Linear Regression Trend Navigator [QuantAlgo]🟢 Overview
The Linear Regression Trend Navigator is a trend-following indicator that combines statistical regression analysis with adaptive volatility bands to identify and track dominant market trends. It employs linear regression mathematics to establish the underlying trend direction, while dynamically adjusting trend boundaries based on standard deviation calculations to filter market noise and maintain trend continuity. The result is a straightforward visual system where green indicates bullish conditions favoring buy/long positions, and red signals bearish conditions supporting sell/short trades.
🟢 How It Works
The indicator operates through a three-phase computational process that transforms raw price data into adaptive trend signals. In the first phase, it calculates a linear regression line over the specified period, establishing the mathematical best-fit line through recent price action to determine the underlying directional bias. This regression line serves as the foundation for trend analysis by smoothing out short-term price variations while preserving the essential directional characteristics.
The second phase constructs dynamic volatility boundaries by calculating the standard deviation of price movements over the defined period and applying a user-adjustable multiplier. These upper and lower bounds create a volatility-adjusted channel around the regression line, with wider bands during volatile periods and tighter bands during stable conditions. This adaptive boundary system operates entirely behind the scenes, ensuring the trend signal remains relevant across different market volatility regimes without cluttering the visual display.
In the final phase, the system generates a simple trend line that dynamically positions itself within the volatility boundaries. When price action pushes the regression line above the upper bound, the trend line adjusts to the upper boundary level. Conversely, when the regression line falls below the lower bound, the trend line moves to the lower boundary. The result is a single colored line that transitions between green (rising trend line = buy/long) and red (declining trend line = sell/short).
🟢 How to Use
Green Trend Line: Upward momentum indicating favorable conditions for long positions, buy signals, and bullish strategies
Red Trend Line: Downward momentum signaling optimal timing for short positions, sell signals, and bearish approaches
Rising Green Line: Accelerating bullish momentum with steepening angles indicating strengthening upward pressure and potential for trend continuation
Declining Red Line: Intensifying bearish momentum with increasing negative slopes suggesting persistent downward pressure and shorting opportunities
Flattening Trend Lines: Gradual reduction in slope regardless of color may indicate approaching consolidation or momentum exhaustion requiring position review
🟢 Pro Tips for Trading and Investing
→ Entry/Exit Timing: Trade exclusively on band color transitions rather than price patterns, as each color change represents a statistically-confirmed shift that has passed through volatility filtering, providing higher probability setups than traditional technical analysis.
→ Parameter Optimization for Asset Classes: Customize the linear regression period based on your trading style. For example, use 5-10 bars for day trading to capture short-term statistical shifts, 14-20 for swing trading to balance responsiveness with stability, and 25-50 for position trading to filter out medium-term noise.
→ Volatility Calibration Strategy: Adjust the standard deviation multiplier according to market volatility. For instance, increase to 2.0+ during high-volatility periods like earnings or news events to reduce false signals, decrease to 1.0-1.5 during stable market conditions to maintain sensitivity to genuine trends.
→ Cross-Timeframe Statistical Validation: Apply the indicator across multiple timeframes simultaneously, using higher timeframes for directional bias and lower timeframes for entry timing.
→ Alert-Based Systematic Trading: Use built-in alerts to eliminate discretionary decision-making and ensure you capture every statistically-significant trend change, particularly effective for traders who cannot monitor charts continuously.
→ Risk Allocation Based on Signal Strength: Increase position sizes during periods of strong directional movement while reducing exposure during frequent band color changes that indicate statistical uncertainty or ranging conditions.
Regression
Polynomial Regression HeatmapPolynomial Regression Heatmap – Advanced Trend & Volatility Visualizer
Overview
The Polynomial Regression Heatmap is a sophisticated trading tool designed for traders who require a clear and precise understanding of market trends and volatility. By applying a second-degree polynomial regression to price data, the indicator generates a smooth trend curve, augmented with adaptive volatility bands and a dynamic heatmap. This framework allows users to instantly recognize trend direction, potential reversals, and areas of market strength or weakness, translating complex price action into a visually intuitive map.
Unlike static trend indicators, the Polynomial Regression Heatmap adapts to changing market conditions. Its visual design—including color-coded candles, regression bands, optional polynomial channels, and breakout markers—ensures that price behavior is easy to interpret. This makes it suitable for scalping, swing trading, and longer-term strategies across multiple asset classes.
How It Works
The core of the indicator relies on fitting a second-degree polynomial to a defined lookback period of price data. This regression curve captures the non-linear nature of market movements, revealing the true trajectory of price beyond the distortions of noise or short-term volatility.
Adaptive upper and lower bands are constructed using ATR-based scaling, surrounding the regression line to reflect periods of high and low volatility. When price moves toward or beyond these bands, it signals areas of potential overextension or support/resistance.
The heatmap colors each candle based on its relative position within the bands. Green shades indicate proximity to the upper band, red shades indicate proximity to the lower band, and neutral tones represent mid-range positioning. This continuous gradient visualization provides immediate feedback on trend strength, market balance, and potential turning points.
Optional polynomial channels can be overlaid around the regression curve. These three-line channels are based on regression residuals and a fixed width multiplier, offering additional reference points for analyzing price deviations, trend continuation, and reversion zones.
Signals and Breakouts
The Polynomial Regression Heatmap includes statistical pivot-based signals to highlight actionable price movements:
Buy Signals – A triangular marker appears below the candle when a pivot low occurs below the lower regression band.
Sell Signals – A triangular marker appears above the candle when a pivot high occurs above the upper regression band.
These markers identify significant deviations from the regression curve while accounting for volatility, providing high-quality visual cues for potential entry points.
The indicator ensures clarity by spacing markers vertically using ATR-based calculations, preventing overlap during periods of high volatility. Users can rely on these signals in combination with heatmap intensity and regression slope for contextual confirmation.
Interpretation
Trend Analysis :
The slope of the polynomial regression line represents trend direction. A rising curve indicates bullish bias, a falling curve indicates bearish bias, and a flat curve indicates consolidation.
Steeper slopes suggest stronger momentum, while gradual slopes indicate more moderate trend conditions.
Volatility Assessment :
Band width provides an instant visual measure of market volatility. Narrow bands correspond to low volatility and potential consolidation, whereas wide bands indicate higher volatility and significant price swings.
Heatmap Coloring :
Candle colors visually represent price position within the bands. This allows traders to quickly identify zones of bullish or bearish pressure without performing complex calculations.
Channel Analysis (Optional) :
The polynomial channel defines zones for evaluating potential overextensions or retracements. Price interacting with these lines may suggest areas where mean-reversion or trend continuation is likely.
Breakout Signals :
Buy and Sell markers highlight pivot points relative to the regression and volatility bands. These are statistical signals, not arbitrary triggers, and should be interpreted in context with trend slope, band width, and heatmap intensity.
Strategy Integration
The Polynomial Regression Heatmap supports multiple trading approaches:
Trend Following – Enter trades in the direction of the regression slope while using the heatmap for momentum confirmation.
Pullback Entries – Use breakouts or deviations from the regression bands as low-risk entry points during trend continuation.
Mean Reversion – Price reaching outer channel boundaries can indicate potential reversal or retracement opportunities.
Multi-Timeframe Alignment – Overlay on higher and lower timeframes to filter noise and improve entry timing.
Stop-loss levels can be set just beyond the opposing regression band, while take-profit targets can be informed by the distance between the bands or the curvature of the polynomial line.
Advanced Techniques
For traders seeking greater precision:
Combine the Polynomial Regression Heatmap with volume, momentum, or volatility indicators to validate signals.
Observe the width and slope of the regression bands over time to anticipate expanding or contracting volatility.
Track sequences of breakout signals in conjunction with heatmap intensity for systematic trade management.
Adjusting regression length allows customization for different assets or timeframes, balancing responsiveness and smoothing. The combination of polynomial curve, adaptive bands, heatmap, and optional channels provides a comprehensive statistical framework for informed decision-making.
Inputs and Customization
Regression Length – Determines the number of bars used for polynomial fitting. Shorter lengths increase responsiveness; longer lengths improve smoothing.
Show Bands – Toggle visibility of the ATR-based regression bands.
Show Channel – Enable or disable the polynomial channel overlay.
Color Settings – Customize bullish, bearish, neutral, and accent colors for clarity and visual preference.
All other internal parameters are fixed to ensure consistent statistical behavior and minimize potential misconfiguration.
Why Use Polynomial Regression Heatmap
The Polynomial Regression Heatmap transforms complex price action into a clear, actionable visual framework. By combining non-linear trend mapping, adaptive volatility bands, heatmap visualization, and breakout signals, it provides a multi-dimensional perspective that is both quantitative and intuitive.
This indicator allows traders to focus on execution, interpret market structure at a glance, and evaluate trend strength, overextensions, and potential reversals in real time. Its design is compatible with scalping, swing trading, and long-term strategies, providing a robust tool for disciplined, data-driven trading.
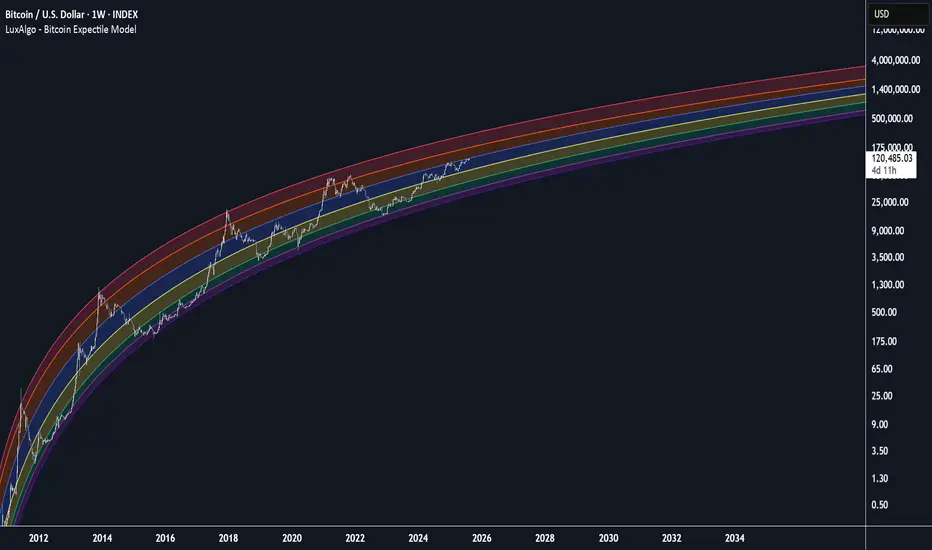
BTC Power Law Valuation BandsBTC Power Law Rainbow
A long-term valuation framework for Bitcoin based on Power Law growth — designed to help identify macro accumulation and distribution zones, aligned with long-term investor behavior.
🔍 What Is a Power Law?
A Power Law is a mathematical relationship where one quantity varies as a power of another. In this model:
Price ≈ a × (Time)^b
It captures the non-linear, exponentially slowing growth of Bitcoin over time. Rather than using linear or cyclical models, this approach aligns with how complex systems, such as networks or monetary adoption curves, often grow — rapidly at first, and then more slowly, but persistently.
🧠 Why Power Law for BTC?
Bitcoin:
Has finite supply and increasing adoption.
Operates as a monetary network , where Metcalfe’s Law and power laws naturally emerge.
Exhibits exponential growth over logarithmic time when viewed on a log-log chart .
This makes it uniquely well-suited for power law modeling.
🌈 How to Use the Valuation Bands
The central white line represents the modeled fair value according to the power law.
Colored bands represent deviations from the model in logarithmic space, acting as macro zones:
🔵 Lower Bands: Deep value / Accumulation zones.
🟡 Mid Bands: Fair value.
🔴 Upper Bands: Euphoria / Risk of macro tops.
📐 Smart Money Concepts (SMC) Alignment
Accumulation: Occurs when price consolidates near lower bands — often aligning with institutional positioning.
Markup: As price re-enters or ascends the bands, we often see breakout behavior and trend expansion.
Distribution: When price extends above upper bands, potential for exit liquidity creation and distribution events.
Reversion: Historically, price mean-reverts toward the model — rarely staying outside the bands for long.
This makes the model useful for:
Cycle timing
Long-term DCA strategy zones
Identifying value dislocations
Filtering short-term noise
⚠️ Disclaimer
This tool is for educational and informational purposes only . It is not financial advice. The power law model is a non-predictive, mathematical framework and does not guarantee future price movements .
Always use additional tools, risk management, and your own judgment before making trading or investment decisions.

Forecasting Quadratic Regression [UPDATED V6] Forecasting Quadratic Regression applies a second-degree polynomial regression model to price data, offering a non-linear alternative to traditional linear regression. By fitting a quadratic curve of the form:
y=a+bx+cx2
the indicator captures both directional trend and curvature, allowing traders to detect momentum shifts earlier than with straight-line models.
🔹 Core Features
Fits a quadratic regression curve to user-defined lookback periods
Extends the fitted curve forward to generate forecast projections
Calculates slope curvature to highlight trend acceleration or deceleration
Adapts dynamically as new bars are added
🔹 Trading Applications
Identify potential reversal zones when the curve inflects (2nd derivative sign change)
Forecast near-term mean reversion targets or extended trend continuations
Filter trades by measuring momentum curvature rather than linear slope
Visualize higher-order structure in price beyond standard regression lines
⚠️ Note: This model is statistical and assumes past curvature informs short-term future price paths. It should be combined with confirmation signals (volume, oscillators, support/resistance) to reduce false inflection points.

