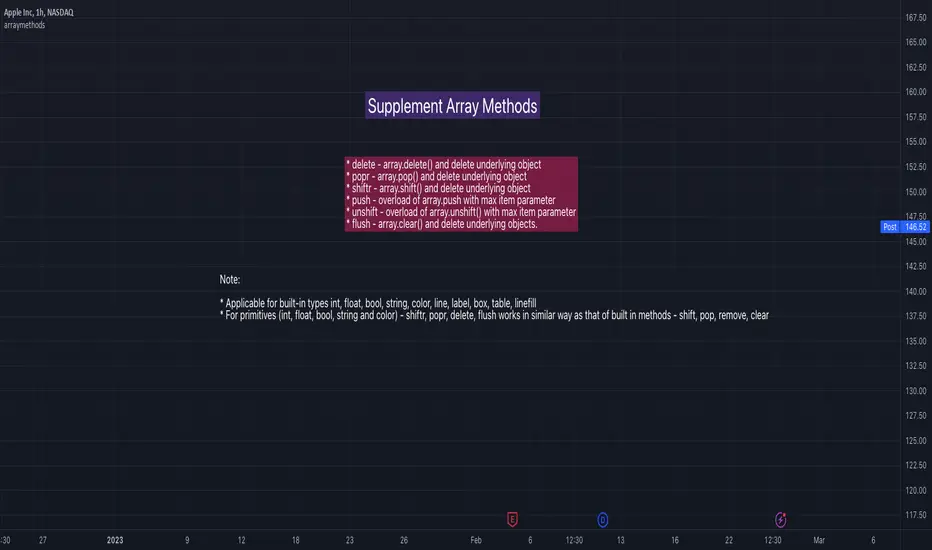
arraymethodsLibrary "arraymethods"
Supplementary array methods.
delete(arr, index)
remove int object from array of integers at specific index
Parameters:
arr : int array
index : index at which int object need to be removed
Returns: void
delete(arr, index)
remove float object from array of float at specific index
Parameters:
arr : float array
index : index at which float object need to be removed
Returns: float
delete(arr, index)
remove bool object from array of bool at specific index
Parameters:
arr : bool array
index : index at which bool object need to be removed
Returns: bool
delete(arr, index)
remove string object from array of string at specific index
Parameters:
arr : string array
index : index at which string object need to be removed
Returns: string
delete(arr, index)
remove color object from array of color at specific index
Parameters:
arr : color array
index : index at which color object need to be removed
Returns: color
delete(arr, index)
remove line object from array of lines at specific index and deletes the line
Parameters:
arr : line array
index : index at which line object need to be removed and deleted
Returns: void
delete(arr, index)
remove label object from array of labels at specific index and deletes the label
Parameters:
arr : label array
index : index at which label object need to be removed and deleted
Returns: void
delete(arr, index)
remove box object from array of boxes at specific index and deletes the box
Parameters:
arr : box array
index : index at which box object need to be removed and deleted
Returns: void
delete(arr, index)
remove table object from array of tables at specific index and deletes the table
Parameters:
arr : table array
index : index at which table object need to be removed and deleted
Returns: void
delete(arr, index)
remove linefill object from array of linefills at specific index and deletes the linefill
Parameters:
arr : linefill array
index : index at which linefill object need to be removed and deleted
Returns: void
popr(arr)
remove last int object from array
Parameters:
arr : int array
Returns: int
popr(arr)
remove last float object from array
Parameters:
arr : float array
Returns: float
popr(arr)
remove last bool object from array
Parameters:
arr : bool array
Returns: bool
popr(arr)
remove last string object from array
Parameters:
arr : string array
Returns: string
popr(arr)
remove last color object from array
Parameters:
arr : color array
Returns: color
popr(arr)
remove and delete last line object from array
Parameters:
arr : line array
Returns: void
popr(arr)
remove and delete last label object from array
Parameters:
arr : label array
Returns: void
popr(arr)
remove and delete last box object from array
Parameters:
arr : box array
Returns: void
popr(arr)
remove and delete last table object from array
Parameters:
arr : table array
Returns: void
popr(arr)
remove and delete last linefill object from array
Parameters:
arr : linefill array
Returns: void
shiftr(arr)
remove first int object from array
Parameters:
arr : int array
Returns: int
shiftr(arr)
remove first float object from array
Parameters:
arr : float array
Returns: float
shiftr(arr)
remove first bool object from array
Parameters:
arr : bool array
Returns: bool
shiftr(arr)
remove first string object from array
Parameters:
arr : string array
Returns: string
shiftr(arr)
remove first color object from array
Parameters:
arr : color array
Returns: color
shiftr(arr)
remove and delete first line object from array
Parameters:
arr : line array
Returns: void
shiftr(arr)
remove and delete first label object from array
Parameters:
arr : label array
Returns: void
shiftr(arr)
remove and delete first box object from array
