements and accelerate/decelerate accordingly (usually quite rapidly with a huge range). Cycle Estimators, on the other hand, try to measure the cycle period of the current market, which does not reflect price movement or the rate of change (the rate of change may also differ depending on the cycle phase, but the cycle period itself usually changes slowly).
Chande (Price) - based on Chande's Dynamic Momentum Index (CDMI or DYMOI), which is dynamic RSI with this length
Chande (Volume) - a variant of Chande's algorithm, where volume is used instead of price
VIDYA - based on VIDYA algorithm. The period oscillates from the Lower Bound up (slow)
VIDYA-RS - based on Vitali Apirine's modification of VIDYA algorithm (he calls it Relative Strength Moving Average). The period oscillates from the Upper Bound down (fast)
Kaufman Efficiency Scaling - based on Efficiency Ratio calculation originally used in KAMA
Deviation Scaling - based on DSSS by John F. Ehlers
Median Average - based on Median Average Adaptive Filter by John F. Ehlers
Fractal Adaptation - based on FRAMA by John F. Ehlers
MESA MAMA Alpha - based on MESA Adaptive Moving Average by John F. Ehlers
MESA MAMA Cycle - based on MESA Adaptive Moving Average by John F. Ehlers, but unlike Alpha calculation, this adaptation estimates cycle period
Pearson Autocorrelation* - based on Pearson Autocorrelation Periodogram by John F. Ehlers
DFT Cycle* - based on Discrete Fourier Transform Spectrum estimator by John F. Ehlers
Phase Accumulation* - based on Dominant Cycle from Phase Accumulation by John F. Ehlers
Length Adaptation usually take two parameters: Bound From (lower bound) and To (upper bound). These are the limits for Adaptation values. Note that the Cycle Estimators marked with asterisks(*) are very computationally intensive, so the bounds should not be set much higher than 50, otherwise you may receive a timeout error (also, it does not seem to be a useful thing to do, but you may correct me if I'm wrong).
The Cycle Estimators marked with asterisks(*) also have 3 checkboxes: HP (Highpass Filter), SS (Super Smoother) and HW (Hann Window). These enable or disable their internal prefilters, which are recommended by their author - John F. Ehlers. I do not know, which combination works best, so you can experiment.
Chande's Adaptations also have 3 additional parameters: SD Length (lookback length of Standard deviation), Smooth (smoothing length of Standard deviation) and Power (exponent of the length adaptation - lower is smaller variation). These are internal tweaks for the calculation.
Length Adaptaton section offer you a choice of Moving Average algorithms. Most of the Adaptations are originally used with EMA, so this is a good starting point for exploration.
SMA - Simple Moving Average
RMA - Running Moving Average
EMA - Exponential Moving Average
HMA - Hull Moving Average
VWMA - Volume Weighted Moving Average
2-pole Super Smoother - 2-pole Super Smoother by John F. Ehlers
3-pole Super Smoother - 3-pole Super Smoother by John F. Ehlers
Filt11 -a variant of 2-pole Super Smoother with error averaging for zero-lag response by John F. Ehlers
Triangle Window - Triangle Window Filter by John F. Ehlers
Hamming Window - Hamming Window Filter by John F. Ehlers
Hann Window - Hann Window Filter by John F. Ehlers
Lowpass - removes cyclic components shorter than length (Price - Highpass)
DSSS - Derivation Scaled Super Smoother by John F. Ehlers
There are two Moving Averages that are drown on the chart, so length for both needs to be selected. If no Adaptation is selected ( None option), you can set Fast Length and Slow Length directly. If an Adaptation is selected, then Cycle multiplier can be selected for Fast and Slow MA.
More information on the algorithms is given in the code for the libraries used. I am also very grateful to other TradingView community members (they are also mentioned in the library code) without whom this script would not have been possible.

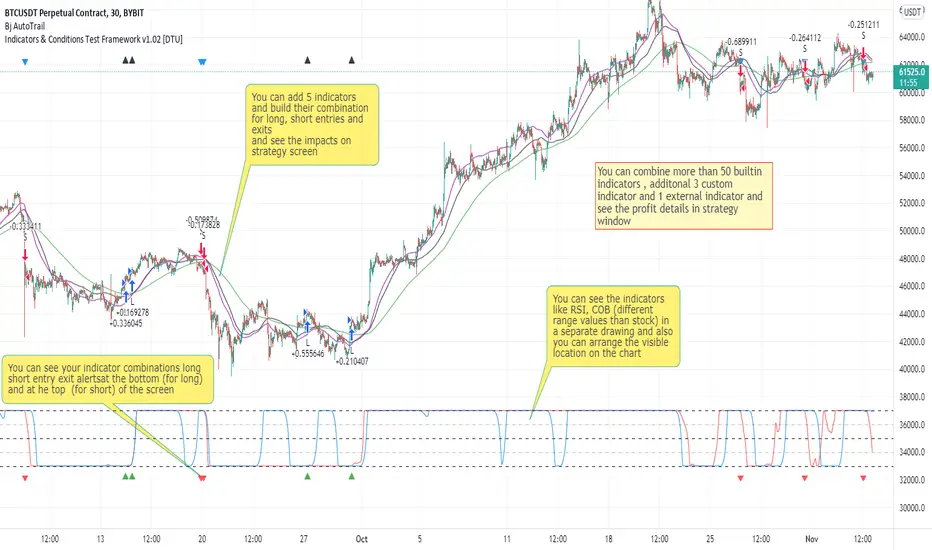
Indicators & Conditions Test Framework [DTU]Hello All,
This script is a framework to build strategies by combining indicators and conditions (long, short, exits). You are able to analyze your strategies in realtime by changing the input parameters related to indicators, conditions and their combinations.
OVERVIEW
With this Study/Strategy framework, you will be able to create strategy conditions, display them on the chart, and test them using existing indicators as well as external and custom indicators that you can add.
The main purpose of the Framework is to choose your indicators to be used in the conditions and test your strategy by producing your "Long, short, Exit long, Exit short" combinations.
Although may be, it can be a bit difficult and complicated at first start, but you can understand the logic on its use in a very short time.
Notes:
I removed external links off descriptive images and video to be comply with Trading view violation House Rules
Since I am new in the community and still trying to understand the pine script language I can make errors and violations on my script. Please Inform me on any issue that I made..
HOW TO
STEP 1: SETTINGS ______________________________________________________________________________________________________
SOURCE, TIMEFRAME, SECURITY
Select the Source, timeframe and Secure type that your indicators will use.
Here, the Secure entry consists of 3 parts and the f_security function is used to determine it.
a)Secure
This option is defined as reducing repaint in tradingview calculations as much as possible. The following function is used.
request.security(_symbol, _res, _src , lookahead=barmerge.lookahead_on)
b)Semi Secure
While this option can reduce repaint in tradingview calculations as much as possible, it is less secure. The following function is used.
request.security(_symbol, _res, _src )
c)Repaint
This option turns on the repaint feature. The following function is used.
request.security(_symbol, _res, _src ) : na
Ind Source:
You can the source that indicators will use their own calculations
Ext Source:
You can import external Indicator sources from here . It appears on condition/combination area as "EXT".
To export the External indicator plot it with a title. It will be visible in source dropdown input
PERIOD , ALERTS...
Period:
Determine your strategy testing period by selecting start and end date/time
(!!! According to your tradingview subscription, it takes the last 5000, 10000.. bars.
The extra bar option may cause problems such as not appearing in the calculations or errors).
Plot Alerts:
Plot condition result as alerts arrows on the chart's bottom for "LONG" and the top for "SHORT" entries, exits
Close on opposite:
When selected, a long entry gets closed when a short entry opens and vice versa
Show Profit:
It appears if script is in strategy mode (not in study) this can display current or open profit for better reanalyzing your strategy entry exit points. (Currently under development)
PLOT TYPE OPERATIONS
This option has 4 entries
a) Mult
Sets the multiplier for the selected Plot Type (stochastic, Percentrank, Org Range (-1,1) ) except for "Original" in the range (-1,1).
EXAMPLE: When 1000 is selected, the indicator in the range of (-1,1) will appear in the range of (-1000, 1000) on the screen.
b) Shift
It determines the shift that will appear on the screen for the selected Plot Type (stochastic, Percentrank,Org Range (-1,1) ) in the range (-1,1) other than "Original".
EXAMPLE: When Shift:35000 and mult:1000 are selected, the indicator will appear in the range (34000, 36000) on the screen.
c) Smooth
This option (only for Stochastic & PercentRank) allows to smooth the indicator to be displayed.
Here, tradinview ta.swma function is used.
b) hline
Adjusts the horizontal lines to appear on the screen according to the mult factor for the range (-1,1)
The lines represent the values (-1, -05, 0, 05, 1)
STEP 2: INDICATORS ______________________________________________________________________________________________________
You need to choose indicators that you can use in strategy conditions.
Here, the indicators come from the dturkuler/lib_Indicators_DT open script library defined in the code
In addition, you can add the indicators that you will create in the area defined in the code to this list..
You can also import external indicators and test them with other variables on the system..
You can choose a maximum of 5 indicators that you can use in total. (can be increased in new versions)
Indicators are categorized in 3 main sections
Indicator Selection:
You can select your indicators from this area
a)Moving Averages
These are indicators such as EMA, SMA that you can show on the stock. They come from the library.
These indicators are fed from Settings/source. Only the length value can be used as a parameter.
In addition, line colors can be changed..
As of now, there are 28 indicators in the library in total and 5 indicators are left as future use for this field for now.
b)Other Indicators
These are different indicators from the stock value such as RSI, COG. They come from the library. These indicators are fed from Settings/source.
Only the length value can be used as a parameter. In addition, line colors can be changed.
As of now, there are 24 indicators in the library in total and 5 indicators are left as a future use for this field for now.
c)Custom Indicators
These indicators are the ones you can create by programming yourself in the source code..
The area at the bottom of the settings screen is reserved for the parameters of this type of indicators.
Indicator Length:
You can update your selected indicator length value from here. (Not: it doesn't work for custom indicators since they have their parameter on cust. Ind. input screen )
Indicator Plot Type:
Next to the indicators, there is an input selection field about how they will be displayed on the screen.
a)Original
The indicator is displayed on the screen with its current values. It is an ideal solution for displaying moving average indicators such as (EMA, SMA) over current stock.
Since the values of indicators such as (RSI, COB) are low (-100,100 : -1.1), they appear at the bottom of the screen and make analysis difficult.
For this reason, other options may be more suitable for these.
b)Stochastic
The indicator is displayed on the screen with stochastic calculation in the range of -1.1.
It uses the stochastic(50) calculation method to spread indicators such as (RSI, COB) over the range (-1,1).
Indicators in this selection can be fixed and monitored under stock on the screen with the parameters under the Plot Type section.
You can see the original values of the relevant indicator on the Data Window screen.
(!!! Do not use the values on the chart in your condition calculations. Instead, get the values from Data Window)
c)PercentRank
The indicator is displayed on the screen with stochastic calculation in the range of -1.1. .
Since the values of indicators such as (RSI, COB) are low (-100,100 : -1.1), they appear at the bottom of the screen and make analysis difficult.
Indicators in this selection can be fixed and monitored under stock on the screen with the parameters under the Plot Type section.
You can see the original values of the relevant indicator on the Data Window screen
((!!! Do not use the values on the chart in your condition calculations. Instead, get the values from Data Window)
d)Org Range (-1,1)
If your indicator is in the range of -1.1, your indicator will be displayed on the screen with its original calculation in the range of -1.1.
Indicators in this selection can be fixed and monitored under stock on the screen with the parameters under the Plot Type section.
You can see the original values of the relevant indicator on the Data Window screen.
(!!! Do not use the values on the chart in your fitness calculations. Instead, get the values from Data Window)
STEP 2 NOTES:
STEP 3: CONDITIONS ______________________________________________________________________________________________________
After choosing the indicators you will use in the conditions, you move on to the "CONDITIONS" section.
There are 4 conditions type here.
• LONG ENTRY CONDITION
• SHORT ENTRY CONDITION
• LONG CLOSE CONDITION
• SHORT CLOSE CONDITION
The use of each condition is the same.
There are 3 combinations you can use in each condition. (can be increased in new versions)
a)COMBINATIONS
There are 3 combinations you can use in each condition. (can be increased in new versions)
Each combination are build from 4 parts
1)1st Indicator
If set to "NONE" this combination will not be used on calculations. You can select
IND1-5: from indicators (See above),
EXT: value from externally imported indicator
Stock built-in values: close, open...
2)Operator
Selected Operator compares 1st Indicator with the 2nd one. You can select different operators such as
crossover, crossunder, cross,>,<,=....
3)2nd Indicator
This indicator will be compared with the 1st one via selected Operator. You can select
IND1-5: from indicators (See above),
VALUE: a float value defined in the combinations value parameter
EXT: value from externally imported indicator
Stock builtin values: close,open...
4)Value
When the 2nd indicator field is "VALUE", value area compares the entered value.
ex: 1st indicator="open", op=">", 2nd indicator="VALUE", value=3000.12 means is(close>3000.12)
In other conditions, it compares the previous values of the indicator.
ex: 1st indicator="open", op=">" 2nd indicator is "close" and value is 2 means is(open>close )
EXAMPLES:
indicator 1= "IND1", Operator=">", indicator 2= "IND2" => is(IND1>IND2)
indicator 1= "IND1", Operator=">", indicator 2= "VALUE", "0.1" => is(IND1>0.9)
indicator 1= "IND2", Operator="crossover", indicator 2= "IND1" => is(IND2 crossover IND1) : like a=ta.crossover(IND2, IND1)
indicator 1= "IND1", Operator="<", indicator 2= "close" => is(IND1>close)
indicator 1= "IND1", Operator="<", indicator 2= "EXT" => is(IND1>EXT) , EXT mean external imported indicator that define on settings section
indicator 1= "IND1", Operator="<", indicator 2= "IND1", Value="1" => is (IND1>IND1 )
b)JOIN COMBINATIONS
Each combination in Condition is compared with the next one via JOIN operator
The join operator can be selected as AND or OR.
Examples:
1st combination= is(IND1>0.9) true
2nd combination= is(IND2 crossover IND1) false
1st combination "AND" 2ndcombination" => false (is(IND1>0.9) AND is(IND2 crossover IND1))
1st combination "OR" 2nd combination" => true (is(IND1>0.9) OR is(IND2 crossover IND1))
STEP 3 NOTES:
When the 2nd indicator field is "VALUE", value area compares the entered value. In other conditions, it compares the previous values of the indicator.
In cases where "VALUE" is not selected, integer values must be entered in this field. (float should not be entered. ie 1, 2 should be entered)
!!!If the 1st indicator is "NONE" in the combination, that combination is cancelled.
Each combination returns true/false, allowing the selected value to be compared with another value
Example: EMA(21)>EMA(50) returns true under all conditions or (EMA(21) crossover EMA(50)) returns true when passed.
You can use , Value of 5 indicators (IND1-IND5) or (VALUE) that you have defined in combinations or import indicator (EXT) or stock values (close, open, high...) in your calculations.
combination Compares the 1st indicator with 2nd indicator via the operator.
STEP 4: CUSTOM INDICATORS ______________________________________________________________________________________________________
There is an area in the code for designing Custom Indicators.
Here you can design your own indicators and use them in the framework.
You can also create unlimited parameters for your indicators in the SETTINGS custom indicator field.
For now, only 3 Custom indicators have been defined.
Examples are entered in the code for custom indicators.
STEP 4 NOTES:
Including / updating custom to the code is explained in the source code
• LIMITATIONS:
!!! According to your tradingview subscription, it takes the last 5000, 10000.. bars. More bar options may cause problems such as not appearing in the calculations or errors.
• RAMBLINGS:
• NOTES [ /i]
This Script can be used as an indicator if the last strategy parts in the code are commented out and converted to the initial strategy study.
It was originally prepared for my use with my own strategy framework and has export functions accordingly.
When integrated to my own strategy framework it brings many more features over strategy definition of trades.
• TODO [ /i]
TODO: Add tooltips to the settings screen
TODO: Add double triple, Quatr factor for all indicators (convert any indicator to factor2-4 facotr. ex: EMA to DEMA, TEMA, QEMA...)
TODO: Add factorized Fibo avg range indicator (good for trend definition and entry exit points)
TODO: Add bands to the indicator and conditions
TODO: Add debug window for exporting indicator's parameters
TODO: Add isRising(value) isFalling(value), is...(value) .... to combinations (they can be used as custom indicator also
TODO: Reassess condition entry screen for user friendly GUI
TODO: Increase # conditions from 3 to 4
TODO: Reassess strategy entries, exit and close (should be improved)
TODO: Add Alerts, Condiional alerts for indicator (study) part
TODO: Create export function v3 for Pinecoders Indicator framework
• THANKS:
For Pine script format docs RicardoSantos .
For Pine script coding standards Pinecoders .
For moving average script used on library s RodrigoKazuma .
Optimized Linear Regression ChannelReturn a linear regression channel with a window size within the range (min, max) such that the R-squared is maximized, this allows a better estimate of an underlying linear trend, a better detection of significant historical supports and resistance points, and avoid finding a good window size manually.
Settings
Min : Minimum window size value
Max : Maximum window size value
Mult : Multiplicative factor for the rmse, control the channel width.
Src : Source input of the indicator
Details
The indicator displays the specific window size that maximizes the R-squared at the bottom of the lower channel.
When optimizing we want to find parameters such that they maximize or minimize a certain function, here the r-squared. The R-squared is given by 1 minus the ratio between the sum of squares (SSE) of the linear regression and the sum of squares of the mean. We know that the mean will always produce an SSE greater or equal to the one of the linear regression, so the R-squared will always be in a (0,1) range. In the case our data has a linear trend, the linear regression will have a better fit, thus having a lower SSE than the SSE of the mean, has such the ratio between the linear regression SSE and the mean SSE will be low, 1 minus this ratio will return a greater result. A lower R-squared will tell you that your linear regression produces a fit similar to the one produced by the mean. The R-squared is also given by the square of the correlation coefficient between the dependent and independent variables.
In pinescript optimization can be done by running a function inside a loop, we run the function for each setting and keep the one that produces the maximum or minimum result, however, it is not possible to do that with most built-in functions, including the function of interest, correlation , as such we must recreate a rolling correlation function that can be used inside loops, such functions are generally loops-free, this means that they are not computed using a loop in the first place, fortunately, the rolling correlation function is simply based on moving averages and standard deviations, both can be computed without using a loop by using cumulative sums, this is what is done in the code.
Note that because the R-squared is based on the SSE of the linear regression, maximizing the R-squared also minimizes the linear regression SSE, another thing that is minimized is the horizontality of the fit.
In the example above we have a total window size of 27, the script will try to find the setting that maximizes the R-squared, we must avoid every data points before the volatile bearish candle, using any of these data points will produce a poor fit, we see that the script avoid it, thus running as expected. Another interesting thing is that the best R-squared is not always associated to the lowest window size.
Note that optimization does not fix core problems in a model, with the linear regression we assume that our data set posses a linear trend, if it's not the case, then no matter how many settings you use you will still have a model that is not adapted to your data.

Adaptive Genesis Engine [AGE]ADAPTIVE GENESIS ENGINE (AGE)
Pure Signal Evolution Through Genetic Algorithms
Where Darwin Meets Technical Analysis
🧬 WHAT YOU'RE GETTING - THE PURE INDICATOR
This is a technical analysis indicator - it generates signals, visualizes probability, and shows you the evolutionary process in real-time. This is NOT a strategy with automatic execution - it's a sophisticated signal generation system that you control .
What This Indicator Does:
Generates Long/Short entry signals with probability scores (35-88% range)
Evolves a population of up to 12 competing strategies using genetic algorithms
Validates strategies through walk-forward optimization (train/test cycles)
Visualizes signal quality through premium gradient clouds and confidence halos
Displays comprehensive metrics via enhanced dashboard
Provides alerts for entries and exits
Works on any timeframe, any instrument, any broker
What This Indicator Does NOT Do:
Execute trades automatically
Manage positions or calculate position sizes
Place orders on your behalf
Make trading decisions for you
This is pure signal intelligence. AGE tells you when and how confident it is. You decide whether and how much to trade.