Bitcoin Expectile Model [LuxAlgo]The Bitcoin Expectile Model is a novel approach to forecasting Bitcoin, inspired by the popular Bitcoin Quantile Model by PlanC. By fitting multiple Expectile regressions to the price, we highlight zones of corrections or accumulations throughout the Bitcoin price evolution.
While we strongly recommend using this model with the Bitcoin All Time History Index INDEX:BTCUSD on the 3 days or weekly timeframe using a logarithmic scale, this model can be applied to any asset using the daily timeframe or superior.
Please note that here on TradingView, this model was solely designed to be used on the Bitcoin 1W chart, however, it can be experimented on other assets or timeframes if of interest.
🔶 USAGE
The Bitcoin Expectile Model can be applied similarly to models used for Bitcoin, highlighting lower areas of possible accumulation (support) and higher areas that allow for the anticipation of potential corrections (resistance).
By default, this model fits 7 individual Expectiles Log-Log Regressions to the price, each with their respective expectile ( tau ) values (here multiplied by 100 for the user's convenience). Higher tau values will return a fit closer to the higher highs made by the price of the asset, while lower ones will return fits closer to the lower prices observed over time.
Each zone is color-coded and has a specific interpretation. The green zone is a buy zone for long-term investing, purple is an anomaly zone for market bottoms that over-extend, while red is considered the distribution zone.
The fits can be extrapolated, helping to chart a course for the possible evolution of Bitcoin prices. Users can select the end of the forecast as a date using the "Forecast End" setting.
While the model is made for Bitcoin using a log scale, other assets showing a tendency to have a trend evolving in a single direction can be used. See the chart above on QQQ weekly using a linear scale as an example.
The Start Date can also allow fitting the model more locally, rather than over a large range of prices. This can be useful to identify potential shorter-term support/resistance areas.
🔶 DETAILS
🔹 On Quantile and Expectile Regressions
Quantile and Expectile regressions are similar; both return extremities that can be used to locate and predict prices where tops/bottoms could be more likely to occur.
The main difference lies in what we are trying to minimize, which, for Quantile regression, is commonly known as Quantile loss (or pinball loss), and for Expectile regression, simply Expectile loss.
You may refer to external material to go more in-depth about these loss functions; however, while they are similar and involve weighting specific prices more than others relative to our parameter tau, Quantile regression involves minimizing a weighted mean absolute error, while Expectile regression minimizes a weighted squared error.
The squared error here allows us to compute Expectile regression more easily compared to Quantile regression, using Iteratively reweighted least squares. For Quantile regression, a more elaborate method is needed.
In terms of comparison, Quantile regression is more robust, and easier to interpret, with quantiles being related to specific probabilities involving the underlying cumulative distribution function of the dataset; on the other expectiles are harder to interpret.
🔹 Trimming & Alterations
It is common to observe certain models ignoring very early Bitcoin price ranges. By default, we start our fit at the date 2010-07-16 to align with existing models.
By default, the model uses the number of time units (days, weeks...etc) elapsed since the beginning of history + 1 (to avoid NaN with log) as independent variable, however the Bitcoin All Time History Index INDEX:BTCUSD do not include the genesis block, as such users can correct for this by enabling the "Correct for Genesis block" setting, which will add the amount of missed bars from the Genesis block to the start oh the chart history.
🔶 SETTINGS
Start Date: Starting interval of the dataset used for the fit.
Correct for genesis block: When enabled, offset the X axis by the number of bars between the Bitcoin genesis block time and the chart starting time.
🔹 Expectiles
Toggle: Enable fit for the specified expectile. Disabling one fit will make the script faster to compute.
Expectile: Expectile (tau) value multiplied by 100 used for the fit. Higher values will produce fits that are located near price tops.
🔹 Forecast
Forecast End: Time at which the forecast stops.
🔹 Model Fit
Iterations Number: Number of iterations performed during the reweighted least squares process, with lower values leading to less accurate fits, while higher values will take more time to compute.
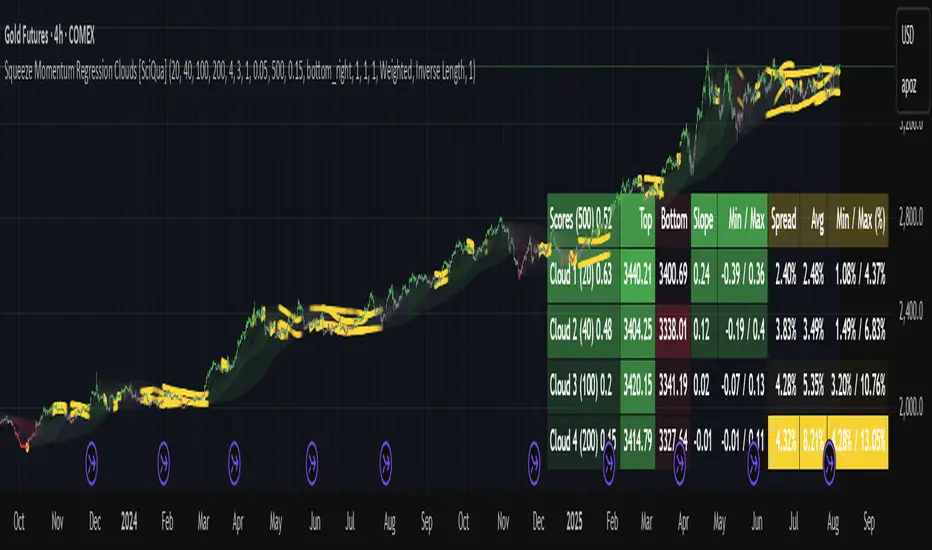
Squeeze Momentum Regression Clouds [SciQua]╭──────────────────────────────────────────────╮
☁️ Squeeze Momentum Regression Clouds
╰──────────────────────────────────────────────╯
🔍 Overview
The Squeeze Momentum Regression Clouds (SMRC) indicator is a powerful visual tool for identifying price compression , trend strength , and slope momentum using multiple layers of linear regression Clouds. Designed to extend the classic squeeze framework, this indicator captures the behavior of price through dynamic slope detection, percentile-based spread analytics, and an optional UI for trend inspection — across up to four customizable regression Clouds .
────────────────────────────────────────────────────────────
╭────────────────╮
⚙️ Core Features
╰────────────────╯
Up to 4 Regression Clouds – Each Cloud is created from a top and bottom linear regression line over a configurable lookback window.
Slope Detection Engine – Identifies whether each band is rising, falling, or flat based on slope-to-ATR thresholds.
Spread Compression Heatmap – Highlights compressed zones using yellow intensity, derived from historical spread analysis.
Composite Trend Scoring – Aggregates directional signals from each Cloud using your chosen weighting model.
Color-Coded Candles – Optional candle coloring reflects the real-time composite score.
UI Table – A toggleable info table shows slopes, compression levels, percentile ranks, and direction scores for each Cloud.
Gradient Cloud Styling – Apply gradient coloring from Cloud 1 to Cloud 4 for visual slope intensity.
Weight Aggregation Options – Use equal weighting, inverse-length weighting, or max pooling across Clouds to determine composite trend strength.
────────────────────────────────────────────────────────────
╭──────────────────────────────────────────╮
🧪 How to Use the Indicator
1. Understand Trend Bias with Cloud Colors
╰──────────────────────────────────────────╯
Each Cloud changes color based on its current slope:
Green indicates a rising trend.
Red indicates a falling trend.
Gray indicates a flat slope — often seen during chop or transitions.
Cloud 1 typically reflects short-term structure, while Cloud 4 represents long-term directional bias. Watch for multi-Cloud alignment — when all Clouds are green or red, the trend is strong. Divergence among Clouds often signals a potential shift.
────────────────────────────────────────────────────────────
╭───────────────────────────────────────────────╮
2. Use Compression Heat to Anticipate Breakouts
╰───────────────────────────────────────────────╯
The space between each Cloud’s top and bottom regression lines is measured, normalized, and analyzed over time. When this spread tightens relative to its history, the script highlights the band with a yellow compression glow .
This visual cue helps identify squeeze zones before volatility expands. If you see compression paired with a changing slope color (e.g., gray to green), this may indicate an impending breakout.
────────────────────────────────────────────────────────────
╭─────────────────────────────────╮
3. Leverage the Optional Table UI
╰─────────────────────────────────╯
The indicator includes a dynamic, floating table that displays real-time metrics per Cloud. These include:
Slope direction and value , with historical Min/Max reference.
Top and Bottom percentile ranks , showing how price sits within the Cloud range.
Current spread width , compared to its historical norms.
Composite score , which blends trend, slope, and compression for that Cloud.
You can customize the table’s position, theme, transparency, and whether to show a combined summary score in the header.
────────────────────────────────────────────────────────────
╭─────────────────────────────────────────────╮
4. Analyze Candle Color for Composite Signals
╰─────────────────────────────────────────────╯
When enabled, the indicator colors candles based on a weighted composite score. This score factors in:
The signed slope of each Cloud (up, down, or flat)
The percentile pressure from the top and bottom bands
The degree of spread compression
Expect green candles in bullish trend phases, red candles during bearish regimes, and gray candles in mixed or low-conviction zones.
Candle coloring provides a visual shorthand for market conditions , useful for intraday scanning or historical backtesting.
────────────────────────────────────────────────────────────
╭────────────────────────╮
🧰 Configuration Guidance
╰────────────────────────╯
To tailor the indicator to your strategy:
Use Cloud lengths like 21, 34, 55, and 89 for a balanced multi-timeframe view.
Adjust the slope threshold (default 0.05) to control how sensitive the trend coloring is.
Set the spread floor (e.g., 0.15) to tune when compression is detected and visualized.
Choose your weighting style : Inverse Length (favor faster bands), Equal, or Max Pooling (most aggressive).
Set composite weights to emphasize trend slope, percentile bias, or compression—depending on your market edge.
────────────────────────────────────────────────────────────
╭────────────────╮
✅ Best Practices
╰────────────────╯
Use aligned Cloud colors across all bands to confirm trend conviction.
Combine slope direction with compression glow for early breakout entry setups.
In choppy markets, watch for Clouds 1 and 2 turning flat while Clouds 3 and 4 remain directional — a sign of potential trend exhaustion or consolidation.
Keep the table enabled during backtesting to manually evaluate how each Cloud behaved during price turns and consolidations.
────────────────────────────────────────────────────────────
╭───────────────────────╮
📌 License & Usage Terms
╰───────────────────────╯
This script is provided under the Creative Commons Attribution-NonCommercial 4.0 International License .
✅ You are allowed to:
Use this script for personal or educational purposes
Study, learn, and adapt it for your own non-commercial strategies
❌ You are not allowed to:
Resell or redistribute the script without permission
Use it inside any paid product or service
Republish without giving clear attribution to the original author
For commercial licensing , private customization, or collaborations, please contact Joshua Danford directly.
Smart Trend Signals [QuantAlgo]🟢 Overview
The Smart Trend Signals indicator is created to address a fundamental challenge in technical analysis: generating timely trend signals while adapting to varying market volatility conditions. The indicator distinguishes itself by employing volatility-adjusted calculations that automatically modify signal sensitivity based on current market conditions, rather than using fixed parameters that perform inconsistently across different market environments. By processing Long and Short signals through separate dynamic calculation engines, each optimized for its respective directional bias, the indicator reduces the common issue of delayed or conflicting signals that plague many traditional trend-following tools. Additionally, the integration of linear regression-based trend confirmation adds another layer of signal validation, helping to filter market noise while maintaining responsiveness to genuine price movements. This adaptive approach makes the indicator practical for both traders and investors across different asset classes and timeframes, from short-term forex/crypto scalping to long-term equity position analysis.
🟢 How It Works
The indicator uses a straightforward calculation process that combines volatility measurement with momentum detection to generate directional signals. The system first calculates Average True Range (ATR) over a user-defined period to measure current market volatility. This ATR value is then multiplied by the Smart Trend Multiplier setting to create dynamic reference levels that expand during volatile periods and contract during calmer market conditions.
For signal generation, the indicator maintains separate calculation paths for Long/Buy and Short/Sell opportunities. Long signals are generated when price moves above a dynamically calculated level below the current price, confirmed by an exponential moving average crossover in the same direction. Short signals work in reverse, triggering when price moves below a calculated level above the current price, also requiring EMA confirmation. This dual-path approach allows each signal type to operate with parameters suited to its directional bias.
🟢 How to Use
Long Signals (Green Labels): Appear as "Long" labels below price bars when the indicator detects upward price momentum above the calculated reference level, confirmed by EMA crossover. These signals identify moments when price action demonstrates bullish characteristics based on the volatility-adjusted calculations.
Short Signals (Red Labels): Display as "Short" labels above price bars when downward price momentum below the reference level is detected and confirmed by EMA crossover. These signals highlight instances where price action exhibits bearish characteristics according to the indicator's mathematical framework.
Customizable Bar Coloring: This feature colors individual price bars to match the current signal direction. When enabled, each bar reflects the indicator's current directional bias, creating a continuous visual representation of trend periods across the chart timeline.
Built-in Alert System: Provides automatic notifications for new signals with detailed exchange and ticker information. The alert system monitors the indicator's calculations continuously and triggers notifications when new long or short signals are generated, allowing traders/investors to track multiple instruments simultaneously.
