OPEN-SOURCE SCRIPT
更新済 KNN ATR Dual Range Predictions [SS]
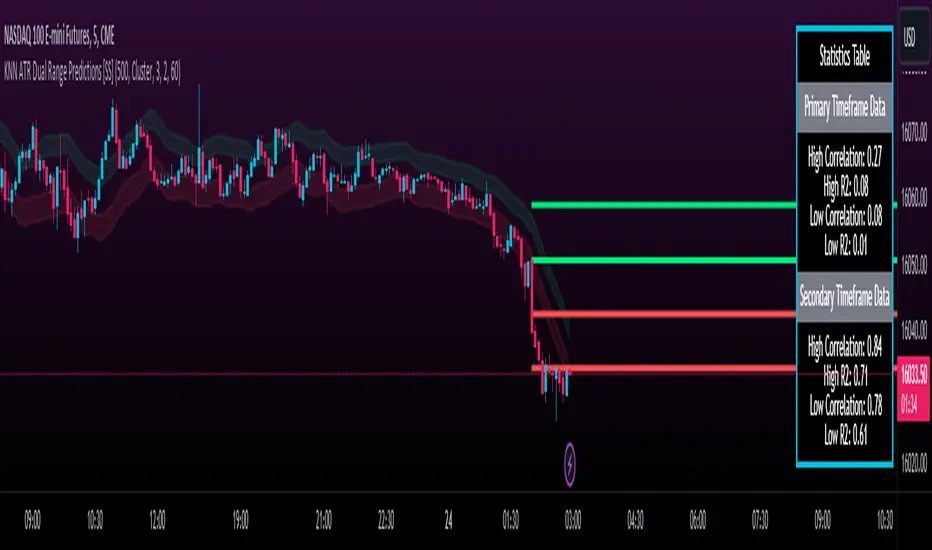
Excited to release this indicator!
I wanted to do a machine learning, ATR based indicator for a while, but I first had to learn about machine learning algos haha.
Now that I have created a KNN based regression methodology (shared in a previous indicator), I can finally do it!
So this is a Nearest Known Neighbor or KNN regression based indicator that uses ATR (average ranges) to predict future ranges.
It operates by calculating the move from High to Open and Open to Low and performing KNN regression to look for other, similar instances of similar movements and what followed those movements.
It provides for 2 methods of KNN regression, the traditional Cluster method (where it identifies a number of clusters within a tolerance range and averages them out), or the method of last instance (where it finds the most recent identical instance and plots the result from that).
You can toggle the parameters as you wish, including the:
a) Type of Regression
b) Number of Clusters
c) Tolerance for Clusters
Others functions:
The indicator provides for the ability to view 2 different timeframe targets. The default calculation is the current timeframe you are on. So if you are on the 1 minute, 5 minute or 1 hour, it will automatically default the primary range to this timeframe. This cannot be changed.
But it permits for a second prediction to be calculated for a timeframe you can specify. The example in the chart above is the 1 hour overlaid on the 5 minute chart.
You can see how the model is performing in the statistics table. The statistics table can be removed as well if you don't want it overlaid on your chart.
You can also toggle off and on the various ranges. IF you only want to visualize 1 hour levels on a 5 minute chart, you can toggle off the bands and just view the higher tf data. Inversely, if you only want the current timeframe data and not the higher tf data, you can toggle the higher tf data off as well.
General Use Tips:
Some general use tips include:
🎯The default settings are appropriate for most common tickers. Because this is performing an autoregression on itself, the parameters tend to be more tight vs. performing dual correlation between two separate tickers which are sizably different in scale (which would require a higher tolerance).

Here is an example of YM1!, which is a sizably larger ticker, however it is performing well with the current settings.
🎯 If you get not great results from your ranges or an error in the correlation table, something like this:

It means the parameters are too tight for what you want to do and it is having trouble identifying other, similar cases (in this case, the lookback length was significantly shortened). The first step is to:
a) Expand your lookback range (up to 500 is usually sufficient). This should resolve most issues in most cases. If not:
b) If you are using the Cluster method, try broadening your cluster tolerance by 0.5 increments.
Between those two implementations, you should get a functional model. And it actually honestly hasn't happened to me in general use, I had to force that example by significantly shortening the lookback period.
Concluding Remarks
And that's pretty much the indicator.
I hope you enjoy it! I was really excited to be finally able to do it, like I said I attempted to do this for a while but needed to research the whole KNN process and how its performed.
Enjoy and leave your comments and questions below!