🔬 THE SCIENCE: GENETIC ALGORITHMS MEET TECHNICAL ANALYSIS
What Makes This Different - The Evolutionary Foundation
Most indicators are static - they use the same parameters forever, regardless of market conditions. AGE is alive . It maintains a population of competing strategies that evolve, adapt, and improve through natural selection principles:
Birth: New strategies spawn through crossover breeding (combining DNA from fit parents) plus random mutation for exploration
Life: Each strategy trades virtually via shadow portfolios, accumulating wins/losses, tracking drawdown, and building performance history
Selection: Strategies are ranked by comprehensive fitness scoring (win rate, expectancy, drawdown control, signal efficiency)
Death: Weak strategies are culled periodically, with elite performers (top 2 by default) protected from removal
Evolution: The gene pool continuously improves as successful traits propagate and unsuccessful ones die out
This is not curve-fitting. Each new strategy must prove itself on out-of-sample data through walk-forward validation before being trusted for live signals.
🧪 THE DNA: WHAT EVOLVES
Every strategy carries a 10-gene chromosome controlling how it interprets market data:
Signal Sensitivity Genes
Entropy Sensitivity (0.5-2.0): Weight given to market order/disorder calculations. Low values = conservative, require strong directional clarity. High values = aggressive, act on weaker order signals.
Momentum Sensitivity (0.5-2.0): Weight given to RSI/ROC/MACD composite. Controls responsiveness to momentum shifts vs. mean-reversion setups.
Structure Sensitivity (0.5-2.0): Weight given to support/resistance positioning. Determines how much price location within swing range matters.
Probability Adjustment Genes
Probability Boost (-0.10 to +0.10): Inherent bias toward aggressive (+) or conservative (-) entries. Acts as personality trait - some strategies naturally optimistic, others pessimistic.
Trend Strength Requirement (0.3-0.8): Minimum trend conviction needed before signaling. Higher values = only trades strong trends, lower values = acts in weak/sideways markets.
Volume Filter (0.5-1.5): Strictness of volume confirmation. Higher values = requires strong volume, lower values = volume less important.
Risk Management Genes
ATR Multiplier (1.5-4.0): Base volatility scaling for all price levels. Controls whether strategy uses tight or wide stops/targets relative to ATR.
Stop Multiplier (1.0-2.5): Stop loss tightness. Lower values = aggressive profit protection, higher values = more breathing room.
Target Multiplier (1.5-4.0): Profit target ambition. Lower values = quick scalping exits, higher values = swing trading holds.
Adaptation Gene
Regime Adaptation (0.0-1.0): How much strategy adjusts behavior based on detected market regime (trending/volatile/choppy). Higher values = more reactive to regime changes.
The Magic: AGE doesn't just try random combinations. Through tournament selection and fitness-weighted crossover, successful gene combinations spread through the population while unsuccessful ones fade away. Over 50-100 bars, you'll see the population converge toward genes that work for YOUR instrument and timeframe.
📊 THE SIGNAL ENGINE: THREE-LAYER SYNTHESIS
Before any strategy generates a signal, AGE calculates probability through multi-indicator confluence:
Layer 1 - Market Entropy (Information Theory)
Measures whether price movements exhibit directional order or random walk characteristics:
The Math:
Shannon Entropy = -Σ(p × log(p))
Market Order = 1 - (Entropy / 0.693)
What It Means:
High entropy = choppy, random market → low confidence signals
Low entropy = directional market → high confidence signals
Direction determined by up-move vs down-move dominance over lookback period (default: 20 bars)
Signal Output: -1.0 to +1.0 (bearish order to bullish order)
Layer 2 - Momentum Synthesis
Combines three momentum indicators into single composite score:
Components:
RSI (40% weight): Normalized to -1/+1 scale using (RSI-50)/50
Rate of Change (30% weight): Percentage change over lookback (default: 14 bars), clamped to ±1
MACD Histogram (30% weight): Fast(12) - Slow(26), normalized by ATR
Why This Matters: RSI catches mean-reversion opportunities, ROC catches raw momentum, MACD catches momentum divergence. Weighting favors RSI for reliability while keeping other perspectives.
Signal Output: -1.0 to +1.0 (strong bearish to strong bullish)
Layer 3 - Structure Analysis
Evaluates price position within swing range (default: 50-bar lookback):
Position Classification:
Bottom 20% of range = Support Zone → bullish bounce potential
Top 20% of range = Resistance Zone → bearish rejection potential
Middle 60% = Neutral Zone → breakout/breakdown monitoring
Signal Logic:
At support + bullish candle = +0.7 (strong buy setup)
At resistance + bearish candle = -0.7 (strong sell setup)
Breaking above range highs = +0.5 (breakout confirmation)
Breaking below range lows = -0.5 (breakdown confirmation)
Consolidation within range = ±0.3 (weak directional bias)
Signal Output: -1.0 to +1.0 (bearish structure to bullish structure)
Confluence Voting System
Each layer casts a vote (Long/Short/Neutral). The system requires minimum 2-of-3 agreement (configurable 1-3) before generating a signal:
Examples:
Entropy: Bullish, Momentum: Bullish, Structure: Neutral → Signal generated (2 long votes)
Entropy: Bearish, Momentum: Neutral, Structure: Neutral → No signal (only 1 short vote)
All three bullish → Signal generated with +5% probability bonus
This is the key to quality. Single indicators give too many false signals. Triple confirmation dramatically improves accuracy.
📈 PROBABILITY CALCULATION: HOW CONFIDENCE IS MEASURED
Base Probability:
Raw_Prob = 50% + (Average_Signal_Strength × 25%)
Then AGE applies strategic adjustments:
Trend Alignment:
Signal with trend: +4%
Signal against strong trend: -8%
Weak/no trend: no adjustment
Regime Adaptation:
Trending market (efficiency >50%, moderate vol): +3%
Volatile market (vol ratio >1.5x): -5%
Choppy market (low efficiency): -2%
Volume Confirmation:
Volume > 70% of 20-bar SMA: no change
Volume below threshold: -3%
Volatility State (DVS Ratio):
High vol (>1.8x baseline): -4% (reduce confidence in chaos)
Low vol (<0.7x baseline): -2% (markets can whipsaw in compression)
Moderate elevated vol (1.0-1.3x): +2% (trending conditions emerging)
Confluence Bonus:
All 3 indicators agree: +5%
2 of 3 agree: +2%
Strategy Gene Adjustment:
Probability Boost gene: -10% to +10%
Regime Adaptation gene: scales regime adjustments by 0-100%
Final Probability: Clamped between 35% (minimum) and 88% (maximum)
Why These Ranges?
Below 35% = too uncertain, better not to signal
Above 88% = unrealistic, creates overconfidence
Sweet spot: 65-80% for quality entries
🔄 THE SHADOW PORTFOLIO SYSTEM: HOW STRATEGIES COMPETE
Each active strategy maintains a virtual trading account that executes in parallel with real-time data:
Shadow Trading Mechanics
Entry Logic:
Calculate signal direction, probability, and confluence using strategy's unique DNA
Check if signal meets quality gate:
Probability ≥ configured minimum threshold (default: 65%)
Confluence ≥ configured minimum (default: 2 of 3)
Direction is not zero (must be long or short, not neutral)
Verify signal persistence:
Base requirement: 2 bars (configurable 1-5)
Adapts based on probability: high-prob signals (75%+) enter 1 bar faster, low-prob signals need 1 bar more
Adjusts for regime: trending markets reduce persistence by 1, volatile markets add 1
Apply additional filters:
Trend strength must exceed strategy's requirement gene
Regime filter: if volatile market detected, probability must be 72%+ to override
Volume confirmation required (volume > 70% of average)
If all conditions met for required persistence bars, enter shadow position at current close price
Position Management:
Entry Price: Recorded at close of entry bar
Stop Loss: ATR-based distance = ATR × ATR_Mult (gene) × Stop_Mult (gene) × DVS_Ratio
Take Profit: ATR-based distance = ATR × ATR_Mult (gene) × Target_Mult (gene) × DVS_Ratio
Position: +1 (long) or -1 (short), only one at a time per strategy
Exit Logic:
Check if price hit stop (on low) or target (on high) on current bar
Record trade outcome in R-multiples (profit/loss normalized by ATR)
Update performance metrics:
Total trades counter incremented
Wins counter (if profit > 0)
Cumulative P&L updated
Peak equity tracked (for drawdown calculation)
Maximum drawdown from peak recorded
Enter cooldown period (default: 8 bars, configurable 3-20) before next entry allowed
Reset signal age counter to zero
Walk-Forward Tracking:
During position lifecycle, trades are categorized:
Training Phase (first 250 bars): Trade counted toward training metrics
Testing Phase (next 75 bars): Trade counted toward testing metrics (out-of-sample)
Live Phase (after WFO period): Trade counted toward overall metrics
Why Shadow Portfolios?
No lookahead bias (uses only data available at the bar)
Realistic execution simulation (entry on close, stop/target checks on high/low)
Independent performance tracking for true fitness comparison
Allows safe experimentation without risking capital
Each strategy learns from its own experience
🏆 FITNESS SCORING: HOW STRATEGIES ARE RANKED
Fitness is not just win rate. AGE uses a comprehensive multi-factor scoring system:
Core Metrics (Minimum 3 trades required)
Win Rate (30% of fitness):
WinRate = Wins / TotalTrades
Normalized directly (0.0-1.0 scale)
Total P&L (30% of fitness):
Normalized_PnL = (PnL + 300) / 600
Clamped 0.0-1.0. Assumes P&L range of -300R to +300R for normalization scale.
Expectancy (25% of fitness):
Expectancy = Total_PnL / Total_Trades
Normalized_Expectancy = (Expectancy + 30) / 60
Clamped 0.0-1.0. Rewards consistency of profit per trade.
Drawdown Control (15% of fitness):
Normalized_DD = 1 - (Max_Drawdown / 15)
Clamped 0.0-1.0. Penalizes strategies that suffer large equity retracements from peak.
Sample Size Adjustment
Quality Factor:
<50 trades: 1.0 (full weight, small sample)
50-100 trades: 0.95 (slight penalty for medium sample)
100 trades: 0.85 (larger penalty for large sample)
Why penalize more trades? Prevents strategies from gaming the system by taking hundreds of tiny trades to inflate statistics. Favors quality over quantity.
Bonus Adjustments
Walk-Forward Validation Bonus:
if (WFO_Validated):
Fitness += (WFO_Efficiency - 0.5) × 0.1
Strategies proven on out-of-sample data receive up to +10% fitness boost based on test/train efficiency ratio.
Signal Efficiency Bonus (if diagnostics enabled):
if (Signals_Evaluated > 10):
Pass_Rate = Signals_Passed / Signals_Evaluated
Fitness += (Pass_Rate - 0.1) × 0.05
Rewards strategies that generate high-quality signals passing the quality gate, not just profitable trades.
Final Fitness: Clamped at 0.0 minimum (prevents negative fitness values)
Result: Elite strategies typically achieve 0.50-0.75 fitness. Anything above 0.60 is excellent. Below 0.30 is prime candidate for culling.
🔬 WALK-FORWARD OPTIMIZATION: ANTI-OVERFITTING PROTECTION
This is what separates AGE from curve-fitted garbage indicators.
The Three-Phase Process
Every new strategy undergoes a rigorous validation lifecycle:
Phase 1 - Training Window (First 250 bars, configurable 100-500):
Strategy trades normally via shadow portfolio
All trades count toward training performance metrics
System learns which gene combinations produce profitable patterns
Tracks independently: Training_Trades, Training_Wins, Training_PnL
Phase 2 - Testing Window (Next 75 bars, configurable 30-200):
Strategy continues trading without any parameter changes
Trades now count toward testing performance metrics (separate tracking)
This is out-of-sample data - strategy has never seen these bars during "optimization"
Tracks independently: Testing_Trades, Testing_Wins, Testing_PnL
Phase 3 - Validation Check:
Minimum_Trades = 5 (configurable 3-15)
IF (Train_Trades >= Minimum AND Test_Trades >= Minimum):
WR_Efficiency = Test_WinRate / Train_WinRate
Expectancy_Efficiency = Test_Expectancy / Train_Expectancy
WFO_Efficiency = (WR_Efficiency + Expectancy_Efficiency) / 2
IF (WFO_Efficiency >= 0.55): // configurable 0.3-0.9
Strategy.Validated = TRUE
Strategy receives fitness bonus
ELSE:
Strategy receives 30% fitness penalty
ELSE:
Validation deferred (insufficient trades in one or both periods)
What Validation Means
Validated Strategy (Green "✓ VAL" in dashboard):
Performed at least 55% as well on unseen data compared to training data
Gets fitness bonus: +(efficiency - 0.5) × 0.1
Receives priority during tournament selection for breeding
More likely to be chosen as active trading strategy
Unvalidated Strategy (Orange "○ TRAIN" in dashboard):
Failed to maintain performance on test data (likely curve-fitted to training period)
Receives 30% fitness penalty (0.7x multiplier)
Makes strategy prime candidate for culling
Can still trade but with lower selection probability
Insufficient Data (continues collecting):
Hasn't completed both training and testing periods yet
OR hasn't achieved minimum trade count in both periods
Validation check deferred until requirements met
Why 55% Efficiency Threshold?
If a strategy earned 10R during training but only 5.5R during testing, it still proved an edge exists beyond random luck. Requiring 100% efficiency would be unrealistic - market conditions change between periods. But requiring >50% ensures the strategy didn't completely degrade on fresh data.
The Protection: Strategies that work great on historical data but fail on new data are automatically identified and penalized. This prevents the population from being polluted by overfitted strategies that would fail in live trading.
🌊 DYNAMIC VOLATILITY SCALING (DVS): ADAPTIVE STOP/TARGET PLACEMENT
AGE doesn't use fixed stop distances. It adapts to current volatility conditions in real-time.
Four Volatility Measurement Methods
1. ATR Ratio (Simple Method):
Current_Vol = ATR(14) / Close
Baseline_Vol = SMA(Current_Vol, 100)
Ratio = Current_Vol / Baseline_Vol
Basic comparison of current ATR to 100-bar moving average baseline.
2. Parkinson (High-Low Range Based):
For each bar: HL = log(High / Low)
Parkinson_Vol = sqrt(Σ(HL²) / (4 × Period × log(2)))
More stable than close-to-close volatility. Captures intraday range expansion without overnight gap noise.
3. Garman-Klass (OHLC Based):
HL_Term = 0.5 × ²
CO_Term = (2×log(2) - 1) × ²
GK_Vol = sqrt(Σ(HL_Term - CO_Term) / Period)
Most sophisticated estimator. Incorporates all four price points (open, high, low, close) plus gap information.
4. Ensemble Method (Default - Median of All Three):
Ratio_1 = ATR_Current / ATR_Baseline
Ratio_2 = Parkinson_Current / Parkinson_Baseline
Ratio_3 = GK_Current / GK_Baseline
DVS_Ratio = Median(Ratio_1, Ratio_2, Ratio_3)
Why Ensemble?
Takes median to avoid outliers and false spikes
If ATR jumps but range-based methods stay calm, median prevents overreaction
If one method fails, other two compensate
Most robust approach across different market conditions
Sensitivity Scaling
Scaled_Ratio = (Raw_Ratio) ^ Sensitivity
Sensitivity 0.3: Cube root - heavily dampens volatility impact
Sensitivity 0.5: Square root - moderate dampening
Sensitivity 0.7 (Default): Balanced response to volatility changes
Sensitivity 1.0: Linear - full 1:1 volatility impact
Sensitivity 1.5: Exponential - amplified response to volatility spikes
Safety Clamps: Final DVS Ratio always clamped between 0.5x and 2.5x baseline to prevent extreme position sizing or stop placement errors.
How DVS Affects Shadow Trading
Every strategy's stop and target distances are multiplied by the current DVS ratio:
Stop Loss Distance:
Stop_Distance = ATR × ATR_Mult (gene) × Stop_Mult (gene) × DVS_Ratio
Take Profit Distance:
Target_Distance = ATR × ATR_Mult (gene) × Target_Mult (gene) × DVS_Ratio
Example Scenario:
ATR = 10 points
Strategy's ATR_Mult gene = 2.5
Strategy's Stop_Mult gene = 1.5
Strategy's Target_Mult gene = 2.5
DVS_Ratio = 1.4 (40% above baseline volatility - market heating up)
Stop = 10 × 2.5 × 1.5 × 1.4 = 52.5 points (vs. 37.5 in normal vol)
Target = 10 × 2.5 × 2.5 × 1.4 = 87.5 points (vs. 62.5 in normal vol)
Result:
During volatility spikes: Stops automatically widen to avoid noise-based exits, targets extend for bigger moves
During calm periods: Stops tighten for better risk/reward, targets compress for realistic profit-taking
Strategies adapt risk management to match current market behavior
🧬 THE EVOLUTIONARY CYCLE: SPAWN, COMPETE, CULL
Initialization (Bar 1)
AGE begins with 4 seed strategies (if evolution enabled):
Seed Strategy #0 (Balanced):
All sensitivities at 1.0 (neutral)
Zero probability boost
Moderate trend requirement (0.4)
Standard ATR/stop/target multiples (2.5/1.5/2.5)
Mid-level regime adaptation (0.5)
Seed Strategy #1 (Momentum-Focused):
Lower entropy sensitivity (0.7), higher momentum (1.5)
Slight probability boost (+0.03)
Higher trend requirement (0.5)
Tighter stops (1.3), wider targets (3.0)
Seed Strategy #2 (Entropy-Driven):
Higher entropy sensitivity (1.5), lower momentum (0.8)
Slight probability penalty (-0.02)
More trend tolerant (0.6)
Wider stops (1.8), standard targets (2.5)
Seed Strategy #3 (Structure-Based):
Balanced entropy/momentum (0.8/0.9), high structure (1.4)
Slight probability boost (+0.02)
Lower trend requirement (0.35)
Moderate risk parameters (1.6/2.8)
All seeds start with WFO validation bypassed if WFO is disabled, or must validate if enabled.
Spawning New Strategies
Timing (Adaptive):
Historical phase: Every 30 bars (configurable 10-100)
Live phase: Every 200 bars (configurable 100-500)
Automatically switches to live timing when barstate.isrealtime triggers
Conditions:
Current population < max population limit (default: 8, configurable 4-12)
At least 2 active strategies exist (need parents)
Available slot in population array
Selection Process:
Run tournament selection 3 times with different seeds
Each tournament: randomly sample active strategies, pick highest fitness
Best from 3 tournaments becomes Parent 1
Repeat independently for Parent 2
Ensures fit parents but maintains diversity
Crossover Breeding:
For each of 10 genes:
Parent1_Fitness = fitness
Parent2_Fitness = fitness
Weight1 = Parent1_Fitness / (Parent1_Fitness + Parent2_Fitness)
Gene1 = parent1's value
Gene2 = parent2's value
Child_Gene = Weight1 × Gene1 + (1 - Weight1) × Gene2
Fitness-weighted crossover ensures fitter parent contributes more genetic material.
Mutation:
For each gene in child:
IF (random < mutation_rate):
Gene_Range = GENE_MAX - GENE_MIN
Noise = (random - 0.5) × 2 × mutation_strength × Gene_Range
Mutated_Gene = Clamp(Child_Gene + Noise, GENE_MIN, GENE_MAX)
Historical mutation rate: 20% (aggressive exploration)
Live mutation rate: 8% (conservative stability)
Mutation strength: 12% of gene range (configurable 5-25%)
Initialization of New Strategy:
Unique ID assigned (total_spawned counter)
Parent ID recorded
Generation = max(parent generations) + 1
Birth bar recorded (for age tracking)
All performance metrics zeroed
Shadow portfolio reset
WFO validation flag set to false (must prove itself)
Result: New strategy with hybrid DNA enters population, begins trading in next bar.
Competition (Every Bar)
All active strategies:
Calculate their signal based on unique DNA
Check quality gate with their thresholds
Manage shadow positions (entries/exits)
Update performance metrics
Recalculate fitness score
Track WFO validation progress
Strategies compete indirectly through fitness ranking - no direct interaction.