🟢 Pro Tips for Trading and Investing
→ Parameter Adjustment: Higher Smart Trend Multiplier settings generate fewer signals that may be more selective, while lower settings produce more frequent signals that may include more false positives. Test different settings to find what works for your trading style and market conditions.
→ Timeframe Analysis: Using higher timeframes for general trend direction and lower timeframes for entry timing is a common approach.
→ Risk Management: No indicator eliminates the need for proper risk management. Use appropriate position sizing and stop-loss strategies regardless of signal quality or frequency.
→ Market Conditions: The indicator may perform differently in trending versus ranging markets. Frequent signal changes might indicate choppy conditions. Backtest and paper trade before risking real capital.

Adaptive Market Profile – Auto Detect & Dynamic Activity ZonesAdaptive Market Profile is an advanced indicator that automatically detects and displays the most relevant trend channel and market profile for any asset and timeframe. Unlike standard regression channel tools, this script uses a fully adaptive approach to identify the optimal period, providing you with the channel that best fits the current market dynamics. The calculation is based on maximizing the statistical significance of the trend using Pearson’s R coefficient, ensuring that the most relevant trend is always selected.
Within the selected channel, the indicator generates a dynamic market profile, breaking the price range into configurable zones and displaying the most active areas based on volume or the number of touches. This allows you to instantly identify high-activity price levels and potential support/resistance zones. The “most active lines” are plotted in real-time and always stay parallel to the channel, dynamically adapting to market structure.
Key features:
- Automatic detection of the optimal regression period: The script scans a wide range of lengths and selects the channel that statistically represents the strongest trend.
- Dynamic market profile: Visualizes the distribution of volume or price touches inside the trend channel, with customizable section count.
- Most active zones: Highlights the most traded or touched price levels as dynamic, parallel lines for precise support/resistance reading.
- Manual override: Optionally, users can select their own channel period for full control.
- Supports both linear and logarithmic charts: Simple toggle to match your chart scaling.
Use cases:
- Trend following and channel trading strategies.
- Quick identification of dynamic support/resistance and liquidity zones.
- Objective selection of the most statistically significant trend channel, without manual guesswork.
- Suitable for all assets and timeframes (crypto, stocks, forex, futures).
Originality:
This script goes beyond basic regression channels by integrating dynamic profile analysis and fully adaptive period detection, offering a comprehensive tool for modern technical analysts. The combination of trend detection, market profile, and activity zone mapping is unique and not available in TradingView built-ins.
Instructions:
Add Adaptive Market Profile to your chart. By default, the script automatically detects the optimal channel period and displays the corresponding regression channel with dynamic profile and activity zones. If you prefer manual control, disable “Auto trend channel period” and set your preferred period. Adjust profile settings as needed for your asset and timeframe.
For questions, suggestions, or further customization, contact Julien Eche (@Julien_Eche) directly on TradingView.

52SIGNAL RECIPE CCI Linreg Bands═══ 52SIGNAL RECIPE CCI Linreg Bands ═══
◆ Overview
52SIGNAL RECIPE CCI Linreg Bands is an advanced technical indicator that combines the CCI (Commodity Channel Index) with Linear Regression Bands. This indicator visualizes the volatility of the CCI using linear regression bands, helping to clearly identify overbought/oversold areas and more accurately capture potential trend reversal points.
─────────────────────────────────────
◆ Key Features
• CCI-Based Overbought/Oversold Analysis: Uses the traditional CCI indicator to identify overbought/oversold conditions in the market
• Integrated Linear Regression Bands: Applies linear regression analysis to the CCI to visually represent the direction and strength of trends
• Dual Overbought/Oversold Levels: Sets overbought/oversold levels for both CCI and Linear Regression Bands to increase the accuracy of signals
• Advanced Visualization: Intuitive chart analysis is possible with color changes according to trend direction and clear band display
• Multiple Alert Settings: Alert functions for various conditions ensure you don't miss important trading moments
─────────────────────────────────────
◆ Technical Foundation
■ CCI (Commodity Channel Index)
• Basic Settings: 20-period CCI with Weighted Moving Average (WMA) applied
• Calculation Method: Measures the deviation from the average price normalized to a specific range
• Overbought/Oversold Levels: Default values set to +150 (overbought) and -150 (oversold)
■ Linear Regression Bands
• Period: Default value of 100 days
• Deviation: Default value of 4.5 standard deviations
• Center Line: The center line of the linear regression analysis for the CCI values
• Band Width: Displays the range of volatility around the center line based on the calculated standard deviation
• Overbought/Oversold Levels: Default values set to +250 (overbought) and -250 (oversold)
─────────────────────────────────────
◆ Practical Applications
■ Identifying Trading Signals
• Buy Signal:
▶ When the CCI falls below the oversold level (-150)
▶ When the lower band of the Linear Regression Bands falls below the oversold level (-250)
▶ When both conditions are met simultaneously (extreme oversold state) - a strong buy signal
• Sell Signal:
▶ When the CCI rises above the overbought level (+150)
▶ When the upper band of the Linear Regression Bands rises above the overbought level (+250)
▶ When both conditions are met simultaneously (extreme overbought state) - a strong sell signal
■ Trend Analysis
• Uptrend: When the linear regression center line is rising and the CCI is moving above the zero line
• Downtrend: When the linear regression center line is falling and the CCI is moving below the zero line
• Trend Strength: The wider the gap between the bands, the greater the volatility; the narrower, the more stable the trend
■ Divergence Confirmation
• Bearish Divergence: Price forms a new high, but the CCI is lower than the previous high (potential bearish signal)
• Bullish Divergence: Price forms a new low, but the CCI is higher than the previous low (potential bullish signal)
─────────────────────────────────────
◆ Advanced Setting Options
■ CCI Setting Adjustments
• CCI Source: Selectable options include Close (default), Open, High, Low, HL2, HLC3, OHLC4, etc.
• CCI Length: Adjust to lower values for short-term volatility, higher values for long-term trends
■ Linear Regression Setting Adjustments
• Period: Use lower values (20-50) for short-term analysis, higher values (100-200) for long-term analysis
• Deviation: Higher values create wider bands (more signals), lower values create narrower bands (more accurate signals)
■ Overbought/Oversold Level Adjustments
• CCI Levels: Adjust to more extreme values (±200) in highly volatile markets
• Linear Regression Band Levels: Adjustable to ±300 or ±200 depending on market conditions
─────────────────────────────────────
◆ Synergy with Other Indicators
• Bollinger Bands: Use alongside Bollinger Bands on the price chart to compare price volatility with CCI volatility
• MACD: Use with MACD for momentum and trend confirmation
• Fibonacci Retracement: Check CCI Linreg Bands signals with key support/resistance levels
• Moving Averages: Combine moving average crossovers with CCI Linreg Bands signals to improve reliability
─────────────────────────────────────
◆ Conclusion
52SIGNAL RECIPE CCI Linreg Bands provides a powerful and accurate technical analysis tool by combining traditional CCI with linear regression analysis. The dual overbought/oversold system increases the accuracy of trading signals and clearly visualizes trend direction and strength to help traders make decisions. You can achieve optimal results by adjusting various settings to match your trading style and market conditions.
─────────────────────────────────────
※ Disclaimer: Past performance does not guarantee future results. Always use appropriate risk management strategies.
═══ 52SIGNAL RECIPE CCI 선형회귀 밴드 ═══
◆ 개요
52SIGNAL RECIPE CCI 선형회귀 밴드는 CCI(Commodity Channel Index)와 선형회귀 밴드를 결합한 고급 기술적 지표입니다. 이 지표는 선형회귀 밴드를 사용하여 CCI의 변동성을 시각화하여 과매수/과매도 영역을 명확하게 식별하고 잠재적인 추세 반전 지점을 더 정확하게 포착하는 데 도움을 줍니다.
─────────────────────────────────────
◆ 주요 특징
• CCI 기반 과매수/과매도 분석: 전통적인 CCI 지표를 사용하여 시장의 과매수/과매도 상태를 식별
• 통합된 선형회귀 밴드: CCI에 선형회귀 분석을 적용하여 추세의 방향과 강도를 시각적으로 표현
• 이중 과매수/과매도 레벨: CCI와 선형회귀 밴드 모두에 과매수/과매도 레벨을 설정하여 신호의 정확도 향상
• 고급 시각화: 추세 방향에 따른 색상 변화와 명확한 밴드 표시로 직관적인 차트 분석 가능
• 다중 알림 설정: 다양한 조건에 대한 알림 기능으로 중요한 트레이딩 시점을 놓치지 않도록 보장
─────────────────────────────────────
◆ 기술적 기반
■ CCI (Commodity Channel Index)
• 기본 설정: 20기간 CCI에 가중이동평균(WMA) 적용
• 계산 방법: 평균 가격에 대한 편차를 측정하여 정규화한 값으로 표현
• 과매수/과매도 레벨: 기본값으로 +150(과매수)과 -150(과매도) 설정
■ 선형회귀 밴드
• 기간: 기본값 100일
• 편차: 기본값 4.5 표준편차
• 중심선: CCI 값에 대한 선형회귀 분석의 중심선
• 밴드 폭: 계산된 표준편차에 기반하여 중심선 주변의 변동성 범위 표시
• 과매수/과매도 레벨: 기본값으로 +250(과매수)와 -250(과매도) 설정
─────────────────────────────────────
◆ 실용적 응용
■ 트레이딩 신호 식별
• 매수 신호:
▶ CCI가 과매도 레벨(-150) 아래로 떨어질 때
▶ 선형회귀 밴드의 하단이 과매도 레벨(-250) 아래로 떨어질 때
▶ 두 조건이 동시에 충족될 때(극단적 과매도 상태) - 강한 매수 신호
• 매도 신호:
▶ CCI가 과매수 레벨(+150) 위로 상승할 때
▶ 선형회귀 밴드의 상단이 과매수 레벨(+250) 위로 상승할 때
▶ 두 조건이 동시에 충족될 때(극단적 과매수 상태) - 강한 매도 신호
■ 추세 분석
• 상승 추세: 선형회귀 중심선이 상승하고 CCI가 0선 위로 움직일 때
• 하락 추세: 선형회귀 중심선이 하락하고 CCI가 0선 아래로 움직일 때
• 추세 강도: 밴드 사이의 간격이 넓을수록 변동성이 크고, 좁을수록 추세가 안정적
■ 다이버전스 확인
• 약세 다이버전스: 가격이 신고점을 형성하지만 CCI가 이전 고점보다 낮을 때(잠재적 약세 신호)
• 강세 다이버전스: 가격이 신저점을 형성하지만 CCI가 이전 저점보다 높을 때(잠재적 강세 신호)
─────────────────────────────────────
◆ 고급 설정 옵션
■ CCI 설정 조정
• CCI 소스: 선택 가능한 옵션에는 종가(기본값), 시가, 고가, 저가, HL2, HLC3, OHLC4 등이 포함
• CCI 길이: 단기 변동성을 위해 낮은 값으로, 장기 추세를 위해 높은 값으로 조정
■ 선형회귀 설정 조정
• 기간: 단기 분석을 위해 낮은 값(20-50), 장기 분석을 위해 높은 값(100-200) 사용
• 편차: 높은 값은 더 넓은 밴드(더 많은 신호), 낮은 값은 더 좁은 밴드(더 정확한 신호) 생성
■ 과매수/과매도 레벨 조정
• CCI 레벨: 변동성이 큰 시장에서는 더 극단적인 값(±200)으로 조정
• 선형회귀 밴드 레벨: 시장 상황에 따라 ±300 또는 ±200으로 조정 가능
─────────────────────────────────────
◆ 다른 지표와의 시너지
• 볼린저 밴드: 가격 차트의 볼린저 밴드와 함께 사용하여 가격 변동성과 CCI 변동성 비교
• MACD: 모멘텀과 추세 확인을 위해 MACD와 함께 사용
• 피보나치 되돌림: CCI 선형회귀 밴드 신호를 주요 지지/저항 레벨과 함께 확인
• 이동평균선: 이동평균 교차와 CCI 선형회귀 밴드 신호를 결합하여 신뢰성 향상
─────────────────────────────────────
◆ 결론
52SIGNAL RECIPE CCI 선형회귀 밴드는 전통적인 CCI와 선형회귀 분석을 결합하여 강력하고 정확한 기술적 분석 도구를 제공합니다. 이중 과매수/과매도 시스템은 트레이딩 신호의 정확도를 높이고 추세 방향과 강도를 명확하게 시각화하여 트레이더의 의사 결정을 돕습니다. 다양한 설정을 트레이딩 스타일과 시장 상황에 맞게 조정하여 최적의 결과를 얻을 수 있습니다.
─────────────────────────────────────
※ 면책 조항: 과거 성과가 미래 결과를 보장하지 않습니다. 항상 적절한 리스크 관리 전략을 사용하세요.

52SIGNAL RECIPE RSI Linreg Bands═══ 52SIGNAL RECIPE RSI Linreg Bands ═══
◆ Overview
52SIGNAL RECIPE RSI Linreg Bands is an advanced technical indicator that combines the RSI (Relative Strength Index) with Linear Regression Bands. This indicator visualizes the volatility of the RSI using linear regression bands, helping to clearly identify overbought/oversold areas and more accurately capture potential trend reversal points.