I wanted to do a machine learning, ATR based indicator for a while, but I first had to learn about machine learning algos haha.
Now that I have created a KNN based regression methodology (shared in a previous indicator), I can finally do it!
So this is a Nearest Known Neighbor or KNN regression based indicator that uses ATR (average ranges) to predict future ranges.
It operates by calculating the move from High to Open and Open to Low and performing KNN regression to look for other, similar instances of similar movements and what followed those movements.
It provides for 2 methods of KNN regression, the traditional Cluster method (where it identifies a number of clusters within a tolerance range and averages them out), or the method of last instance (where it finds the most recent identical instance and plots the result from that).
You can toggle the parameters as you wish, including the:
a) Type of Regression
b) Number of Clusters
c) Tolerance for Clusters
Others functions:
The indicator provides for the ability to view 2 different timeframe targets. The default calculation is the current timeframe you are on. So if you are on the 1 minute, 5 minute or 1 hour, it will automatically default the primary range to this timeframe. This cannot be changed.
But it permits for a second prediction to be calculated for a timeframe you can specify. The example in the chart above is the 1 hour overlaid on the 5 minute chart.
You can see how the model is performing in the statistics table. The statistics table can be removed as well if you don't want it overlaid on your chart.
You can also toggle off and on the various ranges. IF you only want to visualize 1 hour levels on a 5 minute chart, you can toggle off the bands and just view the higher tf data. Inversely, if you only want the current timeframe data and not the higher tf data, you can toggle the higher tf data off as well.
General Use Tips:
Some general use tips include:
🎯The default settings are appropriate for most common tickers. Because this is performing an autoregression on itself, the parameters tend to be more tight vs. performing dual correlation between two separate tickers which are sizably different in scale (which would require a higher tolerance).
Here is an example of YM1!, which is a sizably larger ticker, however it is performing well with the current settings.
🎯 If you get not great results from your ranges or an error in the correlation table, something like this:
It means the parameters are too tight for what you want to do and it is having trouble identifying other, similar cases (in this case, the lookback length was significantly shortened). The first step is to:
a) Expand your lookback range (up to 500 is usually sufficient). This should resolve most issues in most cases. If not:
b) If you are using the Cluster method, try broadening your cluster tolerance by 0.5 increments.
Between those two implementations, you should get a functional model. And it actually honestly hasn't happened to me in general use, I had to force that example by significantly shortening the lookback period.
Concluding Remarks
And that's pretty much the indicator.
I hope you enjoy it! I was really excited to be finally able to do it, like I said I attempted to do this for a while but needed to research the whole KNN process and how its performed.
Enjoy and leave your comments and questions below!
リリースノート
A very slight error I had to fix in the code. リリースノート
smh.... I review so many times but it always never fails that as soon as I hit publish, the errors start popping out front right and centre.Haha after the 20 thousandth look over, its good now!
リリースノート
fixオープンソーススクリプト
TradingViewの精神に則り、このスクリプトの作者はコードをオープンソースとして公開してくれました。トレーダーが内容を確認・検証できるようにという配慮です。作者に拍手を送りましょう!無料で利用できますが、コードの再公開はハウスルールに従う必要があります。
Get:
- Live Updates,
- Discord access,
- Access to my Proprietary Merlin Software,
- Access to premium indicators,
patreon.com/steversteves
Now on X!
- Live Updates,
- Discord access,
- Access to my Proprietary Merlin Software,
- Access to premium indicators,
patreon.com/steversteves
Now on X!
免責事項
この情報および投稿は、TradingViewが提供または推奨する金融、投資、トレード、その他のアドバイスや推奨を意図するものではなく、それらを構成するものでもありません。詳細は利用規約をご覧ください。
オープンソーススクリプト
TradingViewの精神に則り、このスクリプトの作者はコードをオープンソースとして公開してくれました。トレーダーが内容を確認・検証できるようにという配慮です。作者に拍手を送りましょう!無料で利用できますが、コードの再公開はハウスルールに従う必要があります。
Get:
- Live Updates,
- Discord access,
- Access to my Proprietary Merlin Software,
- Access to premium indicators,
patreon.com/steversteves
Now on X!
- Live Updates,
- Discord access,
- Access to my Proprietary Merlin Software,
- Access to premium indicators,
patreon.com/steversteves
Now on X!
免責事項
この情報および投稿は、TradingViewが提供または推奨する金融、投資、トレード、その他のアドバイスや推奨を意図するものではなく、それらを構成するものでもありません。詳細は利用規約をご覧ください。