Culling Weak Strategies
Timing (Adaptive):
Historical phase: Every 60 bars (configurable 20-200, should be 2x spawn interval)
Live phase: Every 400 bars (configurable 200-1000, should be 2x spawn interval)
Minimum Adaptation Score (MAS):
Initial MAS = 0.10
MAS decays: MAS × 0.995 every cull cycle
Minimum MAS = 0.03 (floor)
MAS represents the "survival threshold" - strategies below this fitness level are vulnerable.
Culling Conditions (ALL must be true):
Population > minimum population (default: 3, configurable 2-4)
At least one strategy has fitness < MAS
Strategy's age > culling interval (prevents premature culling of new strategies)
Strategy is not in top N elite (default: 2, configurable 1-3)
Culling Process:
Find worst strategy:
For each active strategy:
IF (age > cull_interval):
Fitness = base_fitness
IF (not WFO_validated AND WFO_enabled):
Fitness × 0.7 // 30% penalty for unvalidated
IF (Fitness < MAS AND Fitness < worst_fitness_found):
worst_strategy = this_strategy
worst_fitness = Fitness
IF (worst_strategy found):
Count elite strategies with fitness > worst_fitness
IF (elite_count >= elite_preservation_count):
Deactivate worst_strategy (set active flag = false)
Increment total_culled counter
Elite Protection:
Even if a strategy's fitness falls below MAS, it survives if fewer than N strategies are better. This prevents culling when population is generally weak.
Result: Weak strategies removed from population, freeing slots for new spawns. Gene pool improves over time.
Selection for Display (Every Bar)
AGE chooses one strategy to display signals:
Best fitness = -1
Selected = none
For each active strategy:
Fitness = base_fitness
IF (WFO_validated):
Fitness × 1.3 // 30% bonus for validated strategies
IF (Fitness > best_fitness):
best_fitness = Fitness
selected_strategy = this_strategy
Display selected strategy's signals on chart
Result: Only the highest-fitness (optionally validated-boosted) strategy's signals appear as chart markers. Other strategies trade invisibly in shadow portfolios.
🎨 PREMIUM VISUALIZATION SYSTEM
AGE includes sophisticated visual feedback that standard indicators lack:
1. Gradient Probability Cloud (Optional, Default: ON)
Multi-layer gradient showing signal buildup 2-3 bars before entry:
Activation Conditions:
Signal persistence > 0 (same directional signal held for multiple bars)
Signal probability ≥ minimum threshold (65% by default)
Signal hasn't yet executed (still in "forming" state)
Visual Construction:
7 gradient layers by default (configurable 3-15)
Each layer is a line-fill pair (top line, bottom line, filled between)
Layer spacing: 0.3 to 1.0 × ATR above/below price
Outer layers = faint, inner layers = bright
Color transitions from base to intense based on layer position
Transparency scales with probability (high prob = more opaque)
Color Selection:
Long signals: Gradient from theme.gradient_bull_mid to theme.gradient_bull_strong
Short signals: Gradient from theme.gradient_bear_mid to theme.gradient_bear_strong
Base transparency: 92%, reduces by up to 8% for high-probability setups
Dynamic Behavior:
Cloud grows/shrinks as signal persistence increases/decreases
Redraws every bar while signal is forming
Disappears when signal executes or invalidates
Performance Note: Computationally expensive due to linefill objects. Disable or reduce layers if chart performance degrades.
2. Population Fitness Ribbon (Optional, Default: ON)
Histogram showing fitness distribution across active strategies:
Activation: Only draws on last bar (barstate.islast) to avoid historical clutter
Visual Construction:
10 histogram layers by default (configurable 5-20)
Plots 50 bars back from current bar
Positioned below price at: lowest_low(100) - 1.5×ATR (doesn't interfere with price action)
Each layer represents a fitness threshold (evenly spaced min to max fitness)
Layer Logic:
For layer_num from 0 to ribbon_layers:
Fitness_threshold = min_fitness + (max_fitness - min_fitness) × (layer / layers)
Count strategies with fitness ≥ threshold
Height = ATR × 0.15 × (count / total_active)
Y_position = base_level + ATR × 0.2 × layer
Color = Gradient from weak to strong based on layer position
Line_width = Scaled by height (taller = thicker)
Visual Feedback:
Tall, bright ribbon = healthy population, many fit strategies at high fitness levels
Short, dim ribbon = weak population, few strategies achieving good fitness
Ribbon compression (layers close together) = population converging to similar fitness
Ribbon spread = diverse fitness range, active selection pressure
Use Case: Quick visual health check without opening dashboard. Ribbon growing upward over time = population improving.
3. Confidence Halo (Optional, Default: ON)
Circular polyline around entry signals showing probability strength:
Activation: Draws when new position opens (shadow_position changes from 0 to ±1)
Visual Construction:
20-segment polyline forming approximate circle
Center: Low - 0.5×ATR (long) or High + 0.5×ATR (short)
Radius: 0.3×ATR (low confidence) to 1.0×ATR (elite confidence)
Scales with: (probability - min_probability) / (1.0 - min_probability)
Color Coding:
Elite (85%+): Cyan (theme.conf_elite), large radius, minimal transparency (40%)
Strong (75-85%): Strong green (theme.conf_strong), medium radius, moderate transparency (50%)
Good (65-75%): Good green (theme.conf_good), smaller radius, more transparent (60%)
Moderate (<65%): Moderate green (theme.conf_moderate), tiny radius, very transparent (70%)
Technical Detail:
Uses chart.point array with index-based positioning
5-bar horizontal spread for circular appearance (±5 bars from entry)
Curved=false (Pine Script polyline limitation)
Fill color matches line color but more transparent (88% vs line's transparency)
Purpose: Instant visual probability assessment. No need to check dashboard - halo size/brightness tells the story.
4. Evolution Event Markers (Optional, Default: ON)
Visual indicators of genetic algorithm activity:
Spawn Markers (Diamond, Cyan):
Plots when total_spawned increases on current bar
Location: bottom of chart (location.bottom)
Color: theme.spawn_marker (cyan/bright blue)
Size: tiny
Indicates new strategy just entered population
Cull Markers (X-Cross, Red):
Plots when total_culled increases on current bar
Location: bottom of chart (location.bottom)
Color: theme.cull_marker (red/pink)
Size: tiny
Indicates weak strategy just removed from population
What It Tells You:
Frequent spawning early = population building, active exploration
Frequent culling early = high selection pressure, weak strategies dying fast
Balanced spawn/cull = healthy evolutionary churn
No markers for long periods = stable population (evolution plateaued or optimal genes found)
5. Entry/Exit Markers
Clear visual signals for selected strategy's trades:
Long Entry (Triangle Up, Green):
Plots when selected strategy opens long position (position changes 0 → +1)
Location: below bar (location.belowbar)
Color: theme.long_primary (green/cyan depending on theme)
Transparency: Scales with probability:
Elite (85%+): 0% (fully opaque)
Strong (75-85%): 10%
Good (65-75%): 20%
Acceptable (55-65%): 35%
Size: small
Short Entry (Triangle Down, Red):
Plots when selected strategy opens short position (position changes 0 → -1)
Location: above bar (location.abovebar)
Color: theme.short_primary (red/pink depending on theme)
Transparency: Same scaling as long entries
Size: small
Exit (X-Cross, Orange):
Plots when selected strategy closes position (position changes ±1 → 0)
Location: absolute (at actual exit price if stop/target lines enabled)
Color: theme.exit_color (orange/yellow depending on theme)
Transparency: 0% (fully opaque)
Size: tiny
Result: Clean, probability-scaled markers that don't clutter chart but convey essential information.
6. Stop Loss & Take Profit Lines (Optional, Default: ON)
Visual representation of shadow portfolio risk levels:
Stop Loss Line:
Plots when selected strategy has active position
Level: shadow_stop value from selected strategy
Color: theme.short_primary with 60% transparency (red/pink, subtle)
Width: 2
Style: plot.style_linebr (breaks when no position)
Take Profit Line:
Plots when selected strategy has active position
Level: shadow_target value from selected strategy
Color: theme.long_primary with 60% transparency (green, subtle)
Width: 2
Style: plot.style_linebr (breaks when no position)
Purpose:
Shows where shadow portfolio would exit for stop/target
Helps visualize strategy's risk/reward ratio
Useful for manual traders to set similar levels
Disable for cleaner chart (recommended for presentations)
7. Dynamic Trend EMA
Gradient-colored trend line that visualizes trend strength:
Calculation:
EMA(close, trend_length) - default 50 period (configurable 20-100)
Slope calculated over 10 bars: (current_ema - ema ) / ema × 100
Color Logic:
Trend_direction:
Slope > 0.1% = Bullish (1)
Slope < -0.1% = Bearish (-1)
Otherwise = Neutral (0)
Trend_strength = abs(slope)
Color = Gradient between:
- Neutral color (gray/purple)
- Strong bullish (bright green) if direction = 1
- Strong bearish (bright red) if direction = -1
Gradient factor = trend_strength (0 to 1+ scale)
Visual Behavior:
Faint gray/purple = weak/no trend (choppy conditions)
Light green/red = emerging trend (low strength)
Bright green/red = strong trend (high conviction)
Color intensity = trend strength magnitude
Transparency: 50% (subtle, doesn't overpower price action)
Purpose: Subconscious awareness of trend state without checking dashboard or indicators.
8. Regime Background Tinting (Subtle)
Ultra-low opacity background color indicating detected market regime:
Regime Detection:
Efficiency = directional_movement / total_range (over trend_length bars)
Vol_ratio = current_volatility / average_volatility
IF (efficiency > 0.5 AND vol_ratio < 1.3):
Regime = Trending (1)
ELSE IF (vol_ratio > 1.5):
Regime = Volatile (2)
ELSE:
Regime = Choppy (0)
Background Colors:
Trending: theme.regime_trending (dark green, 92-93% transparency)
Volatile: theme.regime_volatile (dark red, 93% transparency)
Choppy: No tint (normal background)
Purpose:
Subliminal regime awareness
Helps explain why signals are/aren't generating
Trending = ideal conditions for AGE
Volatile = fewer signals, higher thresholds applied
Choppy = mixed signals, lower confidence
Important: Extremely subtle by design. Not meant to be obvious, just subconscious context.
📊 ENHANCED DASHBOARD
Comprehensive real-time metrics in single organized panel (top-right position):
Dashboard Structure (5 columns × 14 rows)
Header Row:
Column 0: "🧬 AGE PRO" + phase indicator (🔴 LIVE or ⏪ HIST)
Column 1: "POPULATION"
Column 2: "PERFORMANCE"
Column 3: "CURRENT SIGNAL"
Column 4: "ACTIVE STRATEGY"
Column 0: Market State
Regime (📈 TREND / 🌊 CHAOS / ➖ CHOP)
DVS Ratio (current volatility scaling factor, format: #.##)
Trend Direction (▲ BULL / ▼ BEAR / ➖ FLAT with color coding)
Trend Strength (0-100 scale, format: #.##)
Column 1: Population Metrics
Active strategies (count / max_population)
Validated strategies (WFO passed / active total)
Current generation number
Total spawned (all-time strategy births)
Total culled (all-time strategy deaths)
Column 2: Aggregate Performance
Total trades across all active strategies
Aggregate win rate (%) - color-coded:
Green (>55%)
Orange (45-55%)
Red (<45%)
Total P&L in R-multiples - color-coded by positive/negative
Best fitness score in population (format: #.###)
MAS - Minimum Adaptation Score (cull threshold, format: #.###)
Column 3: Current Signal Status
Status indicator:
"▲ LONG" (green) if selected strategy in long position
"▼ SHORT" (red) if selected strategy in short position
"⏳ FORMING" (orange) if signal persisting but not yet executed
"○ WAITING" (gray) if no active signal
Confidence percentage (0-100%, format: #.#%)
Quality assessment:
"🔥 ELITE" (cyan) for 85%+ probability
"✓ STRONG" (bright green) for 75-85%
"○ GOOD" (green) for 65-75%
"- LOW" (dim) for <65%
Confluence score (X/3 format)
Signal age:
"X bars" if signal forming
"IN TRADE" if position active
"---" if no signal
Column 4: Selected Strategy Details
Strategy ID number (#X format)
Validation status:
"✓ VAL" (green) if WFO validated
"○ TRAIN" (orange) if still in training/testing phase
Generation number (GX format)
Personal fitness score (format: #.### with color coding)
Trade count
P&L and win rate (format: #.#R (##%) with color coding)
Color Scheme:
Panel background: theme.panel_bg (dark, low opacity)
Panel headers: theme.panel_header (slightly lighter)
Primary text: theme.text_primary (bright, high contrast)
Secondary text: theme.text_secondary (dim, lower contrast)
Positive metrics: theme.metric_positive (green)
Warning metrics: theme.metric_warning (orange)
Negative metrics: theme.metric_negative (red)
Special markers: theme.validated_marker, theme.spawn_marker
Update Frequency: Only on barstate.islast (current bar) to minimize CPU usage
Purpose:
Quick overview of entire system state
No need to check multiple indicators
Trading decisions informed by population health, regime state, and signal quality
Transparency into what AGE is thinking
🔍 DIAGNOSTICS PANEL (Optional, Default: OFF)
Detailed signal quality tracking for optimization and debugging:
Panel Structure (3 columns × 8 rows)
Position: Bottom-right corner (doesn't interfere with main dashboard)
Header Row:
Column 0: "🔍 DIAGNOSTICS"
Column 1: "COUNT"
Column 2: "%"
Metrics Tracked (for selected strategy only):
Total Evaluated:
Every signal that passed initial calculation (direction ≠ 0)
Represents total opportunities considered
✓ Passed:
Signals that passed quality gate and executed
Green color coding
Percentage of evaluated signals
Rejection Breakdown:
⨯ Probability:
Rejected because probability < minimum threshold
Most common rejection reason typically
⨯ Confluence:
Rejected because confluence < minimum required (e.g., only 1 of 3 indicators agreed)
⨯ Trend:
Rejected because signal opposed strong trend
Indicates counter-trend protection working
⨯ Regime:
Rejected because volatile regime detected and probability wasn't high enough to override
Shows regime filter in action
⨯ Volume:
Rejected because volume < 70% of 20-bar average
Indicates volume confirmation requirement
Color Coding:
Passed count: Green (success metric)
Rejection counts: Red (failure metrics)
Percentages: Gray (neutral, informational)
Performance Cost: Slight CPU overhead for tracking counters. Disable when not actively optimizing settings.
How to Use Diagnostics
Scenario 1: Too Few Signals
Evaluated: 200
Passed: 10 (5%)
⨯ Probability: 120 (60%)
⨯ Confluence: 40 (20%)
⨯ Others: 30 (15%)
Diagnosis: Probability threshold too high for this strategy's DNA.
Solution: Lower min probability from 65% to 60%, or allow strategy more time to evolve better DNA.
Scenario 2: Too Many False Signals
Evaluated: 200
Passed: 80 (40%)
Strategy win rate: 45%
Diagnosis: Quality gate too loose, letting low-quality signals through.
Solution: Raise min probability to 70%, or increase min confluence to 3 (all indicators must agree).
Scenario 3: Regime-Specific Issues
⨯ Regime: 90 (45% of rejections)
Diagnosis: Frequent volatile regime detection blocking otherwise good signals.
Solution: Either accept fewer trades during chaos (recommended), or disable regime filter if you want signals regardless of market state.
