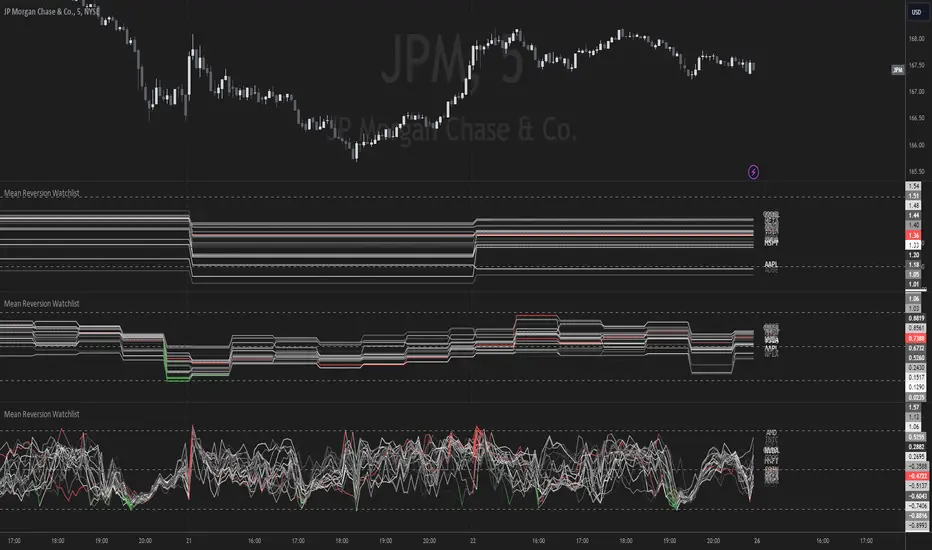
Mean Reversion Watchlist [Z score]Hi Traders !
What is the Z score:
The Z score measures a values variability factor from the mean, this value is denoted by z and is interpreted as the number of standard deviations from the mean.
The Z score is often applied to the normal distribution to “standardize” the values; this makes comparison of normally distributed random variables with different units possible.
This popular reversal based indicator makes an assumption that the sample distribution (in this case the sample of price values) is normal, this allows for the interpretation that values with an extremely high or low percentile or “Z” value will likely be reversal zones.
This is because in the population data (the true distribution) which is known, anomaly values are very rare, therefore if price were to take a z score factor of 3 this would mean that price lies 3 standard deviations from the mean in the positive direction and is in the ≈99% percentile of all values. We would take this as a sign of a negative reversal as it is very unlikely to observe a consecutive equal to or more extreme than this percentile or Z value.
The z score normalization equation is given by
In Pine Script the Z score can be computed very easily using the below code.
// Z score custom function
Zscore(source, lookback) =>
sma = ta.sma(source, lookback)
stdev = ta.stdev(source, lookback, true)
zscore = (source - sma) / stdev
zscore
The Indicator:
This indicator plots the Z score for up to 20 different assets ( Note the maximum is 40 however the utility of 40 plots in one indicator is not much, there is a diminishing marginal return of the number of plots ).
Z score threshold levels can also be specified, the interpretation is the same as stated above.
The timeframe can also be fixed, by toggling the “Time frame lock” user input under the “TIME FRAME LOCK” user input group ( Note this indicator does not repain t).