Parameters:
arr : box array
Returns: void
shiftr(arr)
remove and delete first table object from array
Parameters:
arr : table array
Returns: void
shiftr(arr)
remove and delete first linefill object from array
Parameters:
arr : linefill array
Returns: void
push(arr, val, maxItems)
add int to the end of an array with max items cap. Objects are removed from start to maintain max items cap
Parameters:
arr : int array
val : int object to be pushed
maxItems : max number of items array can hold
Returns: int
push(arr, val, maxItems)
add float to the end of an array with max items cap. Objects are removed from start to maintain max items cap
Parameters:
arr : float array
val : float object to be pushed
maxItems : max number of items array can hold
Returns: float
push(arr, val, maxItems)
add bool to the end of an array with max items cap. Objects are removed from start to maintain max items cap
Parameters:
arr : bool array
val : bool object to be pushed
maxItems : max number of items array can hold
Returns: bool
push(arr, val, maxItems)
add string to the end of an array with max items cap. Objects are removed from start to maintain max items cap
Parameters:
arr : string array
val : string object to be pushed
maxItems : max number of items array can hold
Returns: string
push(arr, val, maxItems)
add color to the end of an array with max items cap. Objects are removed from start to maintain max items cap
Parameters:
arr : color array
val : color object to be pushed
maxItems : max number of items array can hold
Returns: color
push(arr, val, maxItems)
add line to the end of an array with max items cap. Objects are removed and deleted from start to maintain max items cap
Parameters:
arr : line array
val : line object to be pushed
maxItems : max number of items array can hold
Returns: line
push(arr, val, maxItems)
add label to the end of an array with max items cap. Objects are removed and deleted from start to maintain max items cap
Parameters:
arr : label array
val : label object to be pushed
maxItems : max number of items array can hold
Returns: label
push(arr, val, maxItems)
add box to the end of an array with max items cap. Objects are removed and deleted from start to maintain max items cap
Parameters:
arr : box array
val : box object to be pushed
maxItems : max number of items array can hold
Returns: box
push(arr, val, maxItems)
add table to the end of an array with max items cap. Objects are removed and deleted from start to maintain max items cap
Parameters:
arr : table array
val : table object to be pushed
maxItems : max number of items array can hold
Returns: table
push(arr, val, maxItems)
add linefill to the end of an array with max items cap. Objects are removed and deleted from start to maintain max items cap
Parameters:
arr : linefill array
val : linefill object to be pushed
maxItems : max number of items array can hold
Returns: linefill
unshift(arr, val, maxItems)
add int to the beginning of an array with max items cap. Objects are removed from end to maintain max items cap
Parameters:
arr : int array
val : int object to be unshift
maxItems : max number of items array can hold
Returns: int
unshift(arr, val, maxItems)
add float to the beginning of an array with max items cap. Objects are removed from end to maintain max items cap
Parameters:
arr : float array
val : float object to be unshift
maxItems : max number of items array can hold
Returns: float
unshift(arr, val, maxItems)
add bool to the beginning of an array with max items cap. Objects are removed from end to maintain max items cap
Parameters:
arr : bool array
val : bool object to be unshift
maxItems : max number of items array can hold
Returns: bool
unshift(arr, val, maxItems)