Optimization Workflow:
Enable diagnostics
Run 200+ bars
Analyze rejection patterns
Adjust settings based on data
Re-run and compare pass rate
Disable diagnostics when satisfied
⚙️ CONFIGURATION GUIDE
🧬 Evolution Engine Settings
Enable AGE Evolution (Default: ON):
ON: Full genetic algorithm (recommended for best results)
OFF: Uses only 4 seed strategies, no spawning/culling (static population for comparison testing)
Max Population (4-12, Default: 8):
Higher = more diversity, more exploration, slower performance
Lower = faster computation, less exploration, risk of premature convergence
Sweet spot: 6-8 for most use cases
4 = minimum for meaningful evolution
12 = maximum before diminishing returns
Min Population (2-4, Default: 3):
Safety floor - system never culls below this count
Prevents population extinction during harsh selection
Should be at least half of max population
Elite Preservation (1-3, Default: 2):
Top N performers completely immune to culling
Ensures best genes always survive
1 = minimal protection, aggressive selection
2 = balanced (recommended)
3 = conservative, slower gene pool turnover
Historical: Spawn Interval (10-100, Default: 30):
Bars between spawning new strategies during historical data
Lower = faster evolution, more exploration
Higher = slower evolution, more evaluation time per strategy
30 bars = ~1-2 hours on 15min chart
Historical: Cull Interval (20-200, Default: 60):
Bars between culling weak strategies during historical data
Should be 2x spawn interval for balanced churn
Lower = aggressive selection pressure
Higher = patient evaluation
Live: Spawn Interval (100-500, Default: 200):
Bars between spawning during live trading
Much slower than historical for stability
Prevents population chaos during live trading
200 bars = ~1.5 trading days on 15min chart
Live: Cull Interval (200-1000, Default: 400):
Bars between culling during live trading
Should be 2x live spawn interval
Conservative removal during live trading
Historical: Mutation Rate (0.05-0.40, Default: 0.20):
Probability each gene mutates during breeding (20% = 2 out of 10 genes on average)
Higher = more exploration, slower convergence
Lower = more exploitation, faster convergence but risk of local optima
20% balances exploration vs exploitation
Live: Mutation Rate (0.02-0.20, Default: 0.08):
Mutation rate during live trading
Much lower for stability (don't want population to suddenly degrade)
8% = mostly inherits parent genes with small tweaks
Mutation Strength (0.05-0.25, Default: 0.12):
How much genes change when mutated (% of gene's total range)
0.05 = tiny nudges (fine-tuning)
0.12 = moderate jumps (recommended)
0.25 = large leaps (aggressive exploration)
Example: If gene range is 0.5-2.0, 12% strength = ±0.18 possible change
📈 Signal Quality Settings
Min Signal Probability (0.55-0.80, Default: 0.65):
Quality gate threshold - signals below this never generate
0.55-0.60 = More signals, accept lower confidence (higher risk)
0.65 = Institutional-grade balance (recommended)
0.70-0.75 = Fewer but higher-quality signals (conservative)
0.80+ = Very selective, very few signals (ultra-conservative)
Min Confluence Score (1-3, Default: 2):
Required indicator agreement before signal generates
1 = Any single indicator can trigger (not recommended - too many false signals)
2 = Requires 2 of 3 indicators agree (RECOMMENDED for balance)
3 = All 3 must agree (very selective, few signals, high quality)
Base Persistence Bars (1-5, Default: 2):
Base bars signal must persist before entry
System adapts automatically:
High probability signals (75%+) enter 1 bar faster
Low probability signals (<68%) need 1 bar more
Trending regime: -1 bar (faster entries)
Volatile regime: +1 bar (more confirmation)
1 = Immediate entry after quality gate (responsive but prone to whipsaw)
2 = Balanced confirmation (recommended)
3-5 = Patient confirmation (slower but more reliable)
Cooldown After Trade (3-20, Default: 8):
Bars to wait after exit before next entry allowed
Prevents overtrading and revenge trading
3 = Minimal cooldown (active trading)
8 = Balanced (recommended)
15-20 = Conservative (position trading)
Entropy Length (10-50, Default: 20):
Lookback period for market order/disorder calculation
Lower = more responsive to regime changes (noisy)
Higher = more stable regime detection (laggy)
20 = works across most timeframes
Momentum Length (5-30, Default: 14):
Period for RSI/ROC calculations
14 = standard (RSI default)
Lower = more signals, less reliable
Higher = fewer signals, more reliable
Structure Length (20-100, Default: 50):
Lookback for support/resistance swing range
20 = short-term swings (day trading)
50 = medium-term structure (recommended)
100 = major structure (position trading)
Trend EMA Length (20-100, Default: 50):
EMA period for trend detection and direction bias
20 = short-term trend (responsive)
50 = medium-term trend (recommended)
100 = long-term trend (position trading)
ATR Period (5-30, Default: 14):
Period for volatility measurement
14 = standard ATR
Lower = more responsive to vol changes
Higher = smoother vol calculation
📊 Volatility Scaling (DVS) Settings
Enable DVS (Default: ON):
Dynamic volatility scaling for adaptive stop/target placement
Highly recommended to leave ON
OFF only for testing fixed-distance stops
DVS Method (Default: Ensemble):
ATR Ratio: Simple, fast, single-method (good for beginners)
Parkinson: High-low range based (good for intraday)
Garman-Klass: OHLC based (sophisticated, considers gaps)
Ensemble: Median of all three (RECOMMENDED - most robust)
DVS Memory (20-200, Default: 100):
Lookback for baseline volatility comparison
20 = very responsive to vol changes (can overreact)
100 = balanced adaptation (recommended)
200 = slow, stable baseline (minimizes false vol signals)
DVS Sensitivity (0.3-1.5, Default: 0.7):
How much volatility affects scaling (power-law exponent)
0.3 = Conservative, heavily dampens vol impact (cube root)
0.5 = Moderate dampening (square root)
0.7 = Balanced response (recommended)
1.0 = Linear, full 1:1 vol response
1.5 = Aggressive, amplified response (exponential)
🔬 Walk-Forward Optimization Settings
Enable WFO (Default: ON):
Out-of-sample validation to prevent overfitting
Highly recommended to leave ON
OFF only for testing or if you want unvalidated strategies
Training Window (100-500, Default: 250):
Bars for in-sample optimization
100 = fast validation, less data (risky)
250 = balanced (recommended) - about 1-2 months on daily, 1-2 weeks on 15min
500 = patient validation, more data (conservative)
Testing Window (30-200, Default: 75):
Bars for out-of-sample validation
Should be ~30% of training window
30 = minimal test (fast validation)
75 = balanced (recommended)
200 = extensive test (very conservative)
Min Trades for Validation (3-15, Default: 5):
Required trades in BOTH training AND testing periods
3 = minimal sample (risky, fast validation)
5 = balanced (recommended)
10+ = conservative (slow validation, high confidence)
WFO Efficiency Threshold (0.3-0.9, Default: 0.55):
Minimum test/train performance ratio required
0.30 = Very loose (test must be 30% as good as training)
0.55 = Balanced (recommended) - test must be 55% as good
0.70+ = Strict (test must closely match training)
Higher = fewer validated strategies, lower risk of overfitting
🎨 Premium Visuals Settings
Visual Theme:
Neon Genesis: Cyberpunk aesthetic (cyan/magenta/purple)
Carbon Fiber: Industrial look (blue/red/gray)
Quantum Blue: Quantum computing (blue/purple/pink)
Aurora: Northern lights (teal/orange/purple)
⚡ Gradient Probability Cloud (Default: ON):
Multi-layer gradient showing signal buildup
Turn OFF if chart lags or for cleaner look
Cloud Gradient Layers (3-15, Default: 7):
More layers = smoother gradient, more CPU intensive
Fewer layers = faster, blockier appearance
🎗️ Population Fitness Ribbon (Default: ON):
Histogram showing fitness distribution
Turn OFF for cleaner chart
Ribbon Layers (5-20, Default: 10):
More layers = finer fitness detail
Fewer layers = simpler histogram
⭕ Signal Confidence Halo (Default: ON):
Circular indicator around entry signals
Size/brightness scales with probability
Minimal performance cost
🔬 Evolution Event Markers (Default: ON):
Diamond (spawn) and X (cull) markers
Shows genetic algorithm activity
Minimal performance cost
🎯 Stop/Target Lines (Default: ON):
Shows shadow portfolio stop/target levels
Turn OFF for cleaner chart (recommended for screenshots/presentations)
📊 Enhanced Dashboard (Default: ON):
Comprehensive metrics panel
Should stay ON unless you want zero overlays
🔍 Diagnostics Panel (Default: OFF):
Detailed signal rejection tracking
Turn ON when optimizing settings
Turn OFF during normal use (slight performance cost)
📈 USAGE WORKFLOW - HOW TO USE THIS INDICATOR
Phase 1: Initial Setup & Learning
Add AGE to your chart
Recommended timeframes: 15min, 30min, 1H (best signal-to-noise ratio)
Works on: 5min (day trading), 4H (swing trading), Daily (position trading)
Load 1000+ bars for sufficient evolution history
Let the population evolve (100+ bars minimum)
First 50 bars: Random exploration, poor results expected
Bars 50-150: Population converging, fitness improving
Bars 150+: Stable performance, validated strategies emerging
Watch the dashboard metrics
Population should grow toward max capacity
Generation number should advance regularly
Validated strategies counter should increase
Best fitness should trend upward toward 0.50-0.70 range
Observe evolution markers
Diamond markers (cyan) = new strategies spawning
X markers (red) = weak strategies being culled
Frequent early activity = healthy evolution
Activity slowing = population stabilizing
Be patient. Evolution takes time. Don't judge performance before 150+ bars.
Phase 2: Signal Observation
Watch signals form
Gradient cloud builds up 2-3 bars before entry
Cloud brightness = probability strength
Cloud thickness = signal persistence
Check signal quality
Look at confidence halo size when entry marker appears
Large bright halo = elite setup (85%+)
Medium halo = strong setup (75-85%)
Small halo = good setup (65-75%)
Verify market conditions
Check trend EMA color (green = uptrend, red = downtrend, gray = choppy)
Check background tint (green = trending, red = volatile, clear = choppy)
Trending background + aligned signal = ideal conditions
Review dashboard signal status
Current Signal column shows:
Status (Long/Short/Forming/Waiting)
Confidence % (actual probability value)
Quality assessment (Elite/Strong/Good)
Confluence score (2/3 or 3/3 preferred)
Only signals meeting ALL quality gates appear on chart. If you're not seeing signals, population is either still learning or market conditions aren't suitable.
Phase 3: Manual Trading Execution
When Long Signal Fires:
Verify confidence level (dashboard or halo size)
Confirm trend alignment (EMA sloping up, green color)
Check regime (preferably trending or choppy, avoid volatile)
Enter long manually on your broker platform
Set stop loss at displayed stop line level (if lines enabled), or use your own risk management
Set take profit at displayed target line level, or trail manually
Monitor position - exit if X marker appears (signal reversal)
When Short Signal Fires:
Same verification process
Confirm downtrend (EMA sloping down, red color)
Enter short manually
Use displayed stop/target levels or your own
AGE tells you WHEN and HOW CONFIDENT. You decide WHETHER and HOW MUCH.
Phase 4: Set Up Alerts (Never Miss a Signal)
Right-click on indicator name in legend
Select "Add Alert"
Choose condition:
"AGE Long" = Long entry signal fired
"AGE Short" = Short entry signal fired
"AGE Exit" = Position reversal/exit signal
Set notification method:
Sound alert (popup on chart)
Email notification
Webhook to phone/trading platform
Mobile app push notification
Name the alert (e.g., "AGE BTCUSD 15min Long")
Save alert
Recommended: Set alerts for both long and short, enable mobile push notifications. You'll get alerted in real-time even if not watching charts.
Phase 5: Monitor Population Health
Weekly Review:
Check dashboard Population column:
Active count should be near max (6-8 of 8)
Validated count should be >50% of active
Generation should be advancing (1-2 per week typical)
Check dashboard Performance column:
Aggregate win rate should be >50% (target: 55-65%)
Total P&L should be positive (may fluctuate)
Best fitness should be >0.50 (target: 0.55-0.70)
MAS should be declining slowly (normal adaptation)
Check Active Strategy column:
Selected strategy should be validated (✓ VAL)
Personal fitness should match best fitness
Trade count should be accumulating
Win rate should be >50%
Warning Signs:
Zero validated strategies after 300+ bars = settings too strict or market unsuitable
Best fitness stuck <0.30 = population struggling, consider parameter adjustment
No spawning/culling for 200+ bars = evolution stalled (may be optimal or need reset)
Aggregate win rate <45% sustained = system not working on this instrument/timeframe
Health Check Pass:
50%+ strategies validated
Best fitness >0.50
Aggregate win rate >52%
Regular spawn/cull activity
Selected strategy validated
Phase 6: Optimization (If Needed)
Enable Diagnostics Panel (bottom-right) for data-driven tuning:
Problem: Too Few Signals
Evaluated: 200
Passed: 8 (4%)
⨯ Probability: 140 (70%)
Solutions:
Lower min probability: 65% → 60% or 55%
Reduce min confluence: 2 → 1
Lower base persistence: 2 → 1
Increase mutation rate temporarily to explore new genes
Check if regime filter is blocking signals (⨯ Regime high?)
Problem: Too Many False Signals
Evaluated: 200
Passed: 90 (45%)
Win rate: 42%
Solutions:
Raise min probability: 65% → 70% or 75%
Increase min confluence: 2 → 3
Raise base persistence: 2 → 3
Enable WFO if disabled (validates strategies before use)
Check if volume filter is being ignored (⨯ Volume low?)
Problem: Counter-Trend Losses
⨯ Trend: 5 (only 5% rejected)
Losses often occur against trend
Solutions:
System should already filter trend opposition
May need stronger trend requirement
Consider only taking signals aligned with higher timeframe trend
Use longer trend EMA (50 → 100)
Problem: Volatile Market Whipsaws
⨯ Regime: 100 (50% rejected by volatile regime)
Still getting stopped out frequently
Solutions:
System is correctly blocking volatile signals
Losses happening because vol filter isn't strict enough
Consider not trading during volatile periods (respect the regime)
Or disable regime filter and accept higher risk
Optimization Workflow:
Enable diagnostics
Run 200+ bars with current settings
Analyze rejection patterns and win rate
Make ONE change at a time (scientific method)
Re-run 200+ bars and compare results
Keep change if improvement, revert if worse
Disable diagnostics when satisfied
Never change multiple parameters at once - you won't know what worked.
Phase 7: Multi-Instrument Deployment
AGE learns independently on each chart:
Recommended Strategy:
Deploy AGE on 3-5 different instruments
Different asset classes ideal (e.g., ES futures, EURUSD, BTCUSD, SPY, Gold)
Each learns optimal strategies for that instrument's personality
Take signals from all 5 charts
Natural diversification reduces overall risk
Why This Works:
When one market is choppy, others may be trending
Different instruments respond to different news/catalysts
Portfolio-level win rate more stable than single-instrument
Evolution explores different parameter spaces on each chart
Setup:
Same settings across all charts (or customize if preferred)
Set alerts for all
Take every validated signal across all instruments
Position size based on total account (don't overleverage any single signal)
⚠️ REALISTIC EXPECTATIONS - CRITICAL READING
What AGE Can Do
✅ Generate probability-weighted signals using genetic algorithms
✅ Evolve strategies in real-time through natural selection
✅ Validate strategies on out-of-sample data (walk-forward optimization)
✅ Adapt to changing market conditions automatically over time
✅ Provide comprehensive metrics on population health and signal quality
✅ Work on any instrument, any timeframe, any broker
✅ Improve over time as weak strategies are culled and fit strategies breed
What AGE Cannot Do
❌ Win every trade (typical win rate: 55-65% at best)
❌ Predict the future with certainty (markets are probabilistic, not deterministic)
❌ Work perfectly from bar 1 (needs 100-150 bars to learn and stabilize)
❌ Guarantee profits under all market conditions
❌ Replace your trading discipline and risk management
❌ Execute trades automatically (this is an indicator, not a strategy)
❌ Prevent all losses (drawdowns are normal and expected)
❌ Adapt instantly to regime changes (re-learning takes 50-100 bars)
Performance Realities
Typical Performance After Evolution Stabilizes (150+ bars):
Win Rate: 55-65% (excellent for trend-following systems)
Profit Factor: 1.5-2.5 (realistic for validated strategies)
Signal Frequency: 5-15 signals per 100 bars (quality over quantity)
Drawdown Periods: 20-40% of time in equity retracement (normal trading reality)
Max Consecutive Losses: 5-8 losses possible even with 60% win rate (probability says this is normal)
Evolution Timeline:
Bars 0-50: Random exploration, learning phase - poor results expected, don't judge yet
Bars 50-150: Population converging, fitness climbing - results improving
Bars 150-300: Stable performance, most strategies validated - consistent results
Bars 300+: Mature population, optimal genes dominant - best results
Market Condition Dependency:
Trending Markets: AGE excels - clear directional moves, high-probability setups
Choppy Markets: AGE struggles - fewer signals generated, lower win rate
Volatile Markets: AGE cautious - higher rejection rate, wider stops, fewer trades
Market Regime Changes:
When market shifts from trending to choppy overnight
Validated strategies can become temporarily invalidated
AGE will adapt through evolution, but not instantly
Expect 50-100 bar re-learning period after major regime shifts
Fitness may temporarily drop then recover
This is NOT a holy grail. It's a sophisticated signal generator that learns and adapts using genetic algorithms. Your success depends on:
Patience during learning periods (don't abandon after 3 losses)
Proper position sizing (risk 0.5-2% per trade, not 10%)
Following signals consistently (cherry-picking defeats statistical edge)
Not abandoning system prematurely (give it 200+ bars minimum)
Understanding probability (60% win rate means 40% of trades WILL lose)
Respecting market conditions (trending = trade more, choppy = trade less)
Managing emotions (AGE is emotionless, you need to be too)
Expected Drawdowns:
Single-strategy max DD: 10-20% of equity (normal)
Portfolio across multiple instruments: 5-15% (diversification helps)
Losing streaks: 3-5 consecutive losses expected periodically
No indicator eliminates risk. AGE manages risk through:
Quality gates (rejecting low-probability signals)
Confluence requirements (multi-indicator confirmation)
Persistence requirements (no knee-jerk reactions)
Regime awareness (reduced trading in chaos)
Walk-forward validation (preventing overfitting)
But it cannot prevent all losses. That's inherent to trading.
🔧 TECHNICAL SPECIFICATIONS
Platform: TradingView Pine Script v5
Indicator Type: Overlay indicator (plots on price chart)
Execution Type: Signals only - no automatic order placement
Computational Load:
Moderate to High (genetic algorithms + shadow portfolios)
8 strategies × shadow portfolio simulation = significant computation
Premium visuals add additional load (gradient cloud, fitness ribbon)
TradingView Resource Limits (Built-in Caps):
Max Bars Back: 500 (sufficient for WFO and evolution)
Max Labels: 100 (plenty for entry/exit markers)
Max Lines: 150 (adequate for stop/target lines)
Max Boxes: 50 (not heavily used)
Max Polylines: 100 (confidence halos)
Recommended Chart Settings:
Timeframe: 15min to 1H (optimal signal/noise balance)
5min: Works but noisier, more signals
4H/Daily: Works but fewer signals
Bars Loaded: 1000+ (ensures sufficient evolution history)
Replay Mode: Excellent for testing without risk
Performance Optimization Tips:
Disable gradient cloud if chart lags (most CPU intensive visual)
Disable fitness ribbon if still laggy
Reduce cloud layers from 7 to 3
Reduce ribbon layers from 10 to 5
Turn off diagnostics panel unless actively tuning
Close other heavy indicators to free resources
Browser/Platform Compatibility:
Works on all modern browsers (Chrome, Firefox, Safari, Edge)
Mobile app supported (full functionality on phone/tablet)
Desktop app supported (best performance)
Web version supported (may be slower on older computers)
Data Requirements:
Real-time or delayed data both work
No special data feeds required
Works with TradingView's standard data
Historical + live data seamlessly integrated
🎓 THEORETICAL FOUNDATIONS
AGE synthesizes advanced concepts from multiple disciplines:
Evolutionary Computation
Genetic Algorithms (Holland, 1975): Population-based optimization through natural selection metaphor
Tournament Selection: Fitness-based parent selection with diversity preservation
Crossover Operators: Fitness-weighted gene recombination from two parents
Mutation Operators: Random gene perturbation for exploration of new parameter space
Elitism: Preservation of top N performers to prevent loss of best solutions
Adaptive Parameters: Different mutation rates for historical vs. live phases
Technical Analysis
Support/Resistance: Price structure within swing ranges
Trend Following: EMA-based directional bias
Momentum Analysis: RSI, ROC, MACD composite indicators
Volatility Analysis: ATR-based risk scaling
Volume Confirmation: Trade activity validation
Information Theory
Shannon Entropy (1948): Quantification of market order vs. disorder
Signal-to-Noise Ratio: Directional information vs. random walk
Information Content: How much "information" a price move contains
Statistics & Probability
Walk-Forward Analysis: Rolling in-sample/out-of-sample optimization
Out-of-Sample Validation: Testing on unseen data to prevent overfitting
Monte Carlo Principles: Shadow portfolio simulation with realistic execution
Expectancy Theory: Win rate × avg win - loss rate × avg loss
Probability Distributions: Signal confidence quantification
Risk Management
ATR-Based Stops: Volatility-normalized risk per trade
Volatility Regime Detection: Market state classification (trending/choppy/volatile)
Drawdown Control: Peak-to-trough equity measurement
R-Multiple Normalization: Performance measurement in risk units
Machine Learning Concepts
Online Learning: Continuous adaptation as new data arrives
Fitness Functions: Multi-objective optimization (win rate + expectancy + drawdown)
Exploration vs. Exploitation: Balance between trying new strategies and using proven ones
Overfitting Prevention: Walk-forward validation as regularization
Novel Contribution:
AGE is the first TradingView indicator to apply genetic algorithms to real-time indicator parameter optimization while maintaining strict anti-overfitting controls through walk-forward validation.
Most "adaptive" indicators simply recalibrate lookback periods or thresholds. AGE evolves entirely new strategies through competitive selection - it's not parameter tuning, it's Darwinian evolution of trading logic itself.
The combination of:
Genetic algorithm population management
Shadow portfolio simulation for realistic fitness evaluation
Walk-forward validation to prevent overfitting
Multi-indicator confluence for signal quality
Dynamic volatility scaling for adaptive risk
...creates a system that genuinely learns and improves over time while avoiding the curse of curve-fitting that plagues most optimization approaches.
🏗️ DEVELOPMENT NOTES
This project represents months of intensive development, facing significant technical challenges:
Challenge 1: Making Genetics Actually Work
Early versions spawned garbage strategies that polluted the gene pool:
Random gene combinations produced nonsensical parameter sets
Weak strategies survived too long, dragging down population
No clear convergence toward optimal solutions
Solution:
Comprehensive fitness scoring (4 factors: win rate, P&L, expectancy, drawdown)
Elite preservation (top 2 always protected)
Walk-forward validation (unproven strategies penalized 30%)
Tournament selection (fitness-weighted breeding)
Adaptive culling (MAS decay creates increasing selection pressure)
Challenge 2: Balancing Evolution Speed vs. Stability
Too fast = population chaos, no convergence. Too slow = can't adapt to regime changes.