Statisticalprobability
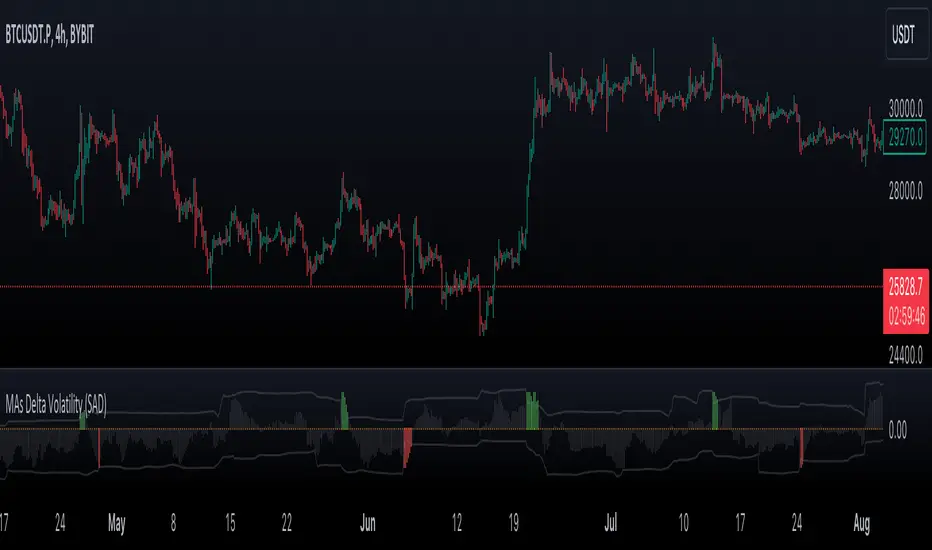
VWMA/SMA Delta Volatility (Statistical Anomaly Detector)The "VWMA/SMA Delta Volatility (Statistical Anomaly Detector)" indicator is a tool designed to detect and visualize volatility in a financial market's price data. The indicator calculates the difference (delta) between two moving averages (VWMA/SMA) and uses statistical analysis to identify anomalies or extreme price movements. Here's a breakdown of its components:
Hypothesis:
The hypothesis behind this indicator is that extreme price movements or anomalies in the market can be detected by analyzing the difference between two moving averages and comparing it to a statistically derived normal distribution. When the MA delta (the difference between two MAs: VWMA/SMA) exceeds a certain threshold based on standard deviation and the Z-score coefficient, it may indicate increased market volatility or potential trading opportunities.
Calculation of MA Delta:
The indicator calculates the MA delta by subtracting a simple moving average (SMA) from a volume-weighted moving average (VWMA) of a selected price source. This calculation represents the difference in the market's short-term and long-term trends.
Statistical Analysis:
To detect anomalies, the indicator performs statistical analysis on the MA delta. It calculates a moving average (MA) of the MA delta and its standard deviation over a specified sample size. This MA acts as a baseline, and the standard deviation is used to measure how much the MA delta deviates from the mean.
Delta Normalization:
The MA delta, lower filter, and upper filter are normalized using a function that scales them to a specific range, typically from -100 to 100. Normalization helps in comparing these values on a consistent scale and enhances their visual representation.
Visual Representation:
The indicator visualizes the results through histograms and channels:
The histogram bars represent the normalized MA delta. Red bars indicate negative and below-lower-filter values, green bars indicate positive and above-upper-filter values, and silver bars indicate values within the normal range.
It also displays a Z-score channel, which represents the upper and lower filters after normalization. This channel helps traders identify price levels that are statistically significant and potentially indicative of market volatility.
In summary, the "MA Delta Volatility (Statistical Anomaly Detector)" indicator aims to help traders identify abnormal price movements in the market by analyzing the difference between two moving averages and applying statistical measures. It can be a valuable tool for traders looking to spot potential opportunities during periods of increased volatility or to identify potential market anomalies.
Normal Distribution CurveThis Normal Distribution Curve is designed to overlay a simple normal distribution curve on top of any TradingView indicator. This curve represents a probability distribution for a given dataset and can be used to gain insights into the likelihood of various data levels occurring within a specified range, providing traders and investors with a clear visualization of the distribution of values within a specific dataset. With the only inputs being the variable source and plot colour, I think this is by far the simplest and most intuitive iteration of any statistical analysis based indicator I've seen here!
Traders can quickly assess how data clusters around the mean in a bell curve and easily see the percentile frequency of the data; or perhaps with both and upper and lower peaks identify likely periods of upcoming volatility or mean reversion. Facilitating the identification of outliers was my main purpose when creating this tool, I believed fixed values for upper/lower bounds within most indicators are too static and do not dynamically fit the vastly different movements of all assets and timeframes - and being able to easily understand the spread of information simplifies the process of identifying key regions to take action.
The curve's tails, representing the extreme percentiles, can help identify outliers and potential areas of price reversal or trend acceleration. For example using the RSI which typically has static levels of 70 and 30, which will be breached considerably more on a less liquid or more volatile asset and therefore reduce the actionable effectiveness of the indicator, likewise for an asset with little to no directional volatility failing to ever reach this overbought/oversold areas. It makes considerably more sense to look for the top/bottom 5% or 10% levels of outlying data which are automatically calculated with this indicator, and may be a noticeable distance from the 70 and 30 values, as regions to be observing for your investing.