─────────────────────────────────────
◆ Key Features
• RSI-Based Overbought/Oversold Analysis: Uses the traditional RSI indicator to identify overbought/oversold conditions in the market
• Integrated Linear Regression Bands: Applies linear regression analysis to the RSI to visually represent the direction and strength of trends
• Dual Overbought/Oversold Levels: Sets overbought/oversold levels for both RSI and Linear Regression Bands to increase the accuracy of signals
• Advanced Visualization: Intuitive chart analysis is possible with color changes according to trend direction and clear band display
• Multiple Alert Settings: Alert functions for various conditions ensure you don't miss important trading moments
─────────────────────────────────────
◆ Technical Foundation
■ RSI (Relative Strength Index)
• Basic Settings: 14-period RSI with 5-period Weighted Moving Average (WMA) applied
• Calculation Method: Measures the relative strength of gains and losses, expressed as a value between 0-100
• Overbought/Oversold Levels: Default values set to 70 (overbought) and 30 (oversold)
■ Linear Regression Bands
• Period: Default value of 100 days
• Deviation: Default value of 2.5 standard deviations
• Center Line: The center line of the linear regression analysis for the RSI values
• Band Width: Displays the range of volatility around the center line based on the calculated standard deviation
• Overbought/Oversold Levels: Default values set to 85 (overbought) and 15 (oversold)
─────────────────────────────────────
◆ Practical Applications
■ Identifying Trading Signals
• Buy Signal:
▶ When the RSI falls below the oversold level (30)
▶ When the lower band of the Linear Regression Bands falls below the oversold level (15)
▶ When both conditions are met simultaneously (extreme oversold state) - a strong buy signal
• Sell Signal:
▶ When the RSI rises above the overbought level (70)
▶ When the upper band of the Linear Regression Bands rises above the overbought level (85)
▶ When both conditions are met simultaneously (extreme overbought state) - a strong sell signal
■ Trend Analysis
• Uptrend: When the linear regression center line is rising and the RSI is moving above the midline (50)
• Downtrend: When the linear regression center line is falling and the RSI is moving below the midline (50)
• Trend Strength: The wider the gap between the bands, the greater the volatility; the narrower, the more stable the trend
■ Divergence Confirmation
• Bearish Divergence: Price forms a new high, but the RSI is lower than the previous high (potential bearish signal)
• Bullish Divergence: Price forms a new low, but the RSI is higher than the previous low (potential bullish signal)
─────────────────────────────────────
◆ Advanced Setting Options
■ RSI Setting Adjustments
• RSI Source: Selectable options include Close (default), Open, High, Low, HL2, HLC3, OHLC4, etc.
• RSI Length: Adjust to lower values for short-term volatility, higher values for long-term trends
■ Linear Regression Setting Adjustments
• Period: Use lower values (20-50) for short-term analysis, higher values (100-200) for long-term analysis
• Deviation: Higher values create wider bands (more signals), lower values create narrower bands (more accurate signals)
■ Overbought/Oversold Level Adjustments
• RSI Levels: Adjust to more extreme values (80/20) in highly volatile markets
• Linear Regression Band Levels: Adjustable to 90/10 or 80/20 depending on market conditions
─────────────────────────────────────
◆ Synergy with Other Indicators
• Bollinger Bands: Use alongside Bollinger Bands on the price chart to compare price volatility with RSI volatility
• MACD: Use with MACD for momentum and trend confirmation
• Fibonacci Retracement: Check RSI Linreg Bands signals with key support/resistance levels
• Moving Averages: Combine moving average crossovers with RSI Linreg Bands signals to improve reliability
─────────────────────────────────────
◆ Conclusion
52SIGNAL RECIPE RSI Linreg Bands provides a powerful and accurate technical analysis tool by combining traditional RSI with linear regression analysis. The dual overbought/oversold system increases the accuracy of trading signals and clearly visualizes trend direction and strength to help traders make decisions. You can achieve optimal results by adjusting various settings to match your trading style and market conditions.
─────────────────────────────────────
※ Disclaimer: Past performance does not guarantee future results. Always use appropriate risk management strategies.
═══ 52SIGNAL RECIPE RSI 선형회귀 밴드 ═══
◆ 개요
52SIGNAL RECIPE RSI 선형회귀 밴드는 RSI(상대강도지수)와 선형회귀 밴드를 결합한 고급 기술적 지표입니다. 이 지표는 선형회귀 밴드를 사용하여 RSI의 변동성을 시각화하여 과매수/과매도 영역을 명확하게 식별하고 잠재적인 추세 반전 지점을 더 정확하게 포착하는 데 도움을 줍니다.
─────────────────────────────────────
◆ 주요 특징
• RSI 기반 과매수/과매도 분석: 전통적인 RSI 지표를 사용하여 시장의 과매수/과매도 상태를 식별
• 통합된 선형회귀 밴드: RSI에 선형회귀 분석을 적용하여 추세의 방향과 강도를 시각적으로 표현
• 이중 과매수/과매도 레벨: RSI와 선형회귀 밴드 모두에 과매수/과매도 레벨을 설정하여 신호의 정확도 향상
• 고급 시각화: 추세 방향에 따른 색상 변화와 명확한 밴드 표시로 직관적인 차트 분석 가능
• 다중 알림 설정: 다양한 조건에 대한 알림 기능으로 중요한 트레이딩 시점을 놓치지 않도록 보장
─────────────────────────────────────
◆ 기술적 기반
■ RSI (상대강도지수)
• 기본 설정: 14기간 RSI에 5기간 가중이동평균(WMA) 적용
• 계산 방법: 상승과 하락의 상대적 강도를 측정하여 0-100 사이의 값으로 표현
• 과매수/과매도 레벨: 기본값으로 70(과매수)과 30(과매도) 설정
■ 선형회귀 밴드
• 기간: 기본값 100일
• 편차: 기본값 2.5 표준편차
• 중심선: RSI 값에 대한 선형회귀 분석의 중심선
• 밴드 폭: 계산된 표준편차에 기반하여 중심선 주변의 변동성 범위 표시
• 과매수/과매도 레벨: 기본값으로 85(과매수)와 15(과매도) 설정
─────────────────────────────────────
◆ 실용적 응용
■ 트레이딩 신호 식별
• 매수 신호:
▶ RSI가 과매도 레벨(30) 아래로 떨어질 때
▶ 선형회귀 밴드의 하단이 과매도 레벨(15) 아래로 떨어질 때
▶ 두 조건이 동시에 충족될 때(극단적 과매도 상태) - 강한 매수 신호
• 매도 신호:
▶ RSI가 과매수 레벨(70) 위로 상승할 때
▶ 선형회귀 밴드의 상단이 과매수 레벨(85) 위로 상승할 때
▶ 두 조건이 동시에 충족될 때(극단적 과매수 상태) - 강한 매도 신호
■ 추세 분석
• 상승 추세: 선형회귀 중심선이 상승하고 RSI가 중간선(50) 위로 움직일 때
• 하락 추세: 선형회귀 중심선이 하락하고 RSI가 중간선(50) 아래로 움직일 때
• 추세 강도: 밴드 사이의 간격이 넓을수록 변동성이 크고, 좁을수록 추세가 안정적
■ 다이버전스 확인
• 약세 다이버전스: 가격이 신고점을 형성하지만 RSI가 이전 고점보다 낮을 때(잠재적 약세 신호)
• 강세 다이버전스: 가격이 신저점을 형성하지만 RSI가 이전 저점보다 높을 때(잠재적 강세 신호)
─────────────────────────────────────
◆ 고급 설정 옵션
■ RSI 설정 조정
• RSI 소스: 선택 가능한 옵션에는 종가(기본값), 시가, 고가, 저가, HL2, HLC3, OHLC4 등이 포함
• RSI 길이: 단기 변동성을 위해 낮은 값으로, 장기 추세를 위해 높은 값으로 조정
■ 선형회귀 설정 조정
• 기간: 단기 분석을 위해 낮은 값(20-50), 장기 분석을 위해 높은 값(100-200) 사용
• 편차: 높은 값은 더 넓은 밴드(더 많은 신호), 낮은 값은 더 좁은 밴드(더 정확한 신호) 생성
■ 과매수/과매도 레벨 조정
• RSI 레벨: 변동성이 큰 시장에서는 더 극단적인 값(80/20)으로 조정
• 선형회귀 밴드 레벨: 시장 상황에 따라 90/10 또는 80/20으로 조정 가능
─────────────────────────────────────
◆ 다른 지표와의 시너지
• 볼린저 밴드: 가격 차트의 볼린저 밴드와 함께 사용하여 가격 변동성과 RSI 변동성 비교
• MACD: 모멘텀과 추세 확인을 위해 MACD와 함께 사용
• 피보나치 되돌림: RSI 선형회귀 밴드 신호를 주요 지지/저항 레벨과 함께 확인
• 이동평균선: 이동평균 교차와 RSI 선형회귀 밴드 신호를 결합하여 신뢰성 향상
─────────────────────────────────────
◆ 결론
52SIGNAL RECIPE RSI 선형회귀 밴드는 전통적인 RSI와 선형회귀 분석을 결합하여 강력하고 정확한 기술적 분석 도구를 제공합니다. 이중 과매수/과매도 시스템은 트레이딩 신호의 정확도를 높이고 추세 방향과 강도를 명확하게 시각화하여 트레이더의 의사 결정을 돕습니다. 다양한 설정을 트레이딩 스타일과 시장 상황에 맞게 조정하여 최적의 결과를 얻을 수 있습니다.
─────────────────────────────────────
※ 면책 조항: 과거 성과가 미래 결과를 보장하지 않습니다. 항상 적절한 리스크 관리 전략을 사용하세요.
Logistic Regression ICT FVG🚀 OVERVIEW
Welcome to the Logistic Regression Fair Value Gap (FVG) System — a next-gen trading tool that blends precision gap detection with machine learning intelligence.
Unlike traditional FVG indicators, this one evolves with each bar of price action, scoring and filtering gaps based on real market behavior.
🔧 CORE FEATURES
✨ Smart Gap Detection
Automatically identifies bullish and bearish Fair Value Gaps using volatility-aware candle logic.
📊 Probability-Based Filtering
Uses logistic regression to assign each gap a confidence score (0 to 1), showing only high-probability setups.
🔁 Real-Time Retest Tracking
Continuously watches how price interacts with each gap to determine if it deserves respect.
📈 Multi-Factor Assessment
Evaluates RSI, MACD, and body size at gap formation to build a full context snapshot.
🧠 Self-Learning Engine
The logistic regression model updates on each bar using gradient descent, refining its predictions over time.
📢 Built-In Alerts
Get instant alerts when a gap forms, gets retested, or breaks.
🎨 Custom Display Options
Control the color of bullish/bearish zones, and toggle on/off probability labels for cleaner charts.
🚩 WHAT MAKES IT DIFFERENT
This isn’t just another box-drawing indicator.
While others mark every imbalance, this system thinks before it draws — using statistical modeling to filter out noise and prioritize high-impact zones.
By learning from how price behaves around gaps (not just how they form), it helps you trade only what matters — not what clutters.
⚙️ HOW IT WORKS
1️⃣ Detection
FVGs are identified using ATR-based thresholds and sharp wick imbalances.
2️⃣ Behavior Monitoring
Every gap is tracked — and if respected enough times, it becomes part of the elite training set.
3️⃣ Context Capture
Each new FVG logs RSI, MACD, and body size to provide a feature-rich context for prediction.
4️⃣ Prediction (Logistic Regression)
The model predicts how likely the gap is to be respected and assigns it a probability score.
5️⃣ Classification & Alerts
Gaps above the threshold are plotted with score labels, and alerts trigger for entry/respect/break.
⚙️ CONFIGURATION PANEL
🔧 System Inputs
• Max Retests – How many times a gap must be respected to train the model
• Prediction Threshold – Minimum score to show a gap on the chart
• Learning Rate – Controls how fast the model adapts (default: 0.009)
• Max FVG Lifetime – Expiration duration for unused gaps
• Show Historic Gaps – Show/hide expired or invalidated gaps
🎨 Visual Options
• Bullish/Bearish Colors – Set gap colors to fit your chart style
• Confidence Labels – Show probability scores next to FVGs
• Alert Toggles – Enable alerts for:
– New FVG detected
– FVG respected (entry)
– FVG invalidated (break)
💡 WHY LOGISTIC REGRESSION?
Traditional FVG tools rely on candle shapes.
This system relies on probability — by training on RSI, MACD, and price behavior, it predicts whether a gap will act as a true liquidity zone.
Logistic regression lets the system continuously adapt using new data, making it more accurate the longer it runs.
That means smarter signals, fewer false positives, and a clearer view of where real opportunities lie.
Xcalibur Signals & Alerts [AlgoXcalibur]An advanced trend-following algorithm forged to empower retail traders with an edge.
Xcalibur Signals & Alerts is a sophisticated, multi-layered algorithm designed to consistently deliver real-time trend signals—without clutter or unnecessary complexity. The system combines refined trend-following logic with breakout detection, flat-market filtration, false signal failsafes, take profit cues, live alerts, and more — all in a visually simple, easy-to-use indicator built for all assets, timeframes, and market conditions.