Solution:
Dual-phase timing: Fast evolution during historical (30/60 bar intervals), slow during live (200/400 bar intervals)
Adaptive mutation rates: 20% historical, 8% live
Spawn/cull ratio: Always 2:1 to prevent population collapse
Challenge 3: Shadow Portfolio Accuracy
Needed realistic trade simulation without lookahead bias:
Can't peek at future bars for exits
Must track multiple portfolios simultaneously
Stop/target checks must use bar's high/low correctly
Solution:
Entry on close (realistic)
Exit checks on current bar's high/low (realistic)
Independent position tracking per strategy
Cooldown periods to prevent unrealistic rapid re-entry
ATR-normalized P&L (R-multiples) for fair comparison across volatility regimes
Challenge 4: Pine Script Compilation Limits
Hit TradingView's execution limits multiple times:
Too many array operations
Too many variables
Too complex conditional logic
Solution:
Optimized data structures (single DNA array instead of 8 separate arrays)
Minimal visual overlays (only essential plots)
Efficient fitness calculations (vectorized where possible)
Strategic use of barstate.islast to minimize dashboard updates
Challenge 5: Walk-Forward Implementation
Standard WFO is difficult in Pine Script:
Can't easily "roll forward" through historical data
Can't re-optimize strategies mid-stream
Must work in real-time streaming environment
Solution:
Age-based phase detection (first 250 bars = training, next 75 = testing)
Separate metric tracking for train vs. test
Efficiency calculation at fixed interval (after test period completes)
Validation flag persists for strategy lifetime
Challenge 6: Signal Quality Control
Early versions generated too many signals with poor win rates:
Single indicators produced excessive noise
No trend alignment
No regime awareness
Instant entries on single-bar spikes
Solution:
Three-layer confluence system (entropy + momentum + structure)
Minimum 2-of-3 agreement requirement
Trend alignment checks (penalty for counter-trend)
Regime-based probability adjustments
Persistence requirements (signals must hold multiple bars)
Volume confirmation
Quality gate (probability + confluence thresholds)
The Result
A system that:
Truly evolves (not just parameter sweeps)
Truly validates (out-of-sample testing)
Truly adapts (ongoing competition and breeding)
Stays within TradingView's platform constraints
Provides institutional-quality signals
Maintains transparency (full metrics dashboard)
Development time: 3+ months of iterative refinement
Lines of code: ~1500 (highly optimized)
Test instruments: ES, NQ, EURUSD, BTCUSD, SPY, AAPL
Test timeframes: 5min, 15min, 1H, Daily
🎯 FINAL WORDS
The Adaptive Genesis Engine is not just another indicator - it's a living system that learns, adapts, and improves through the same principles that drive biological evolution. Every bar it observes adds to its experience. Every strategy it spawns explores new parameter combinations. Every strategy it culls removes weakness from the gene pool.
This is evolution in action on your charts.
You're not getting a static formula locked in time. You're getting a system that thinks , that competes , that survives through natural selection. The strongest strategies rise to the top. The weakest die. The gene pool improves generation after generation.
AGE doesn't claim to predict the future - it adapts to whatever the future brings. When markets shift from trending to choppy, from calm to volatile, from bullish to bearish - AGE evolves new strategies suited to the new regime.
Use it on any instrument. Any timeframe. Any market condition. AGE will adapt.
This indicator gives you the pure signal intelligence. How you choose to act on it - position sizing, risk management, execution discipline - that's your responsibility. AGE tells you when and how confident . You decide whether and how much .
Trust the process. Respect the evolution. Let Darwin work.
"In markets, as in nature, it is not the strongest strategies that survive, nor the most intelligent - but those most responsive to change."
Taking you to school. — Dskyz, Trade with insight. Trade with anticipation.
— Happy Holiday's

Indicator ***TuYa*** V8.2 – HH/HL MTF + Peak Mid ZoneIndicator TuYa V8.0 – HH/HL MTF + Peak Mid Zone
TuYa V8.0 combines multi-timeframe market structure with a Peak Reaction midline to create clean, rule-based reversal and trend entries – designed primarily for 1-minute execution with 1-hour bias.
🧠 Core Concept
This indicator fuses three ideas:
HTF Peak Reaction Midline (1H)
Uses a Peak Reaction style logic on the higher timeframe (HTF, default: 1H).
Identifies a reaction high and reaction low, then calculates their midpoint → the Peak Mid Zone.
This midline acts as a dynamic sentiment divider (above = premium / below = discount).
Multi-Timeframe HH/HL/LH/LL Structure
HTF structure (1H): detects HH, HL, LH, LL using pivot highs/lows.
LTF structure (1m): detects HH, HL, LH, LL on the execution timeframe (chart TF, intended for 1m).
HTF → LTF Confirmation Window
After a 1H structure event (HH, HL, LL, LH), the indicator opens a confirmation window of up to N LTF candles (default: 10 x 1m bars).
Within that window, the required 1m structure event must occur to confirm an entry.
🎯 Signal Logic
All entries are generated on the LTF (e.g. 1m chart), using HTF (e.g. 1H) bias + Peak Mid Zone:
1️⃣ Price ABOVE Peak Mid (Bullish premium zone)
Reversal SELL
HTF: HH (Higher High)
Within N 1m bars: LTF HH
→ SELL signal (fading HTF strength near premium)
Trend/Bullish BUY
HTF: HL (Higher Low)
Within N 1m bars: LTF LL
→ BUY signal (buying dips in an uptrend above midline)
2️⃣ Price BELOW Peak Mid (Bearish discount zone)
Reversal BUY
HTF: LL (Lower Low)
Within N 1m bars: LTF LL
→ BUY signal (catching potential reversal from discount)
Trend/Bearish SELL
HTF: LH (Lower High)
Within N 1m bars: LTF HH
→ SELL signal (shorting strength in a downtrend below midline)
Signals are plotted as small BUY/SELL triangles on the chart and exposed via alert conditions.
🧾 Filters & Options
⏳ HTF → LTF Delay Window
Input: “Max 1m bars after HTF trigger” (default: 10)
After a 1H HH/HL/LL/LH event, the indicator waits up to N LTF candles for the matching 1m structure pattern.
If no match occurs within the window, no signal is generated.
📉 RSI No-Trade Zone (HTF)
Toggle: Use RSI no-trade zone
Inputs:
RSI Length (HTF)
No-trade lower bound (default 45)
No-trade upper bound (default 65)
If HTF RSI is inside the defined band (e.g. 45–65), signals are blocked (no-trade regime), helping to avoid noisy mid-range conditions.
You can turn this filter ON/OFF and adjust the band dynamically.
🧱 5m OB / Direction Filter (Optional)
Toggle: Use 5m OB direction filter
Timeframe: Configurable (default: 5m).
Uses a simple directional proxy on the OB timeframe:
For BUY signals → require a bullish candle on OB timeframe.
For SELL signals → require a bearish candle on OB timeframe.
When enabled, this adds an extra layer of confluence by aligning entries with the short-term directional context.
⚙️ Key Inputs (Summary)
Timeframes
HTF (Peak Reaction & Structure): default 60 (1H)
Peak Reaction
Lookback bars (HTF)
ATR multiplier for zones
Show/Hide Peak Mid line
Structure
Pivot left/right bars (for HH/HL/LH/LL swings)
Toggle structure labels (HTF & LTF)
Confirmation
Max LTF bars after HTF trigger (default 10, fully configurable)
RSI Filter
Use filter (on/off)
RSI length
No-trade range (low/high)
5m OB Filter
Use filter (on/off)
OB timeframe (default 5m)
📡 Alerts & Automation
The script includes alertconditions for both BUY and SELL signals, with JSON-formatted alert messages suitable for routing to external bridges (e.g. bots, MT5/MT4, n8n, etc.).
Each alert includes:
Symbol
Side (BUY / SELL)
Price / Entry
SL & TP placeholders (from hidden plots, ready to be wired to your own logic)
Time
Performance tag
CommentCode (for strategy/type tagging on the receiver side)
You can attach these alerts to a webhook and let your execution engine handle SL/TP and order management.
📌 How to Use
Attach the indicator to a 1-minute chart.
Set HTF timeframe to 60 (or your preferred higher timeframe).
Optionally enable:
RSI regime filter
5m OB direction filter
Watch for:
Price relative to the Peak Mid line
BUY/SELL triangles that respect HTF structure + LTF confirmation + filters.
For automation, create alerts using the built-in conditions and your preferred JSON alert template.
⚠️ Disclaimer
This tool is for educational and informational purposes only.
It is not financial advice and does not guarantee profits. Always test thoroughly in replay / paper trading before using with live funds, and trade at your own risk.
BB Breakout-Momentum + Reversion Strategies# BB Breakout-Momentum + Reversion Strategies
## Overview
This indicator combines two complementary Bollinger Band trading strategies that automatically adapt to market conditions. Strategy 1 capitalizes on trending markets with breakout-pullback-momentum setups, while Strategy 2 exploits mean reversion in ranging markets. Advanced filtering using ADX and BB Width ensures each strategy only fires in its optimal market environment.
---
## Strategy 1: Breakout → Pullback → Renewed Momentum (Long B / Short B)
### Best Market Conditions
- **Trending Markets**: ADX ≥ 25
- **High Volatility**: BB Width ≥ 1.0× average
- Directional price action with sustained momentum
### Entry Logic
**Long B (Bullish Breakout):**
1. **Initial Breakout**: Price breaks above upper Bollinger Band with strong momentum
2. **Controlled Pullback**: Price pulls back 1-12 bars but holds above lower band (stays in trend)
3. **Defended Zone**: Pullback creates a support zone based on swing lows (validated by multiple touches)
4. **Renewed Momentum**: Price reclaims with green candle, volume confirmation, bullish MACD
5. **Position Check**: Entry must have cushion below upper band and room to reach targets
**Short B (Bearish Breakdown):**
- Mirror logic for downtrends: breakdown below lower band, pullback stays below upper band, renewed selling pressure
### Risk Management
- **Stop Loss**: Lower of (zone floor/previous low) OR (1.5 × ATR from entry)
- **Targets**:
- T1: Entry + 0.85R (0.85 × 1.5 ATR)
- T2: Entry + 1.40R (1.40 × 1.5 ATR)
- T3: Entry + 2.50R (2.50 × 1.5 ATR)
- T4: Entry + 4.50R (4.50 × 1.5 ATR)
- Risk is calculated using ATR (ATRX = 1.5 ATR), stop uses tighter of structural level (ATRL) or ATRX
---
## Strategy 2: Bollinger Band Mean Reversion (Long R / Short R)
### Best Market Conditions
- **Ranging Markets**: ADX ≤ 20
- **Low Volatility**: BB Width ≤ 0.8× average
- Price oscillating around the mean without sustained trend
### Entry Logic
**Long R (Long Reversion):**
1. **Overextension**: Price breaks below lower Bollinger Band (2 consecutive closes)
2. **Snap Back**: Price crosses back above lower band (re-enters the range)
3. **Entry Window**: Within 2 candles of re-entry, look for:
- **Green candle** (close > open) confirming bullish strength
- Close above previous candle (close > close )
4. **Trigger**: First qualifying candle within 2-bar window executes the trade
**Short R (Short Reversion):**
1. **Overextension**: Price breaks above upper Bollinger Band (2 consecutive closes)
2. **Snap Back**: Price crosses back below upper band (re-enters the range)
3. **Entry Window**: Within 2 candles of re-entry, look for:
- **Red candle** (close < open) confirming bearish pressure
- Close below previous candle (close < close )
4. **Trigger**: First qualifying candle within 2-bar window executes the trade
### Risk Management
- **Stop Loss**: Lower of (previous high/low) OR (1.5 × ATR from entry)
- **Targets**: Same as Strategy 1 (0.85R, 1.4R, 2.5R, 4.5R based on 1.5 ATR)
- Betting on return to Bollinger Band basis (mean)
---
## Advanced Filtering System
### ADX Filter (Average Directional Index)
- **Purpose**: Measures trend strength vs choppy/ranging conditions
- **Trending**: ADX ≥ 25 → Enables Strategy 1 (Breakout)
- **Ranging**: ADX ≤ 20 → Enables Strategy 2 (Reversion)
- **Neutral**: ADX 20-25 → No signals (indecisive market)
### BB Width Filter
- **Purpose**: Confirms volatility expansion/contraction
- **Wide Bands**: Current width ≥ 1.0× 50-bar average → Trending environment
- **Narrow Bands**: Current width ≤ 0.8× 50-bar average → Ranging environment
- **Logic**: Both ADX and BB Width must agree on market state before signaling
### Combined Logic
- **Strategy 1 fires**: When BOTH ADX shows trending AND bands are wide
- **Strategy 2 fires**: When BOTH ADX shows ranging AND bands are narrow
- **Visual Display**: Table at bottom-right shows ADX value, BB Width ratio, and current market state
---
## Visual Elements
### Bollinger Bands
- **Gray line**: 20-period SMA (basis/mean)
- **Green line**: Upper band (basis + 2 standard deviations)
- **Red line**: Lower band (basis - 2 standard deviations)
### Strategy 1 Markers
- **Long B**: Green triangle below bar with "Long B" text
- **Short B**: Orange triangle above bar with "Short B" text
- **Defended Zones**: Green/red boxes showing pullback support/resistance areas
- **Targets**: Green/orange crosses showing T1-T4 and stop loss levels
### Strategy 2 Markers
- **Long R**: Blue label below bar with "Long R" text
- **Short R**: Purple label above bar with "Short R" text
- **Trade Levels**: Horizontal lines extending 50 bars forward
- Blue solid = Entry price
- Red dashed = Stop loss
- Green/Orange dotted = Targets (T1-T4)
### Market State Table
- **ADX**: Current value with color coding (green=trending, orange=ranging, gray=neutral)
- **BB Width**: Ratio vs 50-bar average (e.g., "1.15x" = 15% wider than average)
- **State**: TREND / RANGE / NEUTRAL classification
---
## Settings & Customization
### Bollinger Bands
- **BB Length**: 20 (default) - period for moving average
- **BB Std Dev**: 2.0 (default) - standard deviation multiplier
### ATR & Risk
- **ATR Length**: 14 (default) - period for Average True Range calculation
- All stop losses and targets are derived from 1.5 × ATR
### Trend/Range Filters
- **ADX Length**: 14 (default)
- **ADX Trending Threshold**: 25 (higher = stronger trend required)
- **ADX Ranging Threshold**: 20 (lower = tighter ranging condition)
- **BB Width Average Length**: 50 (period for comparing current width)
- **BB Width Trend Multiplier**: 1.0 (width must be ≥ this × average)
- **BB Width Range Multiplier**: 0.8 (width must be ≤ this × average)
- **Use ADX Filter**: Toggle on/off
- **Use BB Width Filter**: Toggle on/off
### Strategy 1 (Breakout-Momentum)
- **Breakout Lookback**: 15 bars (how far back to search for initial breakout)
- **Min Pullback Bars**: 1 (minimum consolidation period)
- **Max Pullback Bars**: 12 (maximum consolidation period)
- **Show Defended Zone**: Display support/resistance boxes
- **Show Signals**: Display Long B / Short B markers
- **Show Targets**: Display stop loss and target levels
### Strategy 2 (Reversion)
- **Show Signals**: Display Long R / Short R markers
- **Show Trade Levels**: Display entry, stop, and target lines
---
## How to Use This Indicator
### Step 1: Identify Market State
- Check the table in bottom-right corner
- **TREND**: Look for Strategy 1 signals (Long B / Short B)
- **RANGE**: Look for Strategy 2 signals (Long R / Short R)
- **NEUTRAL**: Wait for clearer conditions
### Step 2: Wait for Signal
- Signals only fire when ALL conditions are met (structural + momentum + filters + room-to-target)
- Signals are relatively rare but high-probability
### Step 3: Execute Trade
- **Entry**: Close of signal candle
- **Stop Loss**: Shown as red cross (Strategy 1) or red dashed line (Strategy 2)
- **Targets**: Scale out at T1, T2, T3, T4 or hold for maximum R:R
### Step 4: Management
- Consider moving stop to breakeven after T1
- Trail stop using swing lows/highs in Strategy 1
- Exit full position at T2-T3 in Strategy 2 (mean reversion has limited upside)
---
## Key Principles
### Why This Works
1. **Market Adaptation**: Uses right strategy for right conditions (trend vs range)
2. **Confluence**: Multiple confirmations required (structure + momentum + volatility + room)
3. **Risk-Defined**: Every trade has pre-calculated stop and targets based on ATR
4. **Probability**: Filters reduce noise and increase win rate by waiting for ideal setups
### Common Pitfalls to Avoid
- ❌ Taking signals in NEUTRAL market state (indicators disagree)
- ❌ Overriding the stop loss (it's calculated for a reason)
- ❌ Expecting signals on every swing (quality over quantity)
- ❌ Using Strategy 1 in ranging markets or Strategy 2 in trending markets
- ❌ Ignoring the room-to-target check (signal won't fire if targets are blocked)
### Complementary Analysis
This indicator works best when combined with:
- Higher timeframe trend analysis
- Key support/resistance levels
- Volume analysis
- Market structure (swing highs/lows)
- Risk management rules (position sizing, max daily loss, etc.)
---
## Technical Details
### Indicators Used
- **Bollinger Bands**: 20-period SMA ± 2 standard deviations
- **ATR**: 14-period Average True Range for volatility measurement
- **ADX**: 14-period Average Directional Index for trend strength
- **EMA**: 10 and 20-period exponential moving averages (Strategy 1 filter)
- **MACD**: 12/26/9 settings (Strategy 1 momentum confirmation)
- **Volume**: Compared to 15-bar average (Strategy 1 confirmation)
### Calculation Methodology
- **ATRL** (Structural Risk): Previous swing high/low or defended zone boundary
- **ATRX** (ATR Risk): 1.5 × 14-period ATR from entry price
- **Stop Loss**: Minimum of ATRL and ATRX (tightest protection)
- **Targets**: Always calculated from ATRX (consistent R-multiples)
- **BB Width Ratio**: Current BB width ÷ 50-period SMA of BB width
---
## Performance Notes
### Strengths
- Adapts to changing market conditions automatically
- Clear, objective entry and exit criteria
- Pre-defined risk on every trade
- Filters reduce false signals significantly
- Works across multiple timeframes and instruments
### Limitations
- Signals are infrequent (by design - quality over quantity)
- Requires patience to wait for all conditions to align
- May miss explosive moves if pullback doesn't form properly (Strategy 1)
- Ranging markets can transition to trending (Strategy 2 risk)
- Filters may delay entry in fast-moving markets
### Best Timeframes
- **Strategy 1**: 1H, 4H, Daily (needs time for proper pullback structure)
- **Strategy 2**: 15M, 30M, 1H (mean reversion works best intraday)
- Both strategies can work on any timeframe if market conditions are right
### Best Instruments
- **Liquid markets**: Major stocks, indices, forex pairs, liquid crypto
- **Sufficient volatility**: ATR should be meaningful relative to price
- **Clear trend/range cycles**: Markets that respect technical levels
---
## IMPORTANT DISCLAIMER
### Risk Warning
**TRADING INVOLVES SUBSTANTIAL RISK OF LOSS AND IS NOT SUITABLE FOR ALL INVESTORS.**
This indicator is provided for **educational and informational purposes only**. It does not constitute financial advice, investment advice, trading advice, or any other sort of advice. You should not treat any of the indicator's content as such.
### No Guarantee of Profit
Past performance is not indicative of future results. No trading strategy, including this indicator, can guarantee profits or protect against losses. The market is inherently unpredictable and all trading involves risk.
### User Responsibility
- **Do Your Own Research**: Always conduct your own analysis before making trading decisions
- **Test First**: Backtest and paper trade this strategy before risking real capital
- **Risk Management**: Never risk more than you can afford to lose
- **Position Sizing**: Use appropriate position sizes relative to your account
- **Stop Losses**: Always use stop losses and respect them
- **Market Conditions**: Understand that market conditions change and past behavior may not repeat
### No Liability
The creator of this indicator accepts no liability for any financial losses incurred through the use of this tool. All trading decisions are made at your own risk. You are solely responsible for evaluating the merits and risks associated with the use of any trading systems, signals, or content provided.
### Not Financial Advice
This indicator does not take into account your personal financial situation, investment objectives, risk tolerance, or specific needs. You should consult with a licensed financial advisor before making any investment decisions.
### Technical Limitations
- Indicators can repaint or lag in real-time
- Past signals may look different than real-time signals
- Code bugs or errors may exist despite testing
- TradingView platform limitations may affect functionality
### Market Risks
- Markets can gap, causing stops to be executed at worse prices
- Slippage and commissions can significantly impact results
- High volatility can cause unexpected losses
- Counterparty risk exists in all leveraged products
---
## Version History
- **v1.0**: Initial release combining breakout-momentum and mean reversion strategies
- Includes ADX and BB Width filtering
- ATRL/ATRX risk calculation system
- 2-candle entry window for reversion trades
---
## Credits & License
This indicator combines concepts from classical technical analysis including Bollinger Bands (John Bollinger), ATR (Welles Wilder), and ADX (Welles Wilder). The specific implementation and combination of filters is original work.