This normal distribution curve employs percentile linear interpolation to calculate the distribution. This interpolation technique considers the nearest data points and calculates the price values between them. This process ensures a smooth curve that accurately represents the probability distribution, even for percentiles not directly present in the original dataset; and applicable to any asset regardless of timeframe. The lookback period is set to a value of 5000 which should ensure ample data is taken into calculation and consideration without surpassing any TradingView constraints and limitations, for datasets smaller than this the indicator will adjust the length to just include all data. The labels providing the percentile and average levels can also be removed in the style tab if preferred.
Additionally, as an unplanned benefit is its applicability to the underlying price data as well as any derived indicators. Turning it into something comparable to a volume profile indicator but based on the time an assets price was within a specific range as opposed to the volume. This can therefore be used as a tool for identifying potential support and resistance zones, as well as areas that mark market inefficiencies as price rapidly accelerated through. This may then give a cleaner outlook as it eliminates the potential drawbacks of volume based profiles that maybe don't collate all exchange data or are misrepresented due to large unforeseen increases/decreases underlying capital inflows/outflows.
Thanks to @ALifeToMake, @Bjorgum, vgladkov on stackoverflow (and possibly some chatGPT!) for all the assistance in bringing this indicator to life. I really hope every user can find some use from this and help bring a unique and data driven perspective to their decision making. And make sure to please share any original implementaions of this tool too! If you've managed to apply this to the average price change once you've entered your position to better manage your trade management, or maybe overlaying on an implied volatility indicator to identify potential options arbitrage opportunities; let me know! And of course if anyone has any issues, questions, queries or requests please feel free to reach out! Thanks and enjoy.

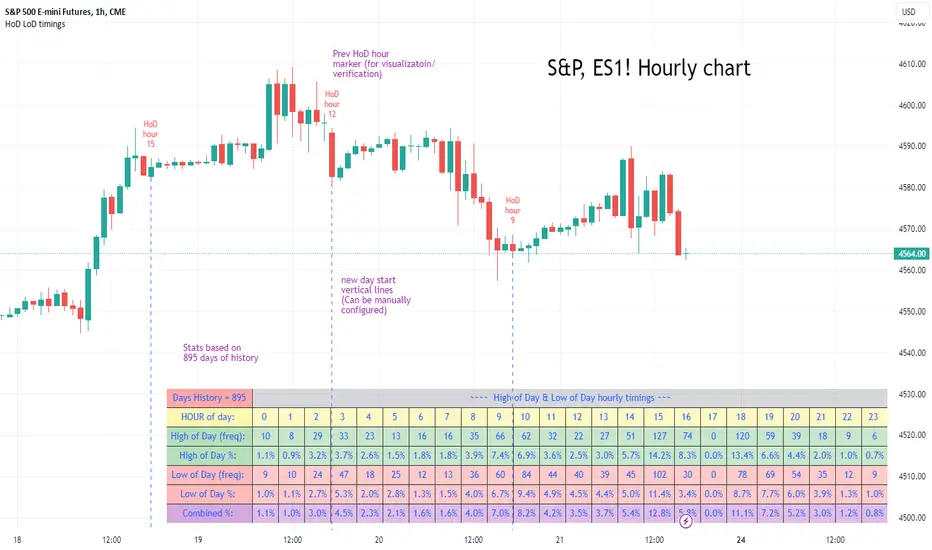
High of Day Low of Day hourly timings: Statistics. Time of day %High of Day (HoD) & Low of Day (LoD) hourly timings: Statistics. Time of day % likelihood for high and low.
//Purpose:
To collect stats on the hourly occurrences of HoD and LoD in an asset, to see which times of day price is more likely to form its highest and lowest prices.
//How it works:
Each day, HoD and LoD are calculated and placed in hourly 'buckets' from 0-23. Frequencies and Percentages are then calculated and printed/tabulated based on the full asset history available.
//User Inputs:
-Timezone (default is New York); important to make sure this matches your chart's timezone
-Day start time: (default is Tradingview's standard). Toggle Custom input box to input your own custom day start time.
-Show/hide day-start vertical lines; show/hide previous day's 'HoD hour' label (default toggled on). To be used as visual aid for setting up & verifying timezone settings are correct and table is populating correctly).
-Use historical start date (default toggled off): Use this along with bar-replay to backtest specific periods in price (i.e. consolidated vs trending, dull vs volatile).
-Standard formatting options (text color/size, table position, etc).
-Option to show ONLY on hourly chart (default toggled off): since this indicator is of most use by far on the hourly chart (most history, max precision).