add string to the beginning of an array with max items cap. Objects are removed from end to maintain max items cap
Parameters:
arr : string array
val : string object to be unshift
maxItems : max number of items array can hold
Returns: string
unshift(arr, val, maxItems)
add color to the beginning of an array with max items cap. Objects are removed from end to maintain max items cap
Parameters:
arr : color array
val : color object to be unshift
maxItems : max number of items array can hold
Returns: color
unshift(arr, val, maxItems)
add line to the beginning of an array with max items cap. Objects are removed and deleted from end to maintain max items cap
Parameters:
arr : line array
val : line object to be unshift
maxItems : max number of items array can hold
Returns: line
unshift(arr, val, maxItems)
add label to the beginning of an array with max items cap. Objects are removed and deleted from end to maintain max items cap
Parameters:
arr : label array
val : label object to be unshift
maxItems : max number of items array can hold
Returns: label
unshift(arr, val, maxItems)
add box to the beginning of an array with max items cap. Objects are removed and deleted from end to maintain max items cap
Parameters:
arr : box array
val : box object to be unshift
maxItems : max number of items array can hold
Returns: box
unshift(arr, val, maxItems)
add table to the beginning of an array with max items cap. Objects are removed and deleted from end to maintain max items cap
Parameters:
arr : table array
val : table object to be unshift
maxItems : max number of items array can hold
Returns: table
unshift(arr, val, maxItems)
add linefill to the beginning of an array with max items cap. Objects are removed and deleted from end to maintain max items cap
Parameters:
arr : linefill array
val : linefill object to be unshift
maxItems : max number of items array can hold
Returns: linefill
flush(arr)
remove all int objects in an array
Parameters:
arr : int array
Returns: int
flush(arr)
remove all float objects in an array
Parameters:
arr : float array
Returns: float
flush(arr)
remove all bool objects in an array
Parameters:
arr : bool array
Returns: bool
flush(arr)
remove all string objects in an array
Parameters:
arr : string array
Returns: string
flush(arr)
remove all color objects in an array
Parameters:
arr : color array
Returns: color
flush(arr)
remove and delete all line objects in an array
Parameters:
arr : line array
Returns: line
flush(arr)
remove and delete all label objects in an array
Parameters:
arr : label array
Returns: label
flush(arr)
remove and delete all box objects in an array
Parameters:
arr : box array
Returns: box
flush(arr)
remove and delete all table objects in an array
Parameters:
arr : table array
Returns: table
flush(arr)
remove and delete all linefill objects in an array
Parameters:
arr : linefill array
Returns: linefill
Trendoscope
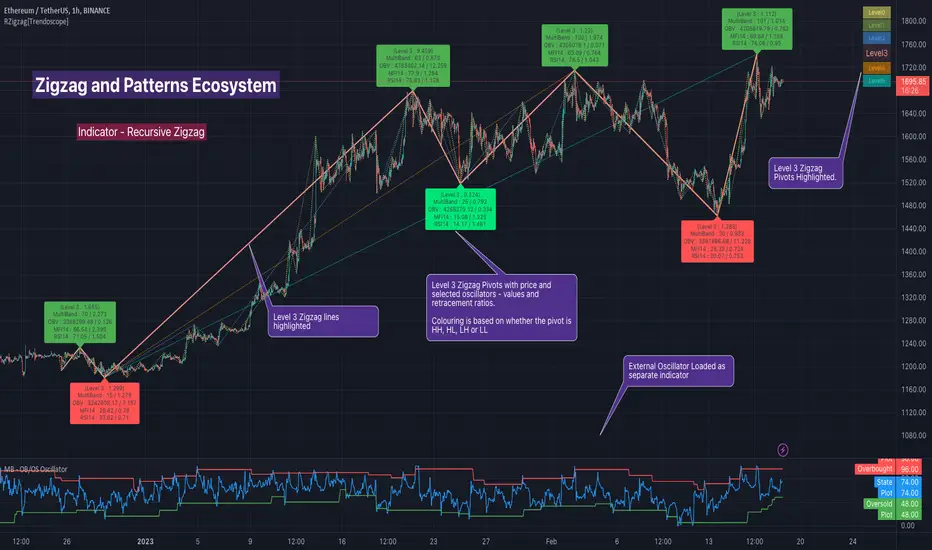
Recursive Zigzag [Trendoscope]Here is an another outcome of Object Oriented Zigzag and Pattern Ecosystem of Libraries.
We already have another implementation of recursive zigzag which makes use of earlier library rzigzag . Here in this example, we make use of similar logic but leverage the new type and method based Zigzag system libraries to derive the indicator.
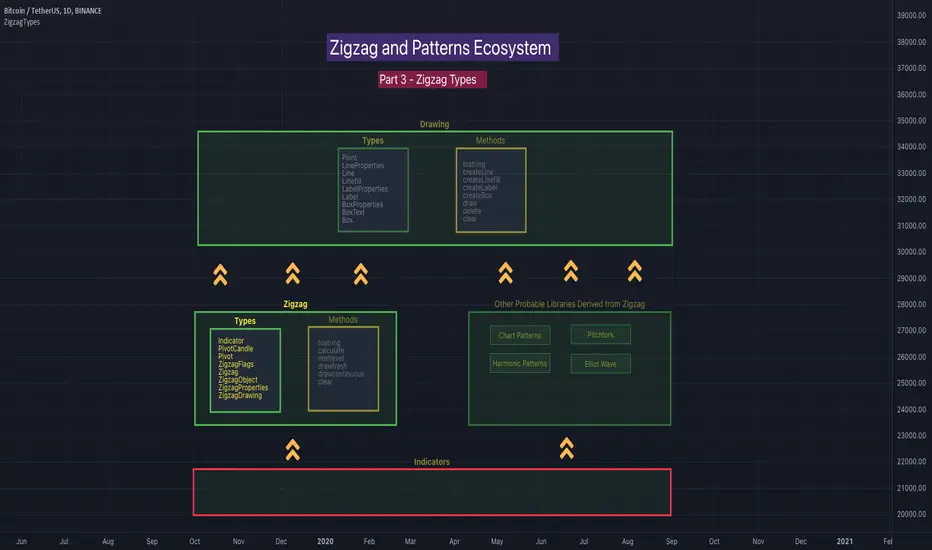
🎲 Design Overview
Similar to Recursive Auto Pitchfork, here too the indicator code is around 50 lines. Whereas most of the heavy lifting is done by the libraries.
🎲 Base Libraries
Base libraries are those which does not have any dependency. They form basic structures which are later used in other libraries. These libraries need to be crafted carefully so