**Use at your own risk. Trade responsibly.**
---
*For questions, suggestions, or to report bugs, please comment below or contact the author.*
**Remember: The best indicator is the one between your ears. Use this tool as part of a comprehensive trading plan, not as a standalone solution.**

MFI Volume Profile [Kodexius]The MFI Volume Profile indicator blends a classic volume profile with the Money Flow Index so you can see not only where volume traded, but also how strong the buying or selling pressure was at those prices. Instead of showing a simple horizontal histogram of volume, this tool adds a money flow dimension and turns the profile into a price volume momentum heat map.
The script scans a user controlled lookback window and builds a set of price levels between the lowest and highest price in that period. For every bar inside that window, its volume is distributed across the price levels that the bar actually touched, and that volume is combined with the bar’s MFI value. This creates a volume weighted average MFI for each price level, so every row of the profile knows both how much volume traded there and what the typical money flow condition was when that volume appeared.
On the chart, the indicator plots a stack of horizontal boxes to the right of current price. The length of each box represents the relative amount of volume at that price, while the color represents the average MFI there. Levels with stronger positive money flow will lean toward warmer shades, and levels with weaker or negative money flow will lean toward cooler or more neutral shades inside the configured MFI band. Each row is also labeled in the format Volume , so you can instantly read the exact volume and money flow value at that level instead of guessing.
This gives you a detailed map of where the market really cared about price, and whether that interest came with strong inflow or outflow. It can help you spot areas of accumulation, distribution, absorption, or exhaustion, and it does so in a compact visual that sits next to price without cluttering the candles themselves.
Features
Combined volume profile and MFI weighting
The indicator builds a volume profile over a user selected lookback and enriches each price row with a volume weighted average MFI. This lets you study both participation and money flow at the same price level.
Volume distributed across the bar price range
For every bar in the window, volume is not assigned to a single price. Instead, it is proportionally distributed across all price rows between the bar low and bar high. This creates a smoother and more realistic profile of where trading actually happened.
MFI based color gradient between 30 and 70
Each price row is colored according to its average MFI. The gradient is anchored between MFI values of 30 and 70, which covers typical oversold, neutral and overbought zones. This makes strong demand or distribution areas easier to spot visually.
Configurable structure resolution and depth
Main user inputs are the lookback length, the number of rows, the width of the profile in bars, and the label text size. You can quickly switch between coarse profiles for a big picture and higher resolution profiles for detailed structure.
Numeric labels with volume and MFI per row
Every box is labeled with the total volume at that level and the average MFI for that level, in the format Volume . This gives you exact values while still keeping the visual profile clean and compact.
Calculations
Money Flow Index calculation
currentMfi is calculated once using ta.mfi(hlc3, mfiLen) as usual,
Creation of the profileBins array
The script creates an array named profileBins that will hold one VPBin element per price row.
Each VPBin contains
volume which is the total volume accumulated at that price row
mfiProduct which is the sum of volume multiplied by MFI for that row
The loop;
for i = 0 to rowCount - 1 by 1
array.push(profileBins, VPBin.new(0.0, 0.0))
pre allocates a clean structure with zero values for all rows.
Finding highest and lowest price across the lookback
The script starts from the current bar high and low, then walks backward through the lookback window
for i = 0 to lookback - 1 by 1
highestPrice := math.max(highestPrice, high )
lowestPrice := math.min(lowestPrice, low )
After this loop, highestPrice and lowestPrice define the full price range covered by the chosen lookback.
Price range and step size for rows
The code computes
float rangePrice = highestPrice - lowestPrice
rangePrice := rangePrice == 0 ? syminfo.mintick : rangePrice
float step = rangePrice / rowCount
rangePrice is the total height of the profile in price terms. If the range is zero, the script replaces it with the minimum tick size for the symbol. Then step is the price height of each row. This step size is used to map any price into a row index.
Processing each bar in the lookback
For every bar index i inside the lookback, the script checks that currentMfi is not missing. If it is valid, it reads the bar high, low, volume and MFI
float barTop = high
float barBottom = low
float barVol = volume
float barMfi = currentMfi
Mapping bar prices to bin indices
The bar high and low are converted into row indices using the known lowestPrice and step
int indexTop = math.floor((barTop - lowestPrice) / step)
int indexBottom = math.floor((barBottom - lowestPrice) / step)
Then the indices are clamped into valid bounds so they stay between zero and rowCount - 1. This ensures that every bar contributes only inside the profile range
Splitting bar volume across all covered bins
Once the top and bottom indices are known, the script calculates how many rows the bar spans
int coveredBins = indexTop - indexBottom + 1
float volPerBin = barVol / coveredBins
float mfiPerBin = volPerBin * barMfi
Here the total bar volume is divided equally across all rows that the bar touches. For each of those rows, the same fraction of volume and volume times MFI is used.
Accumulating into each VPBin
Finally, a nested loop iterates from indexBottom to indexTop and updates the corresponding VPBin
for k = indexBottom to indexTop by 1
VPBin binData = array.get(profileBins, k)
binData.volume := binData.volume + volPerBin
binData.mfiProduct := binData.mfiProduct + mfiPerBin
Over all bars in the lookback window, each row builds up
total volume at that price range
total volume times MFI at that price range
Later, during the drawing stage, the script computes
avgMfi = bin.mfiProduct / bin.volume
for each row. This is the volume weighted average MFI used both for coloring the box and for the numeric MFI value shown in the label Volume .

Hyper SAR Reactor Trend StrategyHyperSAR Reactor Adaptive PSAR Strategy
Summary
Adaptive Parabolic SAR strategy for liquid stocks, ETFs, futures, and crypto across intraday to daily timeframes. It acts only when an adaptive trail flips and confirmation gates agree. Originality comes from a logistic boost of the SAR acceleration using drift versus ATR, plus ATR hysteresis, inertia on the trail, and a bear-only gate for shorts. Add to a clean chart and run on bar close for conservative alerts.
Scope and intent
• Markets: large cap equities and ETFs, index futures, major FX, liquid crypto
• Timeframes: one minute to daily
• Default demo: BTC on 60 minute
• Purpose: faster yet calmer PSAR that resists chop and improves short discipline
• Limits: this is a strategy that places simulated orders on standard candles
Originality and usefulness
• Novel fusion: PSAR AF is boosted by a logistic function of normalized drift, trail is monotone with inertia, entries use ATR buffers and optional cooldown, shorts are allowed only in a bear bias
• Addresses false flips in low volatility and weak downtrends
• All controls are exposed in Inputs for testability
• Yardstick: ATR normalizes drift so settings port across symbols
• Open source. No links. No solicitation
Method overview
Components
• Adaptive AF: base step plus boost factor times logistic strength
• Trail inertia: one sided blend that keeps the SAR monotone
• Flip hysteresis: price must clear SAR by a buffer times ATR
• Volatility gate: ATR over its mean must exceed a ratio
• Bear bias for shorts: price below EMA of length 91 with negative slope window 54
• Cooldown bars optional after any entry
• Visual SAR smoothing is cosmetic and does not drive orders
Fusion rule
Entry requires the internal flip plus all enabled gates. No weighted scores.
Signal rule
• Long when trend flips up and close is above SAR plus buffer times ATR and gates pass
• Short when trend flips down and close is below SAR minus buffer times ATR and gates pass
• Exit uses SAR as stop and optional ATR take profit per side
Inputs with guidance
Reactor Engine
• Start AF 0.02. Lower slows new trends. Higher reacts quicker
• Max AF 1. Typical 0.2 to 1. Caps acceleration
• Base step 0.04. Typical 0.01 to 0.08. Raises speed in trends
• Strength window 18. Typical 10 to 40. Drift estimation window
• ATR length 16. Typical 10 to 30. Volatility unit
• Strength gain 4.5. Typical 2 to 6. Steepness of logistic
• Strength center 0.45. Typical 0.3 to 0.8. Midpoint of logistic
• Boost factor 0.03. Typical 0.01 to 0.08. Adds to step when strength rises
• AF smoothing 0.50. Typical 0.2 to 0.7. Adds inertia to AF growth
• Trail smoothing 0.35. Typical 0.15 to 0.45. Adds inertia to the trail
• Allow Long, Allow Short toggles
Trade Filters
• Flip confirm buffer ATR 0.50. Typical 0.2 to 0.8. Raise to cut flips
• Cooldown bars after entry 0. Typical 0 to 8. Blocks re entry for N bars
• Vol gate length 30 and Vol gate ratio 1. Raise ratio to trade only in active regimes
• Gate shorts by bear regime ON. Bear bias window 54 and Bias MA length 91 tune strictness
Risk
• TP long ATR 1.0. Set to zero to disable
• TP short ATR 0.0. Set to 0.8 to 1.2 for quicker shorts
Usage recipes
Intraday trend focus
Confirm buffer 0.35 to 0.5. Cooldown 2 to 4. Vol gate ratio 1.1. Shorts gated by bear regime.
Intraday mean reversion focus
Confirm buffer 0.6 to 0.8. Cooldown 4 to 6. Lower boost factor. Leave shorts gated.
Swing continuation
Strength window 24 to 34. ATR length 20 to 30. Confirm buffer 0.4 to 0.6. Use daily or four hour charts.
Properties visible in this publication
Initial capital 10000. Base currency USD. Order size Percent of equity 3. Pyramiding 0. Commission 0.05 percent. Slippage 5 ticks. Process orders on close OFF. Bar magnifier OFF. Recalculate after order filled OFF. Calc on every tick OFF. No security calls.
Realism and responsible publication
No performance claims. Past results never guarantee future outcomes. Shapes can move while a bar forms and settle on close. Strategies execute only on standard candles.
Honest limitations and failure modes
High impact events and thin books can void assumptions. Gap heavy symbols may prefer longer ATR. Very quiet regimes can reduce contrast and invite false flips.
Open source reuse and credits
Public domain building blocks used: PSAR concept and ATR. Implementation and fusion are original. No borrowed code from other authors.
Strategy notice
Orders are simulated on standard candles. No lookahead.
Entries and exits
Long: flip up plus ATR buffer and all gates true
Short: flip down plus ATR buffer and gates true with bear bias when enabled
Exit: SAR stop per side, optional ATR take profit, optional cooldown after entry
Tie handling: stop first if both stop and target could fill in one bar
Savitzky-Golay Hampel Filter | AlphaNattSavitzky-Golay Hampel Filter | AlphaNatt
A revolutionary indicator combining NASA's satellite data processing algorithms with robust statistical outlier detection to create the most scientifically advanced trend filter available on TradingView.
"This is the same mathematics that processes signals from the Hubble Space Telescope and analyzes data from the Large Hadron Collider - now applied to financial markets."
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
🚀 SCIENTIFIC PEDIGREE
Savitzky-Golay Filter Applications:
NASA: Satellite telemetry and space probe data processing
CERN: Particle physics data analysis at the LHC
Pharmaceutical: Chromatography and spectroscopy analysis
Astronomy: Processing signals from radio telescopes
Medical: ECG and EEG signal processing
Hampel Filter Usage:
Aerospace: Cleaning sensor data from aircraft and spacecraft
Manufacturing: Quality control in precision engineering
Seismology: Earthquake detection and analysis
Robotics: Sensor fusion and noise reduction
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
🧬 THE MATHEMATICS
1. Savitzky-Golay Filter
The SG filter performs local polynomial regression on data points:
Fits a polynomial of degree n to a sliding window of data
Evaluates the polynomial at the center point
Preserves higher moments (peaks, valleys) unlike moving averages
Maintains derivative information for true momentum analysis
Originally published in Analytical Chemistry (1964)
Mathematical Properties:
Optimal smoothing in the least-squares sense
Preserves statistical moments up to polynomial order
Exact derivative calculation without additional lag
Superior frequency response vs traditional filters
2. Hampel Filter
A robust outlier detector based on Median Absolute Deviation (MAD):
Identifies outliers using robust statistics
Replaces spurious values with polynomial-fitted estimates
Resistant to up to 50% contaminated data
MAD is 1.4826 times more robust than standard deviation
Outlier Detection Formula:
|x - median| > k × 1.4826 × MAD
Where k is the threshold parameter (typically 3 for 99.7% confidence)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
💎 WHY THIS IS SUPERIOR
vs Moving Averages:
Preserves peaks and valleys (critical for catching tops/bottoms)
No lag penalty for smoothness
Maintains derivative information
Polynomial fitting > simple averaging
vs Other Filters:
Outlier immunity (Hampel component)
Scientifically optimal smoothing
Preserves higher-order features
Used in billion-dollar research projects
Unique Advantages:
Feature Preservation: Maintains market structure while smoothing
Spike Immunity: Ignores false breakouts and stop hunts
Derivative Accuracy: True momentum without additional indicators
Scientific Validation: 60+ years of academic research
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
⚙️ PARAMETER OPTIMIZATION
1. Polynomial Order (2-5)
2 (Quadratic): Maximum smoothing, gentle curves
3 (Cubic): Balanced smoothing and responsiveness (recommended)
4-5 (Higher): More responsive, preserves more features
2. Window Size (7-51)
Must be odd number
Larger = smoother but more lag
Formula: 2×(desired smoothing period) + 1
Default 21 = analyzes 10 bars each side
3. Hampel Threshold (1.0-5.0)
1.0: Aggressive outlier removal (68% confidence)
2.0: Moderate outlier removal (95% confidence)
3.0: Conservative outlier removal (99.7% confidence) (default)
4.0+: Only extreme outliers removed
4. Final Smoothing (1-7)
Additional WMA smoothing after filtering
1 = No additional smoothing
3-5 = Recommended for most timeframes
7 = Ultra-smooth for position trading
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📊 TRADING STRATEGIES
Signal Recognition:
Cyan Line: Bullish trend with positive derivative
Pink Line: Bearish trend with negative derivative
Color Change: Trend reversal with polynomial confirmation
1. Trend Following Strategy
Enter when price crosses above cyan filter
Exit when filter turns pink
Use filter as dynamic stop loss
Best in trending markets
2. Mean Reversion Strategy
Enter long when price touches filter from below in uptrend
Enter short when price touches filter from above in downtrend
Exit at opposite band or filter color change
Excellent for range-bound markets
3. Derivative Strategy (Advanced)
The SG filter preserves derivative information
Acceleration = second derivative > 0
Enter on positive first derivative + positive acceleration
Exit on negative second derivative (momentum slowing)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📈 PERFORMANCE CHARACTERISTICS
Strengths:
Outlier Immunity: Ignores stop hunts and flash crashes
Feature Preservation: Catches tops/bottoms better than MAs
Smooth Output: Reduces whipsaws significantly
Scientific Basis: Not curve-fitted or optimized to markets
Considerations:
Slight lag in extreme volatility (all filters have this)
Requires odd window sizes (mathematical requirement)
More complex than simple moving averages
Best with liquid instruments
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
🔬 SCIENTIFIC BACKGROUND
Savitzky-Golay Publication:
"Smoothing and Differentiation of Data by Simplified Least Squares Procedures"
- Abraham Savitzky & Marcel Golay
- Analytical Chemistry, Vol. 36, No. 8, 1964
Hampel Filter Origin:
"Robust Statistics: The Approach Based on Influence Functions"
- Frank Hampel et al., 1986
- Princeton University Press
These techniques have been validated in thousands of scientific papers and are standard tools in:
NASA's Jet Propulsion Laboratory
European Space Agency
CERN (Large Hadron Collider)
MIT Lincoln Laboratory
Max Planck Institutes
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
💡 ADVANCED TIPS
News Trading: Lower Hampel threshold before major events to catch spikes
Scalping: Use Order=2 for maximum smoothness, Window=11 for responsiveness
Position Trading: Increase Window to 31+ for long-term trends
Combine with Volume: Strong trends need volume confirmation
Multiple Timeframes: Use daily for trend, hourly for entry
Watch the Derivative: Filter color changes when first derivative changes sign
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
⚠️ IMPORTANT NOTICES
Not financial advice - educational purposes only
Past performance does not guarantee future results
Always use proper risk management
Test settings on your specific instrument and timeframe
No indicator is perfect - part of complete trading system
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
🏆 CONCLUSION
The Savitzky-Golay Hampel Filter represents the pinnacle of scientific signal processing applied to financial markets. By combining polynomial regression with robust outlier detection, traders gain access to the same mathematical tools that:
Guide spacecraft to other planets
Detect gravitational waves from black holes
Analyze particle collisions at near light-speed
Process signals from deep space
This isn't just another indicator - it's rocket science for trading .
"When NASA needs to separate signal from noise in billion-dollar missions, they use these exact algorithms. Now you can too."
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Developed by AlphaNatt
Version: 1.0
Release: 2025
Pine Script: v6
"Where Space Technology Meets Market Analysis"
Not financial advice. Always DYOR
Dual Volume Profiles: Session + Rolling (Range Delineation)Dual Volume Profiles: Session + Rolling (Range Delineation)
INTRO
This is a probability-centric take on volume profile. I treat the volume histogram as an empirical PDF over price, updated in real time, which makes multi-modality (multiple acceptance basins) explicit rather than assumed away. The immediate benefit is operational: if we can read the shape of the distribution, we can infer likely reversion levels (POC), acceptance boundaries (VAH/VAL), and low-friction corridors (LVNs).
My working hypothesis is that what traders often label “fat tails” or “power-law behavior” at short horizons is frequently a tail-conditioned view of a higher-level Gaussian regime. In other words, child distributions (shorter periodicities) sit within parent distributions (longer periodicities); when price operates in the parent’s tail, the child regime looks heavy-tailed without being fundamentally non-Gaussian. This is consistent with a hierarchical/mixture view and with the spirit of the central limit theorem—Gaussian structure emerges at aggregate scales, while local scales can look non-Gaussian due to nesting and conditioning.
This indicator operationalizes that view by plotting two nested empirical PDFs: a rolling (local) profile and a session-anchored profile. Their confluence makes ranges explicit and turns “regime” into something you can see. For additional nesting, run multiple instances with different lookbacks. When using the default settings combined with a separate daily VP, you effectively get three nested distributions (local → session → daily) on the chart.
This indicator plots two nested distributions side-by-side:
Rolling (Local) Profile — short-window, prorated histogram that “breathes” with price and maps the immediate auction.
Session Anchored Profile — cumulative distribution since the current session start (Premkt → RTH → AH anchoring), revealing the parent regime.
Use their confluence to identify range floors/ceilings, mean-reversion magnets, and low-volume “air pockets” for fast traverses.
What it shows
POC (dashed): central tendency / “magnet” (highest-volume bin).
VAH & VAL (solid): acceptance boundaries enclosing an exact Value Area % around each profile’s POC.
Volume histograms:
Rolling can auto-color by buy/sell dominance over the lookback (green = buying ≥ selling, red = selling > buying).
Session uses a fixed style (blue by default).
Session anchoring (exchange timezone):
Premarket → anchors at 00:00 (midnight).
RTH → anchors at 09:30.
After-hours → anchors at 16:00.
Session display span:
Session Max Span (bars) = 0 → draw from session start → now (anchored).
> 0 → draw a rolling window N bars back → now, while still measuring all volume since session start.
Why it’s useful
Think in terms of nested probability distributions: the rolling node is your local Gaussian; the session node is its parent.
VA↔VA overlap ≈ strong range boundary.
POC↔POC alignment ≈ reliable mean-reversion target.
LVNs (gaps) ≈ low-friction corridors—expect quick moves to the next node.
Quick start
Add to chart (great on 5–10s, 15–60s, 1–5m).
Start with: bins = 240, vaPct = 0.68, barsBack = 60.
Watch for:
First test & rejection at overlapping VALs/VAHs → fade back toward POC.
Acceptance beyond VA (several closes + growing outer-bin mass) → traverse to the next node.
Inputs (detailed)
General
Lookback Bars (Rolling)
Count of most-recent bars for the rolling/local histogram. Larger = smoother node that shifts slower; smaller = more reactive, “breathing” profile.
• Typical: 40–80 on 5–10s charts; 60–120 on 1–5m.
• If you increase this but keep Number of Bins fixed, each bin aggregates more volume (coarser bins).
Number of Bins
Vertical resolution (price buckets) for both rolling and session histograms. Higher = finer detail and crisper LVNs, but more line objects (closer to platform limits).
• Typical: 120–240 on 5–10s; 80–160 on 1–5m.
• If you hit performance or object limits, reduce this first.