// Notes & Tips:
-Make sure Timezone settings match (input setting & chart timezone).
-Play around with custom input day start time. Choose a 'dead' time (overnight) so as to ensure stats are their most meaningful (if you set a day start time when price is likely to be volatile or trending, you may get a biased / misleadingly high readout for the start-of-day/ end-of-day hour, due to price's tendency for continuation through that time.
-If you find a time of day with significantly higher % and it falls either side of your day start time. Try adjusting day start time to 'isolate' this reading and thereby filter out potential 'continuation bias' from the stats.
-Custom input start hour may not match to your chart at first, but this is not a concern: simply increment/decrement your input until you get the desired start time line on the chart; assuming your timezone settings for chart and indicator are matching, all will then work properly as designed.
-Use the the lines and labels along with bar-replay to verify HoD/LoD hours are printing correctly and table is populating correctly.
-Hour 'buckets' represent the start of said hour. i.e. hour 14 would be populated if HoD or LoD formed between 14:00 and 15:00.
-Combined % is simply the average of HoD % and LoD %. So it is the % likelihood of 'extreme of day' occurring in that hour.
-Best results from using this on Hourly charts (sub-hourly => less history; above hourly => less precision).
-Note that lower tier Tradingview subscriptions will get less data history. Premium acounts get 20k bars history => circa 900 days history on hourly chart for ES1!
-Works nicely on Btc/Usd too: any 24hr assets this will give meaningful data (whereas some commodities, such as Lean Hogs which only trade 5hrs in a day, will yield less meaningful data).
Example usage on S&P (ES1! 1hr chart): manual day start time of 11pm; New York timezone; Visual aid lines and labels toggled on. HoD LoD hour timings with 920 days history:
Price Legs: Average Heights; 'Smart ATR'Price Legs: Average Heights; 'Smart ATR'. Consol Range Gauge
~~ Indicator to show small and large price legs (based on short and long input pivot lengths), and calculating the average heights of these price legs; counting legs from user-input start time ~~
//Premise: Wanted to use this as something like a 'Smart ATR': where the average/typical range of a distinct & dynamic price leg could be calculated based on a user-input time interval (as opposed to standard ATR, which is simply the average range over a consistent repeating period, with no regard to market structure). My instinct is that this would be most useful for consolidated periods & range trading: giving the trader an idea of what the typical size of a price leg might be in the current market state (hence in the title, Consol Range gauge)
//Features & User inputs:
-Start time: confirm input when loading indicator by clicking on the chart. Then drag the vertical line to change start time easily.
-Large Legs (toggle on/off) and user-input pivot lookback/lookforward length (larger => larger legs)
-Small Legs (toggle on/off) and user-input pivot lookback/lookforward length (smaller => smaller legs)
-Display Stats table: toggle on/off: simple view- shows the averages of large (up & down), small (up & down), and combined (for each).
-Extended stats table: toggle on/off option to show the averages of the last 3 legs of each category (up/down/large/small/combined)
-Toggle on/off Time & Price chart text labels of price legs (time in mins/hours/days; price in $ or pips; auto assigned based on asset)
-Table position: user choice.
//Notes & tips:
-Using custom start time along with replay mode, you can select any arbitrary chunk of price for the purpose of backtesting.
-Play around with the pivot lookback lengths to find price legs most suitable to the current market regime (consolidating/trending; high volatility/ low volatility)
-Single bar price legs will never be counted: they must be at least 2 bars from H>>L or L>>H.
//Credits: Thanks to @crypto_juju for the idea of applying statistics to this simple price leg indicator.
Simple View: showing only the full averages (counting from Start time):
View showing ONLY the large legs, with Time & Price labels toggled ON:

BenfordsLawLibrary "BenfordsLaw"
Methods to deal with Benford's law which states that a distribution of first and higher order digits
of numerical strings has a characteristic pattern.
"Benford's law is an observation about the leading digits of the numbers found in real-world data sets.
Intuitively, one might expect that the leading digits of these numbers would be uniformly distributed so that
each of the digits from 1 to 9 is equally likely to appear. In fact, it is often the case that 1 occurs more
frequently than 2, 2 more frequently than 3, and so on. This observation is a simplified version of Benford's law.