🧠 Algorithm Logic
Xcalibur Signals & Alerts operates on a systematic framework that evaluates multiple technical dimensions in harmony—directional alignment, momentum confirmation, relative strength, volume bias, breakout detection, Fibonacci calculations, and more. Rather than reacting to isolated triggers, it filters every opportunity through a multi-layered confirmation engine. It doesn’t just react to every move—it evaluates them. This cohesive approach ensures that each signal results from aligned conditions—not arbitrary thresholds. By combining structural awareness with adaptive filtering, Xcalibur maintains clarity and consistency across a wide range of market environments—delivering actionable signals without unnecessary noise or lag.
⚙️ User-Adjustable Features
• Adjustable Sensitivity:
Choose from 5 pre-tuned Signal Trigger Settings and 3 dynamic Confirmation Filter Modes to tailor the system to your trading style, asset, and timeframe. Candle color reflects the active trigger condition, while an adaptive cyan line displays the selected Confirmation Filter—blocking signals until the filter threshold is crossed.
• Directional Stability Filter: When enabled, this filter uses mean-reversion calculations to determine directional bias and block unreliable signals during choppy, indecisive price action. A magenta line represents this filter threshold and provides higher-confidence signals during periods of low directional conviction.
• Pullback Allowance Filter:
When enabled, this unique filter uses Fibonacci ratios to deliberately block signals from temporary pullbacks during strong trend periods. A green (uptrend) or red (downtrend) line marks the active pullback allowance zone.
• False Signal Failsafe
:
Two selectable modes:
Simple — Cancels the signal if price breaks the signal candle’s high or low.
Advanced — Requires both a price break and opposing momentum confirmation.
When triggered, the system plots a white “X” signal, turns candles gray, disables the background color, sends an alert (if enabled), and enters standby mode until a valid trend condition re-emerges.
• Reaction Zones:
Identifies probable reversal or breakout zones based on recent price action patterns. A yellow line appears when active, with a yellow caution flag plotted if the price reaches this critical area.
• Take-Profit Cues
: Automatically detects potential trend exhaustion using price action structure and momentum shifts. When triggered, a visual “TP” marker is plotted—advising traders to manage profits or prepare for a possible reversal.
• Trailing Stop:
Plots a dynamic, percentage-based trailing stop or trailing take-profit using your selected input. Adjust it to suit your risk tolerance and asset.
• Multi-Timeframe Monitor
: Displays real-time trend direction across 1m, 2m, 5m, 15m, 1H, 4H, and 1D timeframes in a compact, easy-to-read table.
• Alert System
:
Receive desktop and/or mobile alerts for:
* New trend signals
* Failsafe triggers
* 9:00 AM Morning Greeting messages with auto re-arming confirmation
(Alerts are limited to 9:00 AM – 4:00 PM Eastern Time)
• SuperCandles
: Highlights strong momentum moves with a stunning and easily recognizable glow effect.
• Color-Coded Candles & Background
: Candles reflect the current trigger condition, while the background tint tracks the most recent trend—enhancing situational awareness.
*All input settings include tooltips to guide users through setup and interpretation.
⚔️ Not Just Another Signal Tool
Xcalibur Signals & Alerts was built from the ground up to empower retail traders with access to a cohesive, structured algorithmic system—one that reflects the kind of awareness, discipline, and market adaptability found in professional-grade algorithms.
This is not another oversensitive or under-responsive signal indicator that is limited to one specific type of market condition or trader. It does not utilize hyperactive triggers, rely on lagging crossover logic, or need infinitely adjustable and complex sensitivity settings. Instead of cluttered visuals to interpret, this indicator delivers a simple, easy-to-use tool—prioritizing clarity and usability without compromising on depth and sophistication.
Whether the market is trending, breaking out, or moving sideways, Xcalibur adapts—prioritizing trend stability, directional integrity, and visual clarity from one signal to the next.
⚠️ While the Xcalibur Signals & Alerts algorithm is immune to human emotion, you are not. Be mindful not to fall victim to costly emotions that can manipulate your judgment, and understand the unpredictable and complex nature of trading. No algorithm, strategy, or technique can deliver perfect accuracy, and Xcalibur Signals & Alerts is no exception. While AlgoXcalibur strives to be as accurate as possible, incorrect signals can and will occur. Xcalibur Signals & Alerts is a tool, not a guarantee. Users are fully responsible for making their own trading decisions, implementing proper risk management, and always trading responsibly.
🛡️ Wield Xcalibur as a standalone weapon or use it alongside other tools.
🔐 To get access or learn more, visit the Author’s Instructions section.

Ultimate Regression Channel v5.0 [WhiteStone_Ibrahim]Ultimate Regression Channel v5.0: Comprehensive User Guide
This indicator is designed to visualize the current trend, potential support/resistance levels, and market volatility through a statistical analysis of price action. At its core, it plots a regression line (a trend line) based on prices over a specific period and adds channels based on standard deviation around this line.
1. Core Features and Settings
Length Mode:
Numerical (Manual): You define the number of bars to be used for the regression channel calculation. You can use lower values (e.g., 50-100) for short-term analysis and higher values (e.g., 200-300) to identify long-term trends.
Automatic (Based on Market Structure): This mode automatically draws the channel starting from the highest high or lowest low that has formed within the Auto Scan Period. This allows the indicator to adapt itself to significant market turning points (swing points), which is highly useful.
Regression Model:
Linear: Calculates the trend as a straight line. It generally works well in stable, short-to-medium-term trends.
Logarithmic: Calculates the trend as a curved line. It more accurately reflects price action, especially on long-term charts or for assets that experience exponential growth/decline (like cryptocurrencies or growth stocks).
Channel Widths:
These settings determine how far from the central trend line (in terms of standard deviations) the channels will be drawn.
The 0 (Inner), 1 (Middle), and 2 (Outer) channels represent the "normal" range of price movement and the "extreme" zones. Statistically, about 95% of all price action occurs within the outer channels (2nd standard deviation).
2. Visual Extras and Their Interpretation
Breakout Style:
This feature alerts you when the price closes above the uppermost channel (Channel 2) with a green arrow/background or below the lowermost channel with a red arrow/background.
This is a very important signal. A breakout can signify that the current trend is strengthening and likely to continue (a breakout/trend-following strategy) or that the market has become overextended and may be due for a reversal (an exhaustion/top-bottom signal). It is critical to confirm this signal with other indicators (e.g., RSI, Volume).
Info Label:
This provides an at-a-glance summary of the channel on the right side of the chart:
Trend Status: Identifies the trend as "Uptrend," "Downtrend," or "Sideways" based on the slope of the centerline. The Horizontal Threshold setting allows you to filter out noise by treating very small slopes as "Sideways."
Regression Model and Length: Shows your current settings.
Trend Slope: A numerical value representing how steep or weak the trend is.
Channel Width: Shows the price difference between the outermost channels. This is a measure of current volatility. A widening channel indicates increasing volatility, while a narrowing one indicates decreasing volatility.
3. What Users Should Pay Attention To & Best Practices
Define Your Strategy: Mean Reversion or Breakout?
Mean Reversion: If the market is in a ranging or gently trending phase, the price will tend to revert to the centerline after hitting the outer channels (overbought/oversold zones). In this case, the outer channels can be considered opportunities to sell (upper channel) or buy (lower channel).
Breakout: If a strong trend is in place, a price close beyond an outer channel can be a sign that the trend is accelerating. In this scenario, one might consider taking a position in the direction of the breakout. Correctly analyzing the current market state (ranging vs. trending) is key to deciding which strategy to employ.
Don't Use It in Isolation: No indicator is a holy grail. Use the Regression Channel in conjunction with other tools. Confirm signals with RSI divergences for overbought/oversold conditions, Moving Averages for the overall trend direction, or Volume indicators to confirm the strength of a breakout.
Choose the Right Model: On shorter-term charts (e.g., 1-hour, 4-hour), the Linear model is often sufficient. However, on long-term charts like the daily, weekly, or monthly, the Logarithmic model will provide much more accurate results, especially for assets with parabolic movements.
The Power of Automatic Mode: The Automatic length mode is often the most practical choice because it finds the most logical starting point for you. It saves you the trouble of adjusting settings, especially when analyzing different assets or timeframes.
Use the Alerts: If you don't want to miss the moment the price touches a key channel line, set up an alert from the Alert Settings section for your desired line (e.g., only the "Outer Channels"). This helps you catch opportunities even when you are not in front of the screen.
Bitcoin Power Law [LuxAlgo]The Bitcoin Power Law tool is a representation of Bitcoin prices first proposed by Giovanni Santostasi, Ph.D. It plots BTCUSD daily closes on a log10-log10 scale, and fits a linear regression channel to the data.
This channel helps traders visualise when the price is historically in a zone prone to tops or located within a discounted zone subject to future growth.
🔶 USAGE
Giovanni Santostasi, Ph.D. originated the Bitcoin Power-Law Theory; this implementation places it directly on a TradingView chart. The white line shows the daily closing price, while the cyan line is the best-fit regression.
A channel is constructed from the linear fit root mean squared error (RMSE), we can observe how price has repeatedly oscillated between each channel areas through every bull-bear cycle.
Excursions into the upper channel area can be followed by price surges and finishing on a top, whereas price touching the lower channel area coincides with a cycle low.
Users can change the channel areas multipliers, helping capture moves more precisely depending on the intended usage.
This tool only works on the daily BTCUSD chart. Ticker and timeframe must match exactly for the calculations to remain valid.
🔹 Linear Scale
Users can toggle on a linear scale for the time axis, in order to obtain a higher resolution of the price, (this will affect the linear regression channel fit, making it look poorer).
🔶 DETAILS
One of the advantages of the Power Law Theory proposed by Giovanni Santostasi is its ability to explain multiple behaviors of Bitcoin. We describe some key points below.
🔹 Power-Law Overview
A power law has the form y = A·xⁿ , and Bitcoin’s key variables follow this pattern across many orders of magnitude. Empirically, price rises roughly with t⁶, hash-rate with t¹² and the number of active addresses with t³.
When we plot these on log-log axes they appear as straight lines, revealing a scale-invariant system whose behaviour repeats proportionally as it grows.
🔹 Feedback-Loop Dynamics
Growth begins with new users, whose presence pushes the price higher via a Metcalfe-style square-law. A richer price pool funds more mining hardware; the Difficulty Adjustment immediately raises the hash-rate requirement, keeping profit margins razor-thin.
A higher hash rate secures the network, which in turn attracts the next wave of users. Because risk and Difficulty act as braking forces, user adoption advances as a power of three in time rather than an unchecked S-curve. This circular causality repeats without end, producing the familiar boom-and-bust cadence around the long-term power-law channel.
🔹 Scale Invariance & Predictions
Scale invariance means that enlarging the timeline in log-log space leaves the trajectory unchanged.
The same geometric proportions that described the first dollar of value can therefore extend to a projected million-dollar bitcoin, provided no catastrophic break occurs. Institutional ETF inflows supply fresh capital but do not bend the underlying slope; only a persistent deviation from the line would falsify the current model.
🔹 Implications
The theory assigns scarcity no direct role; iterative feedback and the Difficulty Adjustment are sufficient to govern Bitcoin’s expansion. Long-term valuation should focus on position within the power-law channel, while bubbles—sharp departures above trend that later revert—are expected punctuations of an otherwise steady climb.
Beyond about 2040, disruptive technological shifts could alter the parameters, but for the next order of magnitude the present slope remains the simplest, most robust guide.
Bitcoin behaves less like a traditional asset and more like a self-organising digital organism whose value, security, and adoption co-evolve according to immutable power-law rules.
🔶 SETTINGS
🔹 General
Start Calculation: Determine the start date used by the calculation, with any prior prices being ignored. (default - 15 Jul 2010)
Use Linear Scale for X-Axis: Convert the horizontal axis from log(time) to linear calendar time
🔹 Linear Regression
Show Regression Line: Enable/disable the central power-law trend line
Regression Line Color: Choose the colour of the regression line
Mult 1: Toggle line & fill, set multiplier (default +1), pick line colour and area fill colour
Mult 2: Toggle line & fill, set multiplier (default +0.5), pick line colour and area fill colour
Mult 3: Toggle line & fill, set multiplier (default -0.5), pick line colour and area fill colour
Mult 4: Toggle line & fill, set multiplier (default -1), pick line colour and area fill colour
🔹 Style
Price Line Color: Select the colour of the BTC price plot
Auto Color: Automatically choose the best contrast colour for the price line
Price Line Width: Set the thickness of the price line (1 – 5 px)
Show Halvings: Enable/disable dotted vertical lines at each Bitcoin halving
Halvings Color: Choose the colour of the halving lines

Fair Value Trend Model [SiDec]ABSTRACT
This pine script introduces the Fair Value Trend Model, an on-chart indicator for TradingView that constructs a continuously updating "fair-value" estimate of an asset's price via a logarithmic regression on historical data. Specifically, this model has been applied to Bitcoin (BTC) to fully grasp its fair value in the cryptocurrency market. Symmetric channel bands, defined by fixed percentage offsets around this central fair-value curve, provide a visual band within which normal price fluctuations may occur. Additionally, a short-term projection extends both the fair-value trend and its channel bands forward by a user-specified number of bars.
INTRODUCTION
Technical analysts frequently seek to identify an underlying equilibrium or "fair value" about which prices oscillate. Traditional approaches-moving averages, linear regressions in price-time space, or midlines-capture linear trends but often misrepresent the exponential or power-law growth patterns observable in many financial markets. The Fair Value Trend Model addresses this by performing an ordinary least squares (OLS) regression in log-space, fitting ln(Price) against ln(Days since inception). In practice, the primary application has been to Bitcoin, aiming to fully capture Bitcoin's underlying value dynamics.