Value Area %
Exact central coverage for VAH/VAL around POC. Computed empirically from the histogram (no Gaussian assumption): the algorithm expands from POC outward until the chosen % is enclosed.
• Common: 0.68 (≈“1σ-like”), 0.70 for slightly wider core.
• Smaller = tighter VA (more breakout flags). Larger = wider VA (more reversion bias).
Max Local Profile Width (px)
Horizontal length (in pixels) of the rolling bars/lines and its VA/POC overlays. Visual only (does not affect calculations).
Session Settings
RTH Start/End (exchange tz)
Defines the current session anchor (Premkt=00:00, RTH=your start, AH=your end). The session histogram always measures from the most recent session start and resets at each boundary.
Session Max Span (bars, 0 = full session)
Display window for session drawings (POC/VA/Histogram).
• 0 → draw from session start → now (anchored).
• > 0 → draw N bars back → now (rolling look), while still measuring all volume since session start.
This keeps the “parent” distribution measurable while letting the display track current action.
Local (Rolling) — Visibility
Show Local Profile Bars / POC / VAH & VAL
Toggle each overlay independently. If you approach object limits, disable bars first (POC/VA lines are lighter).
Local (Rolling) — Colors & Widths
Color by Buy/Sell Dominance
Fast uptick/downtick proxy over the rolling window (close vs open):
• Buying ≥ Selling → Bullish Color (default lime).
• Selling > Buying → Bearish Color (default red).
This color drives local bars, local POC, and local VA lines.
• Disable to use fixed Bars Color / POC Color / VA Lines Color.
Bars Transparency (0–100) — alpha for the local histogram (higher = lighter).
Bars Line Width (thickness) — draw thin-line profiles or chunky blocks.
POC Line Width / VA Lines Width — overlay thickness. POC is dashed, VAH/VAL solid by design.
Session — Visibility
Show Session Profile Bars / POC / VAH & VAL
Independent toggles for the session layer.
Session — Colors & Widths
Bars/POC/VA Colors & Line Widths
Fixed palette by design (default blue). These do not change with buy/sell dominance.
• Use transparency and width to make the parent profile prominent or subtle.
• Prefer minimal? Hide session bars; keep only session VA/POC.
Reading the signals (detailed playbook)
Core definitions
POC — highest-volume bin (fair price “magnet”).
VAH/VAL — upper/lower bounds enclosing your Value Area % around POC.
Node — contiguous block of high-volume bins (acceptance).
LVN — low-volume gap between nodes (low friction path).
Rejection vs Acceptance (practical rule)
Rejection at VA edge: 0–1 closes beyond VA and no persistent growth in outer bins.
Acceptance beyond VA: ≥3 closes beyond VA and outer-bin mass grows (e.g., added volume beyond the VA edge ≥ 5–10% of node volume over the last N bars). Treat acceptance as regime change.
Confluence scores (make boundary/target quality objective)
VA overlap strength (range boundary):
C_VA = 1 − |VA_edge_local − VA_edge_session| / ATR(n)
Values near 1.0 = tight overlap (stronger boundary).
Use: if C_VA ≥ 0.6–0.8, treat as high-quality fade zone.
POC alignment (magnet quality):
C_POC = 1 − |POC_local − POC_session| / ATR(n)
Higher C_POC = greater chance a rotation completes to that fair price.
(You can estimate these by eye.)
Setups
1) Range Fade at VA Confluence (mean reversion)
Context: Local VAL/VAH near Session VAL/VAH (tight overlap), clear node, local color not screaming trend (or flips to your side).
Entry: First test & rejection at the overlapped band (wick through ok; prefer close back inside).
Stop: A tick/pip beyond the wider of the two VA edges or beyond the nearest LVN, a small buffer zone can be used to judge whether price is truly rejecting a VAL/VAH or simply probing.
Targets: T1 node mid; T2 POC (size up when C_POC is high).
Flip: If acceptance (rule above) prints, flip bias or stand down.
2) LVN Traverse (continuation)
Context: Price exits VA and enters an LVN with acceptance and growing outer-bin volume.
Entry: Aggressive—first close into LVN; Conservative—retest of the VA edge from the far side (“kiss goodbye”).
Stop: Back inside the prior VA.
Targets: Next node’s VA edge or POC (edge = faster exits; POC = fuller rotations).
Note: Flatter VA edge (shallower curvature) tends to breach more easily.
3) POC→POC Magnet Trade (rotation completion)
Context: Local POC ≈ Session POC (high C_POC).
Entry: Fade a VA touch or pullback inside node, aiming toward the shared POC.
Stop: Past the opposite VA edge or LVN beyond.
Target: The shared POC; optional runner to opposite VA if the node is broad and time-of-day is supportive.
4) Failed Break (Reversion Snap-back)
Context: Push beyond VA fails acceptance (re-enters VA, outer-bin growth stalls/shrinks).
Entry: On the re-entry close, back toward POC.
Stop/Target: Stop just beyond the failed VA; target POC, then opposite VA if momentum persists.
How to read color & shape
Local color = most recent sentiment:
Green = buying ≥ selling; Red = selling > buying (over the rolling window). Treat as context, not a standalone signal. A green local node under a blue session VAH can still be a fade if the parent says “over-valued.”
Shape tells friction:
Fat nodes → rotation-friendly (fade edges).
Sharp LVN gaps → traversal-friendly (momentum continuation).
Time-of-day intuition
Right after session anchor (e.g., RTH 09:30): Session profile is young and moves quickly—treat confluence cautiously.
Mid-session: Cleanest behavior for rotations.
Close / news: Expect more traverses and POC migrations; tighten risk or switch playbooks.
Risk & execution guidance
Use tight, mechanical stops at/just beyond VA or LVN. If you need wide stops to survive noise, your entry is late or the node is unstable.
On micro-timeframes, account for fees & slippage—aim for targets paying ≥2–3× average cost.
If acceptance prints, don’t fight it—flip, reduce size, or stand aside.
Suggested presets
Scalp (5–10s): bins 120–240, barsBack 40–80, vaPct 0.68–0.70, local bars thin (small bar width).
Intraday (1–5m): bins 80–160, barsBack 60–120, vaPct 0.68–0.75, session bars more visible for parent context.
Performance & limits
Reuses line objects to stay under TradingView’s max_lines_count.
Very large bins × multiple overlays can still hit limits—use visibility toggles (hide bars first).
Session drawings use time-based coordinates to avoid “bar index too far” errors.
Known nuances
Rolling buy/sell dominance uses a simple uptick/downtick proxy (close vs open). It’s fast and practical, but it’s not a full tape classifier.
VA boundaries are computed from the empirical histogram—no Gaussian assumption.
This script does not calculate the full daily volume profile. Several other tools already provide that, including TradingView’s built-in Volume Profile indicators. Instead, this indicator focuses on pairing a rolling, short-term volume distribution with a session-wide distribution to make ranges more explicit. It is designed to supplement your use of standard or periodic volume profiles, not replace them. Think of it as a magnifying lens that helps you see where local structure aligns with the broader session.
How to trade it (TL;DR)
Fade overlapping VA bands on first rejection → target POC.
Continue through LVN on acceptance beyond VA → target next node’s VA/POC.
Respect acceptance: ≥3 closes beyond VA + growing outer-bin volume = regime change.
FAQ
Q: Why 68% Value Area?
A: It mirrors the “~1σ” idea, but we compute it exactly from empirical volume, not by assuming a normal distribution.
Q: Why are my profiles thin lines?
A: Increase Bars Line Width for chunkier blocks; reduce for fine, thin-line profiles.
Q: Session bars don’t reach session start—why?
A: Set Session Max Span (bars) = 0 for full anchoring; any positive value draws a rolling window while still measuring from session start.
Changelog (v1.0)
Dual profiles: Rolling + Session with independent POC/VA lines.
Session anchoring (Premkt/RTH/AH) with optional rolling display span.
Dynamic coloring for the rolling profile (buying vs selling).
Fully modular toggles + per-feature colors/widths.
Thin-line rendering via bar line width.

Autofib Extensions | DTDHello trader comuunity!
I'm introducing another script that is part of my main day-trading strategy. We all know regardless of what strategy we use, we need to know what levels offer the least amount of risk to our trade entry and a great tool to anticipate how far a move might go or what level a move may retrace to are the Fibonacci Retracement and Extensions. This indicator combines both together, but with a twist.
The main elements of the script are:
1. Multiple Session High and Lows | Developing my first script led me to understand that measuring key times during each session provides understanding of the market's continuity. I have provided 3 "sessions' a user can define according to CST time where the script saves the high and low of that session window to produce the retracement and extensions from those plots. Currently, the levels are always plotted from low to high (with the 0 mark being the high) and negative values provided so the levels are consistent. You can toggle each session on or off.
2. Coloring Key Retracements / Extensions | I use a dark background for my charts so the default colors help me distinguish from other another indicator I use. Feel free to adjust the colors to your preference. I consider 3 different colors because of their significance. Retracements that you want to see continue fall back into the .50 to .618 level (this I consider the "Golden Zone"). While basic Elliott Wave Theory states a wave is completed near the 1.618 level (this I consider "Major Extensions"). Everything isn't noise, but minor levels in a larger sequence.
______________
Script Limitations
All of my scripts are made with the help of ChatGPT so there are going to be limitations. One current one that I have made progress on, but not fully is when you are viewing a timeframe where the candle doesn't start when a session window starts. On smaller timeframes like the 7-minute this is not an issue. However, on the hourly, if your session window starts at the half hour which the 3rd session default window does, the lines will not produce. I will hopefully have this rectified in the near future. I will open the script since none of this work is original in nature and I would love to see how others can create a better product. Also, this is mainly a futures trading tool. If you are using this on stocks you will find it not as useful if the session window is too wide since the script waits until the session window closes to calculate the extension values.
Cheers,
DTD
Hybrid Adaptive Double Exponential Smoothing🙏🏻 This is HADES (Hybrid Adaptive Double Exponential Smoothing) : fully data-driven & adaptive exponential smoothing method, that gains all the necessary info directly from data in the most natural way and needs no subjective parameters & no optimizations. It gets applied to data itself -> to fit residuals & one-point forecast errors, all at O(1) algo complexity. I designed it for streaming high-frequency univariate time series data, such as medical sensor readings, orderbook data, tick charts, requests generated by a backend, etc.
The HADES method is:
fit & forecast = a + b * (1 / alpha + T - 1)
T = 0 provides in-sample fit for the current datum, and T + n provides forecast for n datapoints.
y = input time series
a = y, if no previous data exists
b = 0, if no previous data exists
otherwise:
a = alpha * y + (1 - alpha) * a
b = alpha * (a - a ) + (1 - alpha) * b
alpha = 1 / sqrt(len * 4)
len = min(ceil(exp(1 / sig)), available data)
sig = sqrt(Absolute net change in y / Sum of absolute changes in y)
For the start datapoint when both numerator and denominator are zeros, we define 0 / 0 = 1
...
The same set of operations gets applied to the data first, then to resulting fit absolute residuals to build prediction interval, and finally to absolute forecasting errors (from one-point ahead forecast) to build forecasting interval:
prediction interval = data fit +- resoduals fit * k
forecasting interval = data opf +- errors fit * k
where k = multiplier regulating intervals width, and opf = one-point forecasts calculated at each time t
...
How-to:
0) Apply to your data where it makes sense, eg. tick data;
1) Use power transform to compensate for multiplicative behavior in case it's there;
2) If you have complete data or only the data you need, like the full history of adjusted close prices: go to the next step; otherwise, guided by your goal & analysis, adjust the 'start index' setting so the calculations will start from this point;
3) Use prediction interval to detect significant deviations from the process core & make decisions according to your strategy;
4) Use one-point forecast for nowcasting;
5) Use forecasting intervals to ~ understand where the next datapoints will emerge, given the data-generating process will stay the same & lack structural breaks.
I advise k = 1 or 1.5 or 4 depending on your goal, but 1 is the most natural one.
...
Why exponential smoothing at all? Why the double one? Why adaptive? Why not Holt's method?
1) It's O(1) algo complexity & recursive nature allows it to be applied in an online fashion to high-frequency streaming data; otherwise, it makes more sense to use other methods;
2) Double exponential smoothing ensures we are taking trends into account; also, in order to model more complex time series patterns such as seasonality, we need detrended data, and this method can be used to do it;
3) The goal of adaptivity is to eliminate the window size question, in cases where it doesn't make sense to use cumulative moving typical value;
4) Holt's method creates a certain interaction between level and trend components, so its results lack symmetry and similarity with other non-recursive methods such as quantile regression or linear regression. Instead, I decided to base my work on the original double exponential smoothing method published by Rob Brown in 1956, here's the original source , it's really hard to find it online. This cool dude is considered the one who've dropped exponential smoothing to open access for the first time🤘🏻
R&D; log & explanations
If you wanna read this, you gotta know, you're taking a great responsability for this long journey, and it gonna be one hell of a trip hehe
Machine learning, apprentissage automatique, машинное обучение, digital signal processing, statistical learning, data mining, deep learning, etc., etc., etc.: all these are just artificial categories created by the local population of this wonderful world, but what really separates entities globally in the Universe is solution complexity / algorithmic complexity.
In order to get the game a lil better, it's gonna be useful to read the HTES script description first. Secondly, let me guide you through the whole R&D; process.
To discover (not to invent) the fundamental universal principle of what exponential smoothing really IS, it required the review of the whole concept, understanding that many things don't add up and don't make much sense in currently available mainstream info, and building it all from the beginning while avoiding these very basic logical & implementation flaws.
Given a complete time t, and yet, always growing time series population that can't be logically separated into subpopulations, the very first question is, 'What amount of data do we need to utilize at time t?'. Two answers: 1 and all. You can't really gain much info from 1 datum, so go for the second answer: we need the whole dataset.
So, given the sequential & incremental nature of time series, the very first and basic thing we can do on the whole dataset is to calculate a cumulative , such as cumulative moving mean or cumulative moving median.
Now we need to extend this logic to exponential smoothing, which doesn't use dataset length info directly, but all cool it can be done via a formula that quantifies the relationship between alpha (smoothing parameter) and length. The popular formulas used in mainstream are:
alpha = 1 / length
alpha = 2 / (length + 1)
The funny part starts when you realize that Cumulative Exponential Moving Averages with these 2 alpha formulas Exactly match Cumulative Moving Average and Cumulative (Linearly) Weighted Moving Average, and the same logic goes on:
alpha = 3 / (length + 1.5) , matches Cumulative Weighted Moving Average with quadratic weights, and
alpha = 4 / (length + 2) , matches Cumulative Weighted Moving Average with cubic weghts, and so on...
It all just cries in your shoulder that we need to discover another, native length->alpha formula that leverages the recursive nature of exponential smoothing, because otherwise, it doesn't make sense to use it at all, since the usual CMA and CMWA can be computed incrementally at O(1) algo complexity just as exponential smoothing.
From now on I will not mention 'cumulative' or 'linearly weighted / weighted' anymore, it's gonna be implied all the time unless stated otherwise.
What we can do is to approach the thing logically and model the response with a little help from synthetic data, a sine wave would suffice. Then we can think of relationships: Based on algo complexity from lower to higher, we have this sequence: exponential smoothing @ O(1) -> parametric statistics (mean) @ O(n) -> non-parametric statistics (50th percentile / median) @ O(n log n). Based on Initial response from slow to fast: mean -> median Based on convergence with the real expected value from slow to fast: mean (infinitely approaches it) -> median (gets it quite fast).
Based on these inputs, we need to discover such a length->alpha formula so the resulting fit will have the slowest initial response out of all 3, and have the slowest convergence with expected value out of all 3. In order to do it, we need to have some non-linear transformer in our formula (like a square root) and a couple of factors to modify the response the way we need. I ended up with this formula to meet all our requirements:
alpha = sqrt(1 / length * 2) / 2
which simplifies to:
alpha = 1 / sqrt(len * 8)
^^ as you can see on the screenshot; where the red line is median, the blue line is the mean, and the purple line is exponential smoothing with the formulas you've just seen, we've met all the requirements.
Now we just have to do the same procedure to discover the length->alpha formula but for double exponential smoothing, which models trends as well, not just level as in single exponential smoothing. For this comparison, we need to use linear regression and quantile regression instead of the mean and median.
Quantile regression requires a non-closed form solution to be solved that you can't really implement in Pine Script, but that's ok, so I made the tests using Python & sklearn:
paste.pics
^^ on this screenshot, you can see the same relationship as on the previous screenshot, but now between the responses of quantile regression & linear regression.
I followed the same logic as before for designing alpha for double exponential smoothing (also considered the initial overshoots, but that's a little detail), and ended up with this formula:
alpha = sqrt(1 / length) / 2
which simplifies to:
alpha = 1 / sqrt(len * 4)
Btw, given the pattern you see in the resulting formulas for single and double exponential smoothing, if you ever want to do triple (not Holt & Winters) exponential smoothing, you'll need len * 2 , and just len * 1 for quadruple exponential smoothing. I hope that based on this sequence, you see the hint that Maybe 4 rounds is enough.
Now since we've dealt with the length->alpha formula, we can deal with the adaptivity part.
Logically, it doesn't make sense to use a slower-than-O(1) method to generate input for an O(1) method, so it must be something universal and minimalistic: something that will help us measure consistency in our data, yet something far away from statistics and close enough to topology.
There's one perfect entity that can help us, this is fractal efficiency. The way I define fractal efficiency can be checked at the very beginning of the post, what matters is that I add a square root to the formula that is not typically added.
As explained in the description of my metric QSFS , one of the reasons for SQRT-transformed values of fractal efficiency applied in moving window mode is because they start to closely resemble normal distribution, yet with support of (0, 1). Data with this interesting property (normally distributed yet with finite support) can be modeled with the beta distribution.
Another reason is, in infinitely expanding window mode, fractal efficiency of every time series that exhibits randomness tends to infinitely approach zero, sqrt-transform kind of partially neutralizes this effect.
Yet another reason is, the square root might better reflect the dimensional inefficiency or degree of fractal complexity, since it could balance the influence of extreme deviations from the net paths.
And finally, fractals exhibit power-law scaling -> measures like length, area, or volume scale in a non-linear way. Adding a square root acknowledges this intrinsic property, while connecting our metric with the nature of fractals.
---
I suspect that, given analogies and connections with other topics in geometry, topology, fractals and most importantly positive test results of the metric, it might be that the sqrt transform is the fundamental part of fractal efficiency that should be applied by default.
Now the last part of the ballet is to convert our fractal efficiency to length value. The part about inverse proportionality is obvious: high fractal efficiency aka high consistency -> lower window size, to utilize only the last data that contain brand new information that seems to be highly reliable since we have consistency in the first place.
The non-obvious part is now we need to neutralize the side effect created by previous sqrt transform: our length values are too low, and exponentiation is the perfect candidate to fix it since translating fractal efficiency into window sizes requires something non-linear to reflect the fractal dynamics. More importantly, using exp() was the last piece that let the metric shine, any other transformations & formulas alike I've tried always had some weird results on certain data.
That exp() in the len formula was the last piece that made it all work both on synthetic and on real data.
^^ a standalone script calculating optimal dynamic window size
Omg, THAT took time to write. Comment and/or text me if you need
...
"Versace Pip-Boy, I'm a young gun coming up with no bankroll" 👻
∞
Dynamic Score Supertrend [QuantAlgo]Dynamic Score Supertrend 📈🚀
The Dynamic Score Supertrend by QuantAlgo introduces a sophisticated trend-following tool that combines the well-known Supertrend indicator with an innovative dynamic trend scoring technique . By tracking market momentum through a scoring system that evaluates price behavior over a customizable window, this indicator adapts to changing market conditions. The result is a clearer, more adaptive tool that helps traders and investors detect and capitalize on trend shifts with greater precision.
💫 Conceptual Foundation and Innovation
At the core of the Dynamic Score Supertrend is the dynamic trend score system , which measures price movements relative to the Supertrend’s upper and lower bands. This scoring technique adds a layer of trend validation, assessing the strength of price trends over time. Unlike traditional Supertrend indicators that rely solely on ATR calculations, this system incorporates a scoring mechanism that provides more insight into trend direction, allowing traders and investors to navigate both trending and choppy markets with greater confidence.