More precisely, the law gives a prediction of the frequency of leading digits using base-10 logarithms that
predicts specific frequencies which decrease as the digits increase from 1 to 9." ~(2)
---
reference:
- 1: en.wikipedia.org
- 2: brilliant.org
- 4: github.com
cumsum_difference(a, b)
Calculate the cumulative sum difference of two arrays of same size.
Parameters:
a (float ) : `array` List of values.
b (float ) : `array` List of values.
Returns: List with CumSum Difference between arrays.
fractional_int(number)
Transform a floating number including its fractional part to integer form ex:. `1.2345 -> 12345`.
Parameters:
number (float) : `float` The number to transform.
Returns: Transformed number.
split_to_digits(number, reverse)
Transforms a integer number into a list of its digits.
Parameters:
number (int) : `int` Number to transform.
reverse (bool) : `bool` `default=true`, Reverse the order of the digits, if true, last will be first.
Returns: Transformed number digits list.
digit_in(number, digit)
Digit at index.
Parameters:
number (int) : `int` Number to parse.
digit (int) : `int` `default=0`, Index of digit.
Returns: Digit found at the index.
digits_from(data, dindex)
Process a list of `int` values and get the list of digits.
Parameters:
data (int ) : `array` List of numbers.
dindex (int) : `int` `default=0`, Index of digit.
Returns: List of digits at the index.
digit_counters(digits)
Score digits.
Parameters:
digits (int ) : `array` List of digits.
Returns: List of counters per digit (1-9).
digit_distribution(counters)
Calculates the frequency distribution based on counters provided.
Parameters:
counters (int ) : `array` List of counters, must have size(9).
Returns: Distribution of the frequency of the digits.
digit_p(digit)
Expected probability for digit according to Benford.
Parameters:
digit (int) : `int` Digit number reference in range `1 -> 9`.
Returns: Probability of digit according to Benford's law.
benfords_distribution()
Calculated Expected distribution per digit according to Benford's Law.
Returns: List with the expected distribution.
benfords_distribution_aprox()
Aproximate Expected distribution per digit according to Benford's Law.
Returns: List with the expected distribution.
test_benfords(digits, calculate_benfords)
Tests Benford's Law on provided list of digits.
Parameters:
digits (int ) : `array` List of digits.
calculate_benfords (bool)
Returns: Tuple with:
- Counters: Score of each digit.
- Sample distribution: Frequency for each digit.
- Expected distribution: Expected frequency according to Benford's.
- Cumulative Sum of difference:
to_table(digits, _text_color, _border_color, _frame_color)
Parameters:
digits (int )
_text_color (color)
_border_color (color)
_frame_color (color)

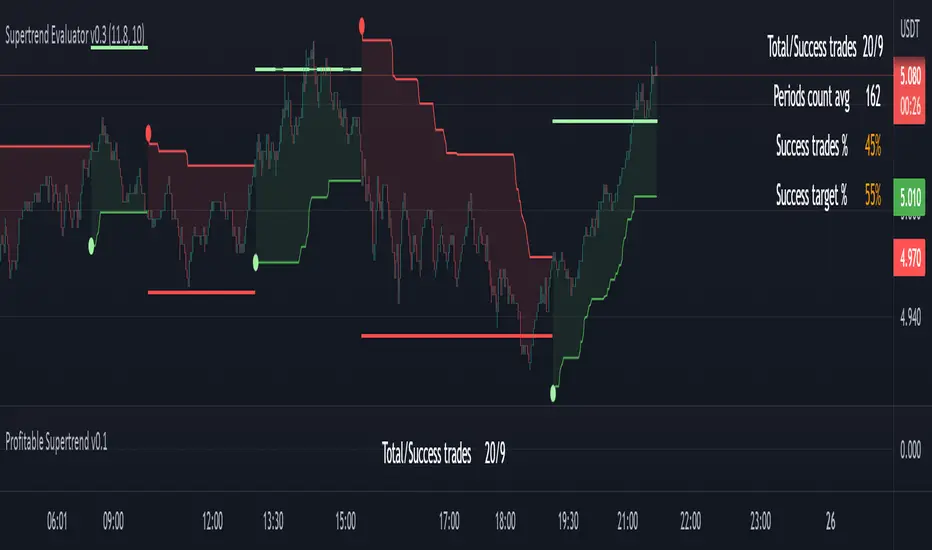
Profitable Supertrend v0.1 - AlphaThis a script to try detect the best combination of supertrend parameters in a space of time. Sadly the script is slow. Evaluate all possibilities params is hard for a pinescript and my knowledge too. In some cases, when you want evaluate many time could be the script fails for timeout. Perhaps with time I could enhance. For this problem of speed the calculate of combinatios it's not complete: In factor use a increment of 0.2 in each param (0.1, 0.3, 0.5 ...) in period the increment for each value is 3. The range for factor it's from 3.0 to 12.0. The range of period it's from 10 to 43
My knowledge don't let me go more far. Perhaps with time I can enhance the script.