The result is a curved trend line in regular (price-time) coordinates, reflecting Bitcoin's long-term compounding characteristics. Surrounding this fair-value curve, symmetric bands at user-specified percentage deviations serve as dynamic support and resistance levels. A simple linear projection extends both the central fair-value and its bands into the immediate future, providing traders with a heuristic for short-term trend continuation.
This exposition details:
Data transformation: converting bar timestamps into days since first bar, then applying natural logarithms to both time and price.
Regression mechanics: incremental (or rolling-window) accumulation of sums to compute the log-space fit parameters.
Fair-value reconstruction: exponentiation of the regression output to yield a price-space estimate.
Channel-band definition: establishing ±X% offsets around the fair-value curve and rendering them visually.
Forecasting methodology: projecting both the fair-value trend and channel bands by extrapolating the most recent incremental change in price-space.
Interpretation: how traders can leverage this model for trend identification, mean-reversion setups, and breakout analysis, particularly in Bitcoin trading.
Analysing the macro cycle on Bitcoin's monthly timeframe illustrates how the fair-value curve aligns with multi-year structural turning points.
DATA TRANSFORMATION AND NOTATION
1. Timestamp Baseline (t0)
Let t0 = timestamp of the very first bar on the chart (in milliseconds). Each subsequent bar has a timestamp ti, where ti ≥ t0.
2. Days Since Inception (d(t))
Define the “days since first bar” as
d(t) = max(1, (t − t0) / 86400000.0)
Here, 86400000.0 represents the number of milliseconds in one day (1,000 ms × 60 seconds × 60 minutes × 24 hours). The lower bound of 1 ensures that we never compute ln(0).
3. Logarithmic Coordinates:
Given the bar’s closing price P(t), define:
xi = ln( d(ti) )
yi = ln( P(ti) )
Thus, each data point is transformed to (xi, yi) in log‐space.
REGRESSION FORMULATION
We assume a log‐linear relationship:
yi = a + b·xi + εi
where εi is the residual error at bar i. Ordinary least squares (OLS) fitting minimizes the sum of squared residuals over N data points. Define the following accumulated sums:
Sx = Σ for i = 1 to N
Sy = Σ for i = 1 to N
Sxy = Σ for i = 1 to N
Sx2 = Σ for i = 1 to N
N = number of data points
The OLS estimates for b (slope) and a (intercept) are:
b = ( N·Sxy − Sx·Sy ) / ( N·Sx2 − (Sx)^2 )
a = ( Sy − b·Sx ) / N
All‐Time Versus Rolling‐Window Mode:
All-Time Mode:
Each new bar increments N by 1.
Update Sx ← Sx + xN, Sy ← Sy + yN, Sxy ← Sxy + xN·yN, Sx2 ← Sx2 + xN^2.
Recompute a and b using the formulas above on the entire dataset.
Rolling-Window Mode:
Fix a window length W. Maintain two arrays holding the most recent W values of {xi} and {yi}.
On each new bar N:
Append (xN, yN) to the arrays; add xN, yN, xN·yN, xN^2 to the sums Sx, Sy, Sxy, Sx2.
If the arrays’ length exceeds W, remove the oldest point (xN−W, yN−W) and subtract its contributions from the sums.
Update N_roll = min(N, W).
Compute b and a using N_roll, Sx, Sy, Sxy, Sx2 as above.
This incremental approach requires only O(1) operations per bar instead of recomputing sums from scratch, making it computationally efficient for long time series.
FAIR‐VALUE RECONSTRUCTION
Once coefficients (a, b) are obtained, the regressed log‐price at time t is:
ŷ(t) = a + b·ln( d(t) )
Mapping back to price space yields the “fair‐value”:
F(t) = exp( ŷ(t) )
= exp( a + b·ln( d(t) ) )
= exp(a) · ^b
In other words, F(t) is a power‐law function of “days since inception,” with exponent b and scale factor C = exp(a). Special cases:
If b = 1, F(t) = C · d(t), which is an exponential function in original time.
If b > 1, the fair‐value grows super‐linearly (accelerating compounding).
If 0 < b < 1, it grows sub‐linearly.
If b < 0, the fair‐value declines over time.
CHANNEL‐BAND DEFINITION
To visualise a “normal” range around the fair‐value curve F(t), we define two channel bands at fixed percentage offsets:
1. Upper Channel Band
U(t) = F(t) · (1 + α_upper)
where α_upper = (Channel Band Upper %) / 100.
2. Lower Channel Band
L(t) = F(t) · (1 − α_lower)
where α_lower = (Channel Band Lower %) / 100.
For example, default values of 50% imply α_upper = α_lower = 0.50, so:
U(t) = 1.50 · F(t)
L(t) = 0.50 · F(t)
When “Show FV Channel Bands” is enabled, both U(t) and L(t) are plotted in a neutral grey, and a semi‐transparent fill is drawn between them to emphasise the channel region.
SHORT‐TERM FORECAST PROJECTION
To extend both the fair‐value and its channel bands M bars into the future, the model uses a simple constant‐increment extrapolation in price space. The procedure is:
1. Compute Recent Increments
Let
F_prev = F( t_{N−1} )
F_curr = F( t_N )
Then define the per‐bar change in fair‐value:
ΔF = F_curr − F_prev
Similarly, for channel bands:
U_prev = U( t_{N−1} ), U_curr = U( t_N ), ΔU = U_curr − U_prev
L_prev = L( t_{N−1} ), L_curr = L( t_N ), ΔL = L_curr − L_prev
2. Forecasted Values After M Bars
Assuming the same per‐bar increments continue:
F_future = F_curr + M · ΔF
U_future = U_curr + M · ΔU
L_future = L_curr + M · ΔL
These forecasted values produce dashed lines on the chart:
A dashed segment from (bar_N, F_curr) to (bar_{N+M}, F_future).
Dashed segments from (bar_N, U_curr) to (bar_{N+M}, U_future), and from (bar_N, L_curr) to (bar_{N+M}, L_future).
Forecasted channel bands are rendered in a subdued grey to distinguish them from the current solid bands. Because this method does not re‐estimate regression coefficients for future t > t_N, it serves as a quick visual heuristic of trend continuation rather than a precise statistical forecast.
MATHEMATICAL SUMMARY
Summarising all key formulas:
1. Days Since Inception
d(t_i) = max( 1, ( t_i − t0 ) / 86400000.0 )
x_i = ln( d(t_i) )
y_i = ln( P(t_i) )
2. Regression Summations (for i = 1..N)
Sx = Σ
Sy = Σ
Sxy = Σ
Sx2 = Σ
N = number of data points (or N_roll if using rolling‐window)
3. OLS Estimator
b = ( N · Sxy − Sx · Sy ) / ( N · Sx2 − (Sx)^2 )
a = ( Sy − b · Sx ) / N
4. Fair‐Value Computation
ŷ(t) = a + b · ln( d(t) )
F(t) = exp( ŷ(t) ) = exp(a) · ^b
5. Channel Bands
U(t) = F(t) · (1 + α_upper)
L(t) = F(t) · (1 − α_lower)
with α_upper = (Channel Band Upper %) / 100, α_lower = (Channel Band Lower %) / 100.
6. Forecast Projection
ΔF = F_curr − F_prev
F_future = F_curr + M · ΔF
ΔU = U_curr − U_prev
U_future = U_curr + M · ΔU
ΔL = L_curr − L_prev
L_future = L_curr + M · ΔL
IMPLEMENTATION CONSIDERATIONS
1. Time Precision
Timestamps are recorded in milliseconds. Dividing by 86400000.0 yields days with fractional precision.
For the very first bar, d(t) = 1 ensures x = ln(1) = 0, avoiding an undefined logarithm.
2. Incremental Versus Sliding Summation
All‐Time Mode: Uses persistent scalar variables (Sx, Sy, Sxy, Sx2, N). On each new bar, add the latest x and y contributions to the sums.
Rolling‐Window Mode: Employs fixed‐length arrays for {x_i} and {y_i}. On each bar, append (x_N, y_N) and update sums; if array length exceeds W, remove the oldest element and subtract its contribution from the sums. This maintains exact sums over the most recent W data points without recomputing from scratch.
3. Numerical Robustness
If the denominator N·Sx2 − (Sx)^2 equals zero (e.g., all x_i identical, as when only one day has passed), then set b = 0 and a = Sy / N. This produces a constant fair‐value F(t) = exp(a).
Enforcing d(t) ≥ 1 avoids attempts to compute ln(0).
4. Plotting Strategy
The fair‐value line F(t) is plotted on each new bar. Its color depends on whether the current price P(t) is above or below F(t): a “bullish” color (e.g., green) when P(t) ≥ F(t), and a “bearish” color (e.g., red) when P(t) < F(t).
The channel bands U(t) and L(t) are plotted in a neutral grey when enabled; otherwise they are set to “not available” (no plot).
A semi‐transparent fill is drawn between U(t) and L(t). Because the fill function is executed at global scope, it is automatically suppressed if either U(t) or L(t) is not plotted (na).
5. Forecast Line Management
Each projection line (for F, U, and L) is created via a persistent line object. On successive bars, the code updates the endpoints of the same line rather than creating a new one each time, preserving chart clarity.
If forecasting is disabled, any existing projection lines are deleted to avoid cluttering the chart.
INTERPRETATION AND APPLICATIONS
1. Trend Identification
The fair‐value curve F(t) represents the best‐fit long‐term trend under the assumption that ln(Price) scales linearly with ln(Days since inception). By capturing power‐law or exponential patterns, it can more accurately reflect underlying compounding behavior than simple linear regressions.
When actual price P(t) lies above U(t), it may be considered “overextended” relative to its long‐term trend; when price falls below L(t), it may be deemed “oversold.” These conditions can signal potential mean‐reversion or breakout opportunities.
2. Mean‐Reversion and Breakout Signals
If price re‐enters the channel after touching or slightly breaching L(t), some traders interpret this as a mean‐reversion bounce and consider initiating a long position.
Conversely, a sustained move above U(t) can indicate strong upward momentum and a possible bullish breakout. Traders often seek confirmation (e.g., price remaining above U(t) for multiple bars, rising volume, or corroborating momentum indicators) before acting.
3. Rolling Versus All‐Time Usage
All‐Time Mode: Captures the entire dataset since inception, focusing on structural, long‐term trends. It is less sensitive to short‐term noise or volatility spikes.
Rolling‐Window Mode: Restricts the regression to the most recent W bars, making the fair‐value curve more responsive to changing market regimes, sudden volatility expansions, or fundamental shifts. Traders who wish to align the model with local behaviour often choose W so that it approximates a market cycle length (e.g., 100–200 bars on a daily chart).
4. Channel Percentage Selection
A wider band (e.g., ±50 %) accommodates larger price swings, reducing the frequency of breaches but potentially delaying actionable signals.
A narrower band (e.g., ±10 %) yields more frequent “overbought/oversold” alerts but may produce more false signals during normal volatility. It is advisable to calibrate the channel width to the asset’s historical volatility regime.
5. Forecast Cautions
The short‐term projection assumes that the last single‐bar increment ΔF remains constant for M bars. In reality, trend acceleration or deceleration can occur, rendering the linear forecast inaccurate.
As such, the forecast serves as a visual guide rather than a statistically rigorous prediction. It is best used in conjunction with other momentum, volume, or volatility indicators to confirm trend continuation or reversal.
LIMITATIONS AND CONSIDERATIONS
1. Power‐Law Assumption
By fitting ln(P) against ln(d), the model posits that P(t) ≈ C · ^b. Real markets may deviate from a pure power‐law, especially around significant news events or structural regime changes. Temporary misalignment can occur.
2. Fixed Channel Width
Markets exhibit heteroskedasticity: volatility can expand or contract unpredictably. A static ±X % band does not adapt to changing volatility. During high‐volatility periods, a fixed ±50 % may prove too narrow and be breached frequently; in unusually calm periods, it may be excessively broad, masking meaningful variations.
3. Endpoint Sensitivity
Regression‐based indicators often display greater curvature near the most recent data, especially under rolling‐window mode. This can create sudden “jumps” in F(t) when new bars arrive, potentially confusing users who expect smoother behaviour.
4. Forecast Simplification
The projection does not re‐estimate regression slope b for future times. It only extends the most recent single‐bar change. Consequently, it should be regarded as an indicative extension rather than a precise forecast.
PRACTICAL IMPLEMENTATION ON TRADINGVIEW
1 Adding the Indicator
In TradingView’s “Indicators” dialog, search for Fair Value Trend Model or visit my profile, under "scripts" add it to your chart.
Add it to any chart (e.g., BTCUSD, AAPL, EURUSD) to see real‐time computation.
2. Configuring Inputs
Show Forecast Line: Toggle on or off the dashed projection of the fair‐value.
Forecast Bars: Choose M, the number of bars to extend into the future (default is often 30).
Forecast Line Colour: Select a high‐contrast colour (e.g., yellow).
Bullish FV Colour / Bearish FV Colour: Define the colour of the fair‐value line when price is above (e.g., green) or below it (e.g., red).
Show FV Channel Bands: Enable to display the grey channel bands around the fair‐value.
Channel Band Upper % / Channel Band Lower %: Set α_upper and α_lower as desired (defaults of 50 % create a ±50 % envelope).
Use Rolling Window?: Choose whether to restrict the regression to recent data.