✨ Technical Composition and Calculation
The Dynamic Score Supertrend utilizes the Average True Range (ATR) to calculate the upper and lower Supertrend bands. The dynamic trend scoring technique then compares the price to these bands over a customizable window, generating a trend score that reflects the current market direction.
When the score exceeds the uptrend or downtrend thresholds, it signals a possible shift in market direction. By adjusting the ATR settings and window length, the indicator becomes more adaptable to different market conditions, from steady trends to periods of higher volatility. This customization allows users to refine the Supertrend’s sensitivity and responsiveness based on their trading or investing style.
📈 Features and Practical Applications
Customizable ATR Settings: Adjust the ATR length and multiplier to control the sensitivity of the Supertrend bands. This allows the indicator to smooth out noise or react more quickly to price shifts, depending on market conditions.
Window Length for Dynamic Scoring: Modify the window length to adjust how many data points the scoring system considers, allowing you to tailor the indicator’s responsiveness to short-term or long-term trends.
Uptrend/Downtrend Thresholds: Set thresholds for identifying trend signals. Increase these thresholds for more reliable signals in choppy markets, or lower them for more aggressive entry points in trending markets.
Bar and Background Coloring: Visual cues such as bar coloring and background fills highlight the direction of the current trend, making it easier to spot potential reversals and trend shifts.
Trend Confirmation: The dynamic trend score system provides a clearer confirmation of trend strength, helping you identify strong, sustained movements while filtering out false signals.
⚡️ How to Use
✅ Add the Indicator: Add the Dynamic Score Supertrend to your favourites, then apply it to your chart. Adjust the ATR length, multiplier, and dynamic score settings to suit your trading or investing strategy.
👀 Monitor Trend Shifts: Track price movements relative to the Supertrend bands and use the dynamic trend score to confirm the strength of a trend. Bar and background colors make it easy to visualize key trend shifts.
🔔 Set Alerts: Configure alerts when the dynamic trend score crosses key thresholds, so you can act on significant trend changes without constantly monitoring the charts.
🌟 Summary and Usage Tips
The Dynamic Score Supertrend by QuantAlgo is a robust trend-following tool that combines the power of the Supertrend with an advanced dynamic scoring system. This approach provides more adaptable and reliable trend signals, helping traders and investors make informed decisions in trending markets. The customizable ATR settings and scoring thresholds make it versatile across various market conditions, allowing you to fine-tune the indicator for both short-term momentum and long-term trend following. To maximize its effectiveness, adjust the settings based on current market volatility and use the visual cues to confirm trend shifts. The Dynamic Score Supertrend offers a refined, probabilistic approach to trading and investing, making it a valuable addition to your toolkit.

Rolling Correlation with Bitcoin V1.1 [ADRIDEM]Overview
The Rolling Correlation with Bitcoin script is designed to offer a comprehensive view of the correlation between the selected ticker and Bitcoin. This script helps investors understand the relationship between the performance of the current ticker and Bitcoin over a rolling period, providing insights into their interconnected behavior. Below is a detailed presentation of the script and its unique features.
Unique Features of the New Script
Bitcoin Comparison : Allows users to compare the correlation of the current ticker with Bitcoin, providing an analysis of their relationship.
Customizable Rolling Window : Enables users to set the length for the rolling window, adapting to different market conditions and timeframes. The default value is 252 bars, which approximates one year of trading days, but it can be adjusted as needed.
Smoothing Option : Includes an option to apply a smoothing simple moving average (SMA) to the correlation coefficient, helping to reduce noise and highlight trends. The smoothing length is customizable, with a default value of 4 bars.
Visual Indicators : Plots the smoothed correlation coefficient between the current ticker and Bitcoin, with distinct colors for easy interpretation. Additionally, horizontal lines help identify key levels of correlation.
Dynamic Background Color : Adds dynamic background colors to highlight areas of strong positive and negative correlations, enhancing visual clarity.
Originality and Usefulness
This script uniquely combines the analysis of rolling correlation for a current ticker with Bitcoin, providing a comparative view of their relationship. The inclusion of a customizable rolling window and smoothing option enhances its adaptability and usefulness in various market conditions.
Signal Description
The script includes several features that highlight potential insights into the correlation between the assets:
Rolling Correlation with Bitcoin : Plotted as a red line, this represents the smoothed rolling correlation coefficient between the current ticker and Bitcoin.
Horizontal Lines and Background Color : Lines at -0.5, 0, and 0.5 help to quickly identify regions of strong negative, weak, and strong positive correlations.
These features assist in identifying the strength and direction of the relationship between the current ticker and Bitcoin.
Detailed Description
Input Variables
Length for Rolling Window (`length`) : Defines the range for calculating the rolling correlation coefficient. Default is 252.
Smoothing Length (`smoothing_length`) : The number of periods for the smoothing SMA. Default is 4.
Bitcoin Ticker (`bitcoin_ticker`) : The ticker symbol for Bitcoin. Default is "BINANCE:BTCUSDT".
Functionality
Correlation Calculation : The script calculates the daily returns for both Bitcoin and the current ticker and computes their rolling correlation coefficient.
```pine
bitcoin_close = request.security(bitcoin_ticker, timeframe.period, close)
bitcoin_dailyReturn = ta.change(bitcoin_close) / bitcoin_close
current_dailyReturn = ta.change(close) / close
rolling_correlation = ta.correlation(current_dailyReturn, bitcoin_dailyReturn, length)
```
Smoothing : A simple moving average is applied to the rolling correlation coefficient to smooth the data.
```pine
smoothed_correlation = ta.sma(rolling_correlation, smoothing_length)
```
Plotting : The script plots the smoothed rolling correlation coefficient and includes horizontal lines for key levels.
```pine
plot(smoothed_correlation, title="Rolling Correlation with Bitcoin", color=color.rgb(255, 82, 82, 50), linewidth=2)
h_neg1 = hline(-1, "-1 Line", color=color.gray)
h_neg05 = hline(-0.5, "-0.5 Line", color=color.red)
h0 = hline(0, "Zero Line", color=color.gray)
h_pos05 = hline(0.5, "0.5 Line", color=color.green)
h1 = hline(1, "1 Line", color=color.gray)
fill(h_neg1, h_neg05, color=color.rgb(255, 0, 0, 90), title="Strong Negative Correlation Background")
fill(h_neg05, h0, color=color.rgb(255, 165, 0, 90), title="Weak Negative Correlation Background")
fill(h0, h_pos05, color=color.rgb(255, 255, 0, 90), title="Weak Positive Correlation Background")
fill(h_pos05, h1, color=color.rgb(0, 255, 0, 90), title="Strong Positive Correlation Background")
```
How to Use
Configuring Inputs : Adjust the rolling window length and smoothing length as needed. Ensure the Bitcoin ticker is set to the desired asset for comparison.
Interpreting the Indicator : Use the plotted correlation coefficient and horizontal lines to assess the strength and direction of the relationship between the current ticker and Bitcoin.
Signal Confirmation : Look for periods of strong positive or negative correlation to identify potential co-movements or divergences. The background colors help to highlight these key levels.
This script provides a detailed comparative view of the correlation between the current ticker and Bitcoin, aiding in more informed decision-making by highlighting the strength and direction of their relationship.
Mag7 IndexThis is an indicator index based on cumulative market value of the Magnificent 7 (AAPL, MSFT, NVDA, TSLA, META, AMZN, GOOG). Such an indicator for the famous Mag 7, against which your main security can be benchmarked, was missing from the TradingView user library.
The index bar values are calculated by taking the weighted average of the 7 stocks, relative to their market cap. Explicitly, we are multiplying each bar period's total outstanding stock amount by the OHLC of that period for each stock and dividing that value by the combined sum of outstanding stock for the 7 corporations. OHLC is taken for the extended trading session.
The index dynamically adjusts with respect to the chosen main security and the bars/line visible in the chart window; that is, the first close value is normalized to the main security's first close value. It provides recalculation of the performance in that chart window as you scroll (this isn't apparent in the demo chart above this description).
It can be useful for checking market breadth, or benchmarking price performance of the individual stock components that comprise the Magnificent 7. I prefer comparing the indicator to the Nasdaq Composite Index (IXIC) or S&P500 (SPX), but of course you can make comparisons to any security or commodity.
Settings Input Options:
1) Bar vs. Line - view as OHLC colored bars or line chart. Line chart color based on close above or below the previous period close as green or red line respectively.
2) % vs Regular - the final value for the window period as % return for that window or index value
3) Turn on/off - bottom right tile displaying window-period performance
Inspired by the simpler NQ 7 Index script by @RaenonX but with normalization to main security at start of window and additional settings input options.
Please provide feedback for additional features, e.g., if a regular/extended session option is useful.
Adaptive Fisherized Z-scoreHello Fellas,
It's time for a new adaptive fisherized indicator of me, where I apply adaptive length and more on a classic indicator.
Today, I chose the Z-score, also called standard score, as indicator of interest.
Special Features
Advanced Smoothing: JMA, T3, Hann Window and Super Smoother
Adaptive Length Algorithms: In-Phase Quadrature, Homodyne Discriminator, Median and Hilbert Transform
Inverse Fisher Transform (IFT)
Signals: Enter Long, Enter Short, Exit Long and Exit Short
Bar Coloring: Presents the trade state as bar colors
Band Levels: Changes the band levels
Decision Making
When you create such a mod you need to think about which concepts are the best to conclude. I decided to take Inverse Fisher Transform instead of normalization to make a version which fits to a fixed scale to avoid the usual distortion created by normalization.
Moreover, I chose JMA, T3, Hann Window and Super Smoother, because JMA and T3 are the bleeding-edge MA's at the moment with the best balance of lag and responsiveness. Additionally, I chose Hann Window and Super Smoother because of their extraordinary smoothing capabilities and because Ehlers favours them.
Furthermore, I decided to choose the half length of the dominant cycle instead of the full dominant cycle to make the indicator more responsive which is very important for a signal emitter like Z-score. Signal emitters always need to be faster or have the same speed as the filters they are combined with.
Usage
The Z-score is a low timeframe scalper which works best during choppy/ranging phases. The direction you should trade is determined by the last trend change. E.g. when the last trend change was from bearish market to bullish market and you are now in a choppy/ranging phase confirmed by e.g. Chop Zone or KAMA slope you want to do long trades.
Interpretation
The Z-score indicator is a momentum indicator which shows the number of standard deviations by which the value of a raw score (price/source) is above or below the mean value of what is being observed or measured. Easily explained, it is almost the same as Bollinger Bands with another visual representation form.
Signals
B -> Buy -> Z-score crosses above lower band
S -> Short -> Z-score crosses below upper band
BE -> Buy Exit -> Z-score crosses above 0
SE -> Sell Exit -> Z-score crosses below 0
If you were reading till here, thank you already. Now, follows a bunch of knowledge for people who don't know the concepts I talk about.
T3
The T3 moving average, short for "Tim Tillson's Triple Exponential Moving Average," is a technical indicator used in financial markets and technical analysis to smooth out price data over a specific period. It was developed by Tim Tillson, a software project manager at Hewlett-Packard, with expertise in Mathematics and Computer Science.
The T3 moving average is an enhancement of the traditional Exponential Moving Average (EMA) and aims to overcome some of its limitations. The primary goal of the T3 moving average is to provide a smoother representation of price trends while minimizing lag compared to other moving averages like Simple Moving Average (SMA), Weighted Moving Average (WMA), or EMA.
To compute the T3 moving average, it involves a triple smoothing process using exponential moving averages. Here's how it works:
Calculate the first exponential moving average (EMA1) of the price data over a specific period 'n.'
Calculate the second exponential moving average (EMA2) of EMA1 using the same period 'n.'
Calculate the third exponential moving average (EMA3) of EMA2 using the same period 'n.'
The formula for the T3 moving average is as follows:
T3 = 3 * (EMA1) - 3 * (EMA2) + (EMA3)
By applying this triple smoothing process, the T3 moving average is intended to offer reduced noise and improved responsiveness to price trends. It achieves this by incorporating multiple time frames of the exponential moving averages, resulting in a more accurate representation of the underlying price action.
JMA
The Jurik Moving Average (JMA) is a technical indicator used in trading to predict price direction. Developed by Mark Jurik, it’s a type of weighted moving average that gives more weight to recent market data rather than past historical data.
JMA is known for its superior noise elimination. It’s a causal, nonlinear, and adaptive filter, meaning it responds to changes in price action without introducing unnecessary lag. This makes JMA a world-class moving average that tracks and smooths price charts or any market-related time series with surprising agility.
In comparison to other moving averages, such as the Exponential Moving Average (EMA), JMA is known to track fast price movement more accurately. This allows traders to apply their strategies to a more accurate picture of price action.
Inverse Fisher Transform
The Inverse Fisher Transform is a transform used in DSP to alter the Probability Distribution Function (PDF) of a signal or in our case of indicators.
The result of using the Inverse Fisher Transform is that the output has a very high probability of being either +1 or –1. This bipolar probability distribution makes the Inverse Fisher Transform ideal for generating an indicator that provides clear buy and sell signals.
Hann Window
The Hann function (aka Hann Window) is named after the Austrian meteorologist Julius von Hann. It is a window function used to perform Hann smoothing.
Super Smoother
The Super Smoother uses a special mathematical process for the smoothing of data points.
The Super Smoother is a technical analysis indicator designed to be smoother and with less lag than a traditional moving average.
Adaptive Length
Length based on the dominant cycle length measured by a "dominant cycle measurement" algorithm.
Happy Trading!
Best regards,
simwai
---
Credits to
@cheatcountry
@everget
@loxx
@DasanC
@blackcat1402

AI Channels (Clustering) [LuxAlgo]The AI Channels indicator is constructed based on rolling K-means clustering, a common machine learning method used for clustering analysis. These channels allow users to determine the direction of the underlying trends in the price.
We also included an option to display the indicator as a trailing stop from within the settings.
🔶 USAGE
Each channel extremity allows users to determine the current trend direction. Price breaking over the upper extremity suggesting an uptrend, and price breaking below the lower extremity suggesting a downtrend. Using a higher Window Size value will return longer-term indications.
The "Clusters" setting allows users to control how easy it is for the price to break an extremity, with higher values returning extremities further away from the price.
The "Denoise Channels" is enabled by default and allows to see less noisy extremities that are more coherent with the detected trend.
Users who wish to have more focus on a detected trend can display the indicator as a trailing stop.
🔹 Centroid Dispersion Areas
Each extremity is made of one area. The width of each area indicates how spread values within a cluster are around their centroids. A wider area would suggest that prices within a cluster are more spread out around their centroid, as such one could say that it is indicative of the volatility of a cluster.
Wider areas around a specific extremity can indicate a larger and more spread-out amount of prices within the associated cluster. In practice price entering an area has a higher chance to break an associated extremity.
🔶 DETAILS
The indicator performs K-means clustering over the most recent Window Size prices, finding a number of user-specified clusters. See here to find more information on cluster detection.
The channel extremities are returned as the centroid of the lowest, average, and highest price clusters.
K-means clustering can be computationally expensive and as such we allow users to determine the maximum number of iterations used to find the centroids as well as the number of most historical bars to perform the indicator calculation. Do note that increasing the calculation window of the indicator as well as the number of clusters will return slower results.
🔶 SETTINGS
Window Size: Amount of most recent prices to use for the calculation of the indicator.
Clusters": Amount of clusters detected for the calculation of the indicator.
Denoise Channels: When enabled, return less noisy channels extremities, disabling this setting will return the exact centroids at each time but will produce less regular extremities.
As Trailing Stop: Display the indicator as a trailing stop.
🔹 Optimization
This group of settings affects the runtime performance of the script.
Maximum Iteration Steps: Maximum number of iterations allowed for finding centroids. Excessively low values can return a better script load time but poor clustering.
Historical Bars Calculation: Calculation window of the script (in bars).
Adaptive Average Vortex Index [lastguru]As a longtime fan of ADX, looking at Vortex Indicator I often wondered, where is the third line. I have rarely seen that anybody is calculating it. So, here it is: Average Vortex Index - an ADX calculated from Vortex Indicator. I interpret it similarly to the ADX indicator: higher values show stronger trend. If you discover other interpretation or have suggestions, comments are welcome.
Both VI+ and VI- lines are also drawn. As I use adaptive length calculation in my other scripts (based on the libraries I've developed and published), I have also included the possibility to have an adaptive length here, so if you hate the idea of calculating ADX from VI, you can disable that line and just look at the adaptive Vortex Indicator.
Note that as with all my oscillators, all the lines here are renormalized to -1..1 range unlike the original Vortex Indicator computation. To do that for VI+ and VI- lines, I subtract 1 from their values. It does not change the shape or the amplitude of the lines.
Adaptation algorithms are roughly subdivided in two categories: classic Length Adaptations and Cycle Estimators (they are also implemented in separate libraries), all are selected in Adaptation dropdown. Length Adaptation used in the Adaptive Moving Averages and the Adaptive Oscillators try to follow price movements and accelerate/decelerate accordingly (usually quite rapidly with a huge range). Cycle Estimators, on the other hand, try to measure the cycle period of the current market, which does not reflect price movement or the rate of change (the rate of change may also differ depending on the cycle phase, but the cycle period itself usually changes slowly).
VIDYA - based on VIDYA algorithm. The period oscillates from the Lower Bound up (slow)
VIDYA-RS - based on Vitali Apirine's modification of VIDYA algorithm (he calls it Relative Strength Moving Average). The period oscillates from the Upper Bound down (fast)
Kaufman Efficiency Scaling - based on Efficiency Ratio calculation originally used in KAMA
Fractal Adaptation - based on FRAMA by John F. Ehlers
MESA MAMA Cycle - based on MESA Adaptive Moving Average by John F. Ehlers
Pearson Autocorrelation* - based on Pearson Autocorrelation Periodogram by John F. Ehlers
DFT Cycle* - based on Discrete Fourier Transform Spectrum estimator by John F. Ehlers
Phase Accumulation* - based on Dominant Cycle from Phase Accumulation by John F. Ehlers
Length Adaptation usually take two parameters: Bound From (lower bound) and To (upper bound). These are the limits for Adaptation values. Note that the Cycle Estimators marked with asterisks(*) are very computationally intensive, so the bounds should not be set much higher than 50, otherwise you may receive a timeout error (also, it does not seem to be a useful thing to do, but you may correct me if I'm wrong).
The Cycle Estimators marked with asterisks(*) also have 3 checkboxes: HP (Highpass Filter), SS (Super Smoother) and HW (Hann Window). These enable or disable their internal prefilters, which are recommended by their author - John F. Ehlers . I do not know, which combination works best, so you can experiment.
If no Adaptation is selected ( None option), you can set Length directly. If an Adaptation is selected, then Cycle multiplier can be set.
The oscillator also has the option to configure the internal smoothing function with Window setting. By default, RMA is used (like in ADX calculation). Fast Default option is using half the length for smoothing. Triangle , Hamming and Hann Window algorithms are some better smoothers suggested by John F. Ehlers.
After the oscillator a Moving Average can be applied. The following Moving Averages are included: SMA , RMA, EMA , HMA , VWMA , 2-pole Super Smoother, 3-pole Super Smoother, Filt11, Triangle Window, Hamming Window, Hann Window, Lowpass, DSSS.
Postfilter options are applied last:
Stochastic - Stochastic
Super Smooth Stochastic - Super Smooth Stochastic (part of MESA Stochastic ) by John F. Ehlers
Inverse Fisher Transform - Inverse Fisher Transform
Noise Elimination Technology - a simplified Kendall correlation algorithm "Noise Elimination Technology" by John F. Ehlers
Momentum - momentum (derivative)
Except for Inverse Fisher Transform , all Postfilter algorithms can have Length parameter. If it is not specified (set to 0), then the calculated Slow MA Length is used. If Filter/MA Length is less than 2 or Postfilter Length is less than 1, they are calculated as a multiplier of the calculated oscillator length.
More information on the algorithms is given in the code for the libraries used. I am also very grateful to other TradingView community members (they are also mentioned in the library code) without whom this script would not have been possible.