Reinforced RSI - The Quant Science This strategy was designed and written with the goal of showing and motivating the community how to integrate our 'Probabilities' module with their own script.
We have recreated one of the simplest strategies used by many traders. The strategy only trades long and uses the overbought and oversold levels on the RSI indicator.
We added stop losses and take profits to offer more dynamism to the strategy. Then the 'Probabilities' module was integrated to create a probabilistic reinforcement on each trade.
Specifically, each trade is executed, only if the past probabilities of making a profitable trade is greater than or equal to 51%. This greatly increased the performance of the strategy by avoiding possible bad trades.
The backtesting was calculated on the NASDAQ:TSLA , on 15 minutes timeframe.
The strategy works on Tesla using the following parameters:
1. Lenght: 13
2. Oversold: 40
3. Overbought: 70
4. Lookback: 50
5. Take profit: 3%
6. Stop loss: 3%
Time period: January 2021 to date.
Our Probabilities Module, used in the strategy example:

Probabilities Module - The Quant Science This module can be integrate in your code strategy or indicator and will help you to calculate the percentage probability on specific event inside your strategy. The main goal is improve and simplify the workflow if you are trying to build a quantitative strategy or indicator based on statistics or reinforcement model.
Logic
The script made a simulation inside your code based on a single event. For single event mean a trading logic composed by three different objects: entry, take profit, stop loss.
The script scrape in the past through a look back function and return the positive percentage probability about the positive event inside the data sample. In this way you are able to understand and calculate how many time (in percentage term) the conditions inside the single event are positive, helping to create your statistical edge.
You can adjust the look back period in you user interface.
How can set up the module for your use case
At the top of the script you can find:
1. entry_condition : replace the default condition with your specific entry condition.
2. TPcondition_exit : replace the default condition with your specific take profit condition.
3. SLcondition_exit : replace the default condition with your specific stop loss condition.

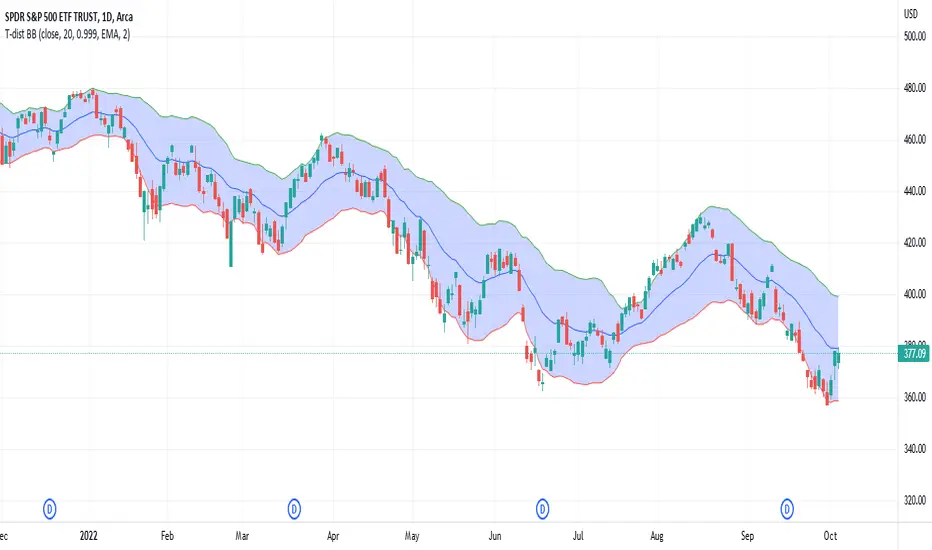
Student's T-Distribution Bollinger BandsThis study shows the prediction interval as Bollinger Bands using Student's T-distribution. This means that the bands will be wider when the data features higher variation, as well as when the sample size (in the form of length) is smaller. The bands will also be wider when the confidence level is lower. The opposite is also true. Assuming we set a confidence level of 0.99 and a source set to the close price, we could reasonably expect that 99% of the time the close price would fall between the upper and lower bounds. Because this is a general statistical method which requires a lot of math, the script has a tendency to be relatively slow, but should be eligible to be used in a wide variety of situations.