Window Bars: If rolling mode is enabled, designate W, the number of bars to include.
3. Visual Output
The central curve F(t) appears on the price chart, coloured green when P(t) ≥ F(t) and red when P(t) < F(t).
If channel bands are enabled, the chart shows two grey lines U(t) and L(t) and a subtle shading between them.
If forecasting is active, dashed extensions of F(t), U(t), and L(t) appear, projecting forward by M bars in neutral hues.
CONCLUSION
The Fair Value Trend Model furnishes traders with a mathematically principled estimate of an asset’s equilibrium price curve by fitting a log‐linear regression to historical data. Its channel bands delineate a normal corridor of fluctuation based on fixed percentage offsets, while an optional short‐term projection offers a visual approximation of trend continuation.
By operating in log‐space, the model effectively captures exponential or power‐law growth patterns that linear methods overlook. Rolling‐window capability enables responsiveness to regime shifts, whereas all‐time mode highlights broader structural trends. Nonetheless, users should remain mindful of the model’s assumptions—particularly the power‐law form and fixed band percentages—and employ the forecast projection as a supplemental guide rather than a standalone predictor.
When combined with complementary indicators (e.g., volatility measures, momentum oscillators, volume analysis) and robust risk management, the Fair Value Trend Model can enhance market timing, mean‐reversion identification, and breakout detection across diverse trading environments.
REFERENCES
Draper, N. R., & Smith, H. (1998). Applied Regression Analysis (3rd ed.). Wiley.
Tsay, R. S. (2014). Introductory Time Series with R (2nd ed.). Springer.
Hull, J. C. (2017). Options, Futures, and Other Derivatives (10th ed.). Pearson.
These references provide background on regression, time-series analysis, and financial modeling.

Support and Resistance Logistic Regression | Flux Charts💎 GENERAL OVERVIEW
Introducing our new Logistic Regression Support / Resistance indicator! This tool leverages advanced statistical modeling "Logistic Regressions" to identify and project key price levels where the market is likely to find support or resistance. For more information about the process, please check the "HOW DOES IT WORK ?" section.
Logistic Regression Support / Resistance Features :
Intelligent S/R Identification : The indicator uses a logistic regression model to intelligently identify and plot significant support and resistance levels.
Predictive Probability : Each identified level comes with a calculated probability, indicating how likely it is to act as a true support or resistance based on historical data.
Retest & Break Labels : The indicator clearly marks on your chart when a detected support or resistance level is retested (price touches and respects the level) or broken (price decisively crosses through the level).
Alerts : Real-time alerts for support retests, resistance retests, support breaks, and resistance breaks.
Customizable : You can change support & resistance line style, width and colors.
🚩 UNIQUENESS
What makes this indicator truly unique is its application of logistic regression to the concept of support and resistance. Instead of merely identifying historical highs and lows, our indicator uses a statistical model to predict the future efficacy of these levels. It analyzes underlying market conditions (like RSI and body size at pivot formation) to assign a probability to each potential S/R zone. This predictive insight, combined with dynamic, real-time labeling of retests and breaks, provides a more robust and adaptive understanding of market structure than traditional, purely historical methods.
📌HOW DOES IT WORK ?
The Logistic Regression Support / Resistance indicator operates in several key steps:
First, it identifies significant pivot highs and lows on the chart based on a user-defined "Pivot Length." These pivots are potential areas of support or resistance.
For each detected pivot, the indicator extracts relevant market data at that specific point, including the RSI (Relative Strength Index) and the Body Size (the absolute difference between the open and close price of the candle). These serve as input features for the model.
The core of the indicator lies in its logistic regression model. This model is continuously trained on past pivot data and their subsequent behavior (i.e., whether they were "respected" as support/resistance multiple times). It learns the relationship between the extracted features (RSI, Body Size) and the likelihood of a pivot becoming a significant S/R level.
When a new pivot is identified, the model uses its learned insights to calculate a prediction value—a probability (from 0 to 1) that this specific pivot will act as a strong support or resistance.
If the calculated probability exceeds a user-defined "Probability Threshold," the pivot is designated a "Regression Pivot" and drawn on the chart as a support or resistance line. The indicator then actively tracks how price interacts with these levels, displaying "R" labels for retests when the price bounces off the level and "B" labels for breaks when the price closes beyond it.
⚙️ SETTINGS
1. General Configuration
Pivot Length: This setting defines the number of bars used to determine a significant high or low for pivot detection.
Target Respects: This input specifies how many times a level must be "respected" by price action for it to be considered a strong support or resistance level by the underlying model.
Probability Threshold: This is the minimum probability output from the logistic regression model for a detected pivot to be considered a valid support or resistance level and be plotted on the chart.
2. Style
Show Prediction Labels: Enable or disable labels that display the calculated probability of a newly identified regression S/R level.
Show Retests: Toggle the visibility of "R" labels on the chart, which mark instances where price has retested a support or resistance level.
Show Breaks: Toggle the visibility of "B" labels on the chart, which mark instances where price has broken through a support or resistance level.
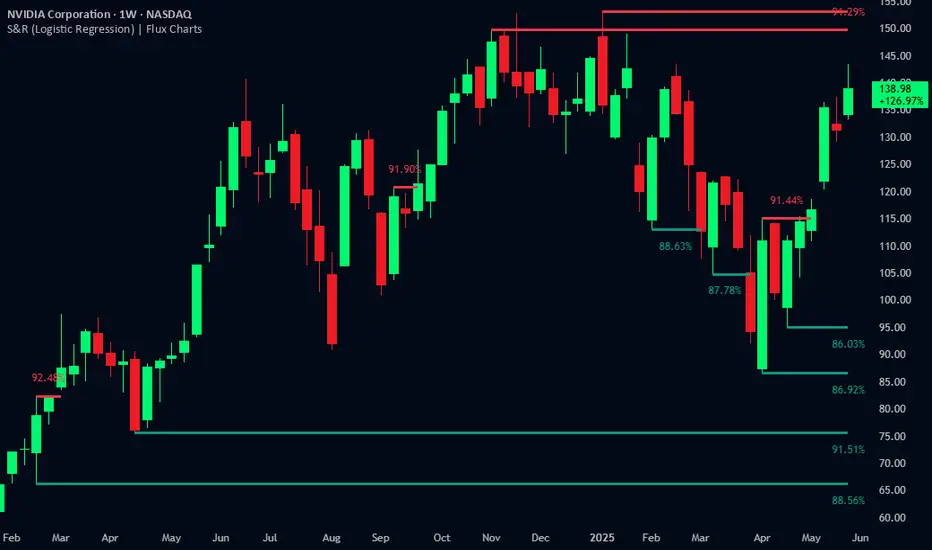
Weighted Regression Bands (Zeiierman)█ Overview
Weighted Regression Bands is a precision-engineered trend and volatility tool designed to adapt to the real market structure instead of reacting to price noise.
This indicator analyzes Weighted High/Low medians and applies user-selectable smoothing methods — including Kalman Filtering, ALMA, and custom Linear Regression — to generate a Fair Value line. Around this, it constructs dynamic standard deviation bands that adapt in real-time to market volatility.
The result is a visually clean and structurally intelligent trend framework suitable for breakout traders, mean reversion strategies, and trend-driven analysis.
█ How It Works
⚪ Structural High/Low Analysis
At the heart of this indicator is a custom high/low weighting system. Instead of using just the raw high or low values, it calculates a midline = (high + low) / 2, then applies one of three weighting methods to determine which price zones matter most.
Users can select the method using the “Weighted HL Method” setting:
Simple
Selects the single most dominant median (highest or lowest) in the lookback window. Ideal for fast, reactive signals.
Advanced
Ranks each bar based on a composite score: median × range × recency. This method highlights structurally meaningful bars that had both volatility and recency. A built-in Kalman filter is applied for extra stability.
Smooth
Blends multiple bars into a single weighted average using smoothed decay and range. This provides the softest and most stable structural response.
⚪ Smoothing Methods (ALMA / Linear Regression)
ALMA provides responsive, low-lag smoothing for fast trend reading.
Linear Regression projects the Fair Value forward, ideal for trend modeling.
⚪ Kalman Smoothing Filter
Before trend calculations, the indicator applies an optional Kalman-style smoothing filter. This helps:
Reduce choppy false shifts in trend,
Retain signal clarity during volatile periods,
Provide stability for long-term setups.
⚪ Deviation Bands (Dynamic Volatility Envelopes)
The indicator builds ±1, ±2, and ±3 standard deviation bands around the fair value line:
Calculated from the standard deviation of price,
Bands expand and contract based on recent volatility,
Visualizes potential overbought/oversold or trending conditions.
█ How to Use
⚪ Trend Trading & Filtering
Use the Fair Value line to identify the dominant direction.
Only trade in the direction of the slope for higher probability setups.
⚪ Volatility-Based Entries
Watch for price reaching outer bands (+2σ, +3σ) for possible exhaustion.
Mean reversion entries become higher quality when far from Fair Value.
█ Settings
Length – Lookback for Weighted HL and trend smoothing
Deviation Multiplier – Controls how wide the bands are from the fair value line
Method – Choose between ALMA or Linear Regression smoothing
Smoothing – Strength of Kalman Filter (1 = none, <1 = stronger smoothing)
-----------------
Disclaimer
The content provided in my scripts, indicators, ideas, algorithms, and systems is for educational and informational purposes only. It does not constitute financial advice, investment recommendations, or a solicitation to buy or sell any financial instruments. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
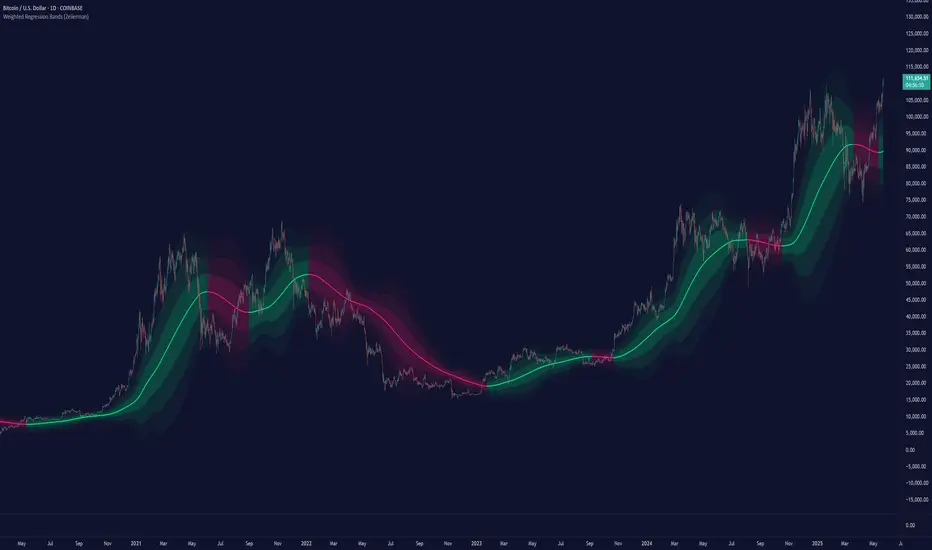
Bitcoin Power Law OscillatorThis is the oscillator version of the script. The main body of the script can be found here.
Understanding the Bitcoin Power Law Model
Also called the Long-Term Bitcoin Power Law Model. The Bitcoin Power Law model tries to capture and predict Bitcoin's price growth over time. It assumes that Bitcoin's price follows an exponential growth pattern, where the price increases over time according to a mathematical relationship.
By fitting a power law to historical data, the model creates a trend line that represents this growth. It then generates additional parallel lines (support and resistance lines) to show potential price boundaries, helping to visualize where Bitcoin’s price could move within certain ranges.
In simple terms, the model helps us understand Bitcoin's general growth trajectory and provides a framework to visualize how its price could behave over the long term.
The Bitcoin Power Law has the following function:
Power Law = 10^(a + b * log10(d))
Consisting of the following parameters:
a: Power Law Intercept (default: -17.668).
b: Power Law Slope (default: 5.926).
d: Number of days since a reference point(calculated by counting bars from the reference point with an offset).
Explanation of the a and b parameters:
Roughly explained, the optimal values for the a and b parameters are determined through a process of linear regression on a log-log scale (after applying a logarithmic transformation to both the x and y axes). On this log-log scale, the power law relationship becomes linear, making it possible to apply linear regression. The best fit for the regression is then evaluated using metrics like the R-squared value, residual error analysis, and visual inspection. This process can be quite complex and is beyond the scope of this post.
Applying vertical shifts to generate the other lines:
Once the initial power-law is created, additional lines are generated by applying a vertical shift. This shift is achieved by adding a specific number of days (or years in case of this script) to the d-parameter. This creates new lines perfectly parallel to the initial power law with an added vertical shift, maintaining the same slope and intercept.
In the case of this script, shifts are made by adding +365 days, +2 * 365 days, +3 * 365 days, +4 * 365 days, and +5 * 365 days, effectively introducing one to five years of shifts. This results in a total of six Power Law lines, as outlined below (From lowest to highest):
Base Power Law Line (no shift)
1-year shifted line
2-year shifted line
3-year shifted line
4-year shifted line
5-year shifted line
The six power law lines:
Bitcoin Power Law Oscillator
This publication also includes the oscillator version of the Bitcoin Power Law. This version applies a logarithmic transformation to the price, Base Power Law Line, and 5-year shifted line using the formula: log10(x) .
The log-transformed price is then normalized using min-max normalization relative to the log-transformed Base Power Law Line and 5-year shifted line with the formula:
normalized price = log(close) - log(Base Power Law Line) / log(5-year shifted line) - log(Base Power Law Line)
Finally, the normalized price was multiplied by 5 to map its value between 0 and 5, aligning with the shifted lines.
Interpretation of the Bitcoin Power Law Model:
The shifted Power Law lines provide a framework for predicting Bitcoin's future price movements based on historical trends. These lines are created by applying a vertical shift to the initial Power Law line, with each shifted line representing a future time frame (e.g., 1 year, 2 years, 3 years, etc.).
By analyzing these shifted lines, users can make predictions about minimum price levels at specific future dates. For example, the 5-year shifted line will act as the main support level for Bitcoin’s price in 5 years, meaning that Bitcoin’s price should not fall below this line, ensuring that Bitcoin will be valued at least at this level by that time. Similarly, the 2-year shifted line will serve as the support line for Bitcoin's price in 2 years, establishing that the price should not drop below this line within that time frame.
On the other hand, the 5-year shifted line also functions as an absolute resistance , meaning Bitcoin's price will not exceed this line prior to the 5-year mark. This provides a prediction that Bitcoin cannot reach certain price levels before a specific date. For example, the price of Bitcoin is unlikely to reach $100,000 before 2021, and it will not exceed this price before the 5-year shifted line becomes relevant. After 2028, however, the price is predicted to never fall below $100,000, thanks to the support established by the shifted lines.
In essence, the shifted Power Law lines offer a way to predict both the minimum price levels that Bitcoin will hit by certain dates and the earliest dates by which certain price points will be reached. These lines help frame Bitcoin's potential future price range, offering insight into long-term price behavior and providing a guide for investors and analysts. Lets examine some examples:
Example 1:
In Example 1 it can be seen that point A on the 5-year shifted line acts as major resistance . Also it can be seen that 5 years later this price level now corresponds to the Base Power Law Line and acts as a major support at point B(Note: Vertical yearly grid lines have been added for this purpose👍).
Example 2:
In Example 2, the price level at point C on the 3-year shifted line becomes a major support three years later at point D, now aligning with the Base Power Law Line.
Finally, let's explore some future price predictions, as this script provides projections on the weekly timeframe :
Example 3:
In Example 3, the Bitcoin Power Law indicates that Bitcoin's price cannot surpass approximately $808K before 2030 as can be seen at point E, while also ensuring it will be at least $224K by then (point F).

Bitcoin Power LawThis is the main body version of the script. The Oscillator version can be found here.
Understanding the Bitcoin Power Law Model
Also called the Long-Term Bitcoin Power Law Model. The Bitcoin Power Law model tries to capture and predict Bitcoin's price growth over time. It assumes that Bitcoin's price follows an exponential growth pattern, where the price increases over time according to a mathematical relationship.
By fitting a power law to historical data, the model creates a trend line that represents this growth. It then generates additional parallel lines (support and resistance lines) to show potential price boundaries, helping to visualize where Bitcoin’s price could move within certain ranges.
In simple terms, the model helps us understand Bitcoin's general growth trajectory and provides a framework to visualize how its price could behave over the long term.
The Bitcoin Power Law has the following function:
Power Law = 10^(a + b * log10(d))
Consisting of the following parameters:
a: Power Law Intercept (default: -17.668).
b: Power Law Slope (default: 5.926).
d: Number of days since a reference point(calculated by counting bars from the reference point with an offset).
Explanation of the a and b parameters:
Roughly explained, the optimal values for the a and b parameters are determined through a process of linear regression on a log-log scale (after applying a logarithmic transformation to both the x and y axes). On this log-log scale, the power law relationship becomes linear, making it possible to apply linear regression. The best fit for the regression is then evaluated using metrics like the R-squared value, residual error analysis, and visual inspection. This process can be quite complex and is beyond the scope of this post.
Applying vertical shifts to generate the other lines:
Once the initial power-law is created, additional lines are generated by applying a vertical shift. This shift is achieved by adding a specific number of days (or years in case of this script) to the d-parameter. This creates new lines perfectly parallel to the initial power law with an added vertical shift, maintaining the same slope and intercept.
In the case of this script, shifts are made by adding +365 days, +2 * 365 days, +3 * 365 days, +4 * 365 days, and +5 * 365 days, effectively introducing one to five years of shifts. This results in a total of six Power Law lines, as outlined below (From lowest to highest):
Base Power Law Line (no shift)
1-year shifted line
2-year shifted line
3-year shifted line
4-year shifted line
5-year shifted line
The six power law lines:
Bitcoin Power Law Oscillator
This publication also includes the oscillator version of the Bitcoin Power Law. This version applies a logarithmic transformation to the price, Base Power Law Line, and 5-year shifted line using the formula: log10(x) .
The log-transformed price is then normalized using min-max normalization relative to the log-transformed Base Power Law Line and 5-year shifted line with the formula:
normalized price = log(close) - log(Base Power Law Line) / log(5-year shifted line) - log(Base Power Law Line)
Finally, the normalized price was multiplied by 5 to map its value between 0 and 5, aligning with the shifted lines.
Interpretation of the Bitcoin Power Law Model:
The shifted Power Law lines provide a framework for predicting Bitcoin's future price movements based on historical trends. These lines are created by applying a vertical shift to the initial Power Law line, with each shifted line representing a future time frame (e.g., 1 year, 2 years, 3 years, etc.).
By analyzing these shifted lines, users can make predictions about minimum price levels at specific future dates. For example, the 5-year shifted line will act as the main support level for Bitcoin’s price in 5 years, meaning that Bitcoin’s price should not fall below this line, ensuring that Bitcoin will be valued at least at this level by that time. Similarly, the 2-year shifted line will serve as the support line for Bitcoin's price in 2 years, establishing that the price should not drop below this line within that time frame.
On the other hand, the 5-year shifted line also functions as an absolute resistance , meaning Bitcoin's price will not exceed this line prior to the 5-year mark. This provides a prediction that Bitcoin cannot reach certain price levels before a specific date. For example, the price of Bitcoin is unlikely to reach $100,000 before 2021, and it will not exceed this price before the 5-year shifted line becomes relevant. After 2028, however, the price is predicted to never fall below $100,000, thanks to the support established by the shifted lines.
In essence, the shifted Power Law lines offer a way to predict both the minimum price levels that Bitcoin will hit by certain dates and the earliest dates by which certain price points will be reached. These lines help frame Bitcoin's potential future price range, offering insight into long-term price behavior and providing a guide for investors and analysts. Lets examine some examples:
Example 1:
In Example 1 it can be seen that point A on the 5-year shifted line acts as major resistance . Also it can be seen that 5 years later this price level now corresponds to the Base Power Law Line and acts as a major support at point B (Note: Vertical yearly grid lines have been added for this purpose👍).
Example 2:
In Example 2, the price level at point C on the 3-year shifted line becomes a major support three years later at point D, now aligning with the Base Power Law Line.
Finally, let's explore some future price predictions, as this script provides projections on the weekly timeframe :
Example 3:
In Example 3, the Bitcoin Power Law indicates that Bitcoin's price cannot surpass approximately $808K before 2030 as can be seen at point E, while also ensuring it will be at least $224K by then (point F).

PolyBand Convergence System (PBCS)PolyBand Convergence System (PBCS)
The PolyBand Convergence System (PBCS) is an advanced technical analysis indicator that combines multiple polynomial regressions with statistical bands to identify trend strength and potential reversal zones.
Key Features
Multi-Degree Polynomial Analysis: Combines 1st, 2nd, 3rd, and 4th degree polynomial regressions into a composite regression line
Adaptive Statistical Bands: Uses percentile-based bands enhanced with standard deviation multipliers
Asymmetric Volatility Measurement: Separately calculates upside and downside volatility for more accurate band placement
Smart Trend Detection: Identifies bullish, bearish, or neutral market conditions based on price position relative to bands
How It Works
PBCS creates a composite regression line from multiple polynomial fits to better capture the underlying price structure. This line is then surrounded by adaptive bands that represent statistical thresholds for price movement. When price breaks above the upper band, a bullish trend is signaled; when it breaks below the lower band, a bearish trend is indicated.
Customization Options
Regression Settings: Adjust source data, lookback period, and smoothing parameters
Percentile Controls: Fine-tune the statistical thresholds for upper and lower bands
Volatility Sensitivity: Modify standard deviation multipliers to control band width
Visual Preferences: Choose from multiple color schemes to match your trading platform
Disclaimer
This indicator is provided for educational and informational purposes only and does not constitute investment advice. Trading involves risk and may result in financial loss. Always perform your own research and consult with a qualified financial advisor before making any trading decisions.

Kernel Regression Bands SuiteMulti-Kernel Regression Bands
A versatile indicator that applies kernel regression smoothing to price data, then dynamically calculates upper and lower bands using a wide variety of deviation methods. This tool is designed to help traders identify trend direction, volatility, and potential reversal zones with customizable visual styles.
Key Features
Multiple Kernel Types: Choose from 17+ kernel regression styles (Gaussian, Laplace, Epanechnikov, etc.) for smoothing.
Flexible Band Calculation: Select from 12+ deviation types including Standard Deviation, Mean/Median Absolute Deviation, Exponential, True Range, Hull, Parabolic SAR, Quantile, and more.
Adaptive Bands: Bands are calculated around the kernel regression line, with a user-defined multiplier.
Signal Logic: Trend state is determined by crossovers/crossunders of price and bands, coloring the regression line and band fills accordingly.
Custom Color Modes: Six unique color palettes for visual clarity and personal preference.
Highly Customizable Inputs: Adjust kernel type, lookback, deviation method, band source, and more.
How to Use
Trend Identification: The regression line changes color based on the detected trend (up/down)
Volatility Zones: Bands expand/contract with volatility, helping spot breakouts or mean-reversion opportunities.
Visual Styling: Use color modes to match your chart theme or highlight specific market states.
Credits:
Kernel regression logic adapted from:
ChartPrime | Multi-Kernel-Regression-ChartPrime (Link in the script)
Disclaimer
This script is for educational and informational purposes only. Not financial advice. Use at your own risk.

ConeCastConeCast is a forward-looking projection indicator that visualizes a future price range (or "cone") based on recent trend momentum and adaptive volatility. Unlike lagging bands or reactive channels, this tool plots a predictive zone 3–50 bars ahead, allowing traders to anticipate potential price behavior rather than merely react to it.
How It Works
The core of ConeCast is a dynamic trend-slope engine derived from a Linear Regression line fitted over a user-defined lookback window. The slope of this trend is projected forward, and the cone’s width adapts based on real-time market volatility. In calm markets, the cone is narrow and focused. In volatile regimes, it expands proportionally, using an ATR-based % of price to scale.
Key Features
📈 Predictive Cone Zone: Visualizes a forward range using trend slope × volatility width.
🔄 Auto-Adaptive Volatility Scaling: Expands or contracts based on market quiet/chaotic states.
📊 Regime Detection: Identifies Bull, Bear, or Neutral states using a tunable slope threshold.
🧭 Multi-Timeframe Compatible: Slope and volatility can be calculated from higher timeframes.
🔔 Smart Alerts: Detects price entering the cone, and signals trend regime changes in real time.
🖼️ Clean Visual Output: Optionally includes outer cones, trend-trail marker, and dashboard label.
How to Use It
Use on 15m–4H charts for best forward visibility.
Look for price entering the cone as a potential trend continuation setup.
Monitor regime changes and volatility expansion to filter choppy market zones.
Tune the slope sensitivity and ATR multiplier to match your symbol's behavior.
Use outer cones to anticipate aggressive swings and wick traps.
What Makes It Unique
ConeCast doesn’t follow price — it predicts a possible future price envelope using trend + volatility math, without relying on lagging indicators or repainting logic. It's a hybrid of regression-based forecasting and dynamic risk zoning, designed for swing traders, scalpers, and algo developers alike.
Limitations
ConeCast projects based on current trend and volatility — it does not "know" future price. Like all projection tools, accuracy depends on trend persistence and market conditions. Use this in combination with confirmation signals and risk management.

Linear Regression Slope The Linear Regression Slope provides a quantitative measure of trend direction. It fits a linear regression line to the past N closing prices and calculates the slope, representing the average rate of price change per bar.
To ensure comparability across assets and timeframes, the slope is normalized by the ATR over a shorter window. This produces a volatility-adjusted measure which allows for the slope to be interpreted relative to typical price fluctuations.
Mathematically, the slope is derived by minimizing the sum of squared deviations between actual prices and the fitted regression line. A positive normalized slope indicate upwards movement; a negative slope indicate downwards movement. Persistent values near zero could indicate an absence of clear trend, with price dominated by short-term fluctuations or noise.
The definition of a trend depends on the period of observation. The lookback setting should be set based on to the desired timeframe. Shorter lookbacks will respond faster to recent changes but may be more sensitive to noise, while longer lookbacks will emphasize broader structures.
While effective at quantifying existing trends, this method is not predictive. Sudden regime changes, volatility shocks, and non-linear dynamics can all cause rapid slope reversals. Therefore, it is best applied as part of a broader analytical framework.
In summary, the Linear Regression Slope quantifies price direction and serves as a measurable supplement to the visual assessment of trends on price charts.
Additional Features:
Option to display or hide the normalized slope line.
Option to enable background coloring when the slope is above or below zero.