Saty ATR LevelsThis indicator uses the previous period close and +/- 1 ATR to display significant day, multiday, swing, and position trading levels including:
- Trigger clouds for possibly going long/short @ 23.6 fib
- Mid-range level at 61.8 fib
- Full range level at +/- 1 ATR (from previous close)
- Extension level at 161.8 fib
Additionally, a convenient info table is provided that shows trend, range utilization, and numerical long/short values.
This indicator is most beneficial when you combine it with price, volume, and trend analysis. For educational content please check out the indicator website at atrlevels.com.
I am constantly improving this indicator, please use this one if you want to continue to get new features, bug fixes, and support.

Bar StatisticsThis script calculates and displays some bar statistics.
For the bar length statistics, it takes every length of upper or lower movements and calculates their average (with SD), median, and max. That way, you can see whether there is a bias in the market or not.
Eg.: If for 10 bars, the market moved 2 up, then 1 down, then 3 up, then 2 down, and 2 up, the average up bars length would be at 2.33, while the average for the down length would be at 1.5, showing that upper movements last longer than down movements.
For the range statistics, it takes the true range of each bar and calculates where the close of the bar is in relation to the true low of it. So if the closing of the bar is at 10.0, the low is at 9.0, and the high is at 10.2, the candle closed in the upper third of the bar. This process is calculated for every bar and for both closing prices and open prices. It is very useful to locate biasses, and they can you a better view of the market, since for most of the time a bar will open on an extreme and close on another extreme.
Eg.: Here on the DJI, we can see that for most of the time, a month opens at the lower third (near the low) and closes at the upper third (near the high). We can also see that it is very difficult for a month to open or close on the middle of the candle, showing how important the first and the last day are for determining the trend of the rest of the month.

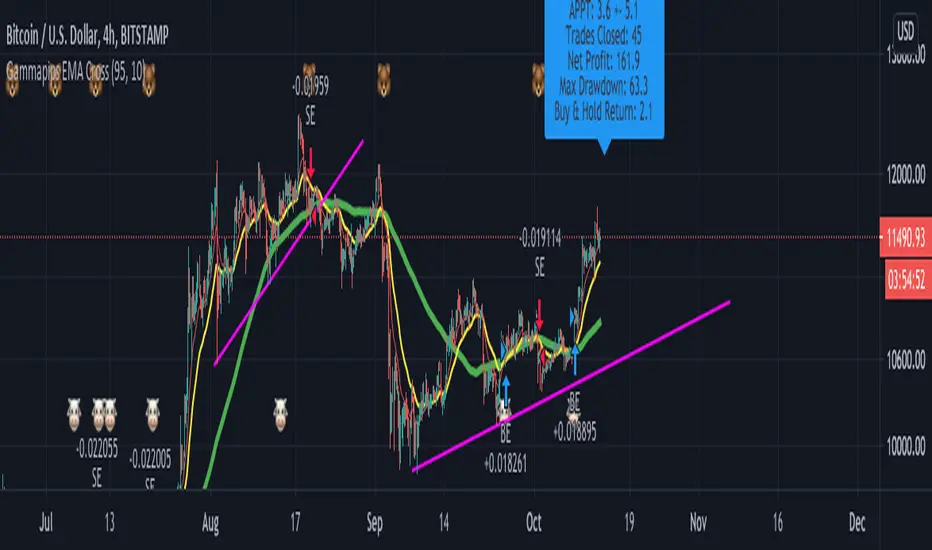
Inferential Statistics And Quick Metrics For Strategy Analysis.Part of this script is used to calculate inferential statistics and metrics not available through the built in variables in the strategy tester.
A label will be created on the last bar displaying important strategy results, so you can test and analyze strategies quicker.
The built in strategy itself is just an example. You can copy and paste the metrics into any existing version 4 strategy and instantly use it**
**Just be sure all the variable names are unique in your target script.
I am looking for critique and would appreciate input on the statistical functions. I am aware that some of these functions are based on the assumption that the data is normally distributed. It's not meant to be perfect, but it is meant to be helpful. So if you think I can add or improve something to make it more helpful, let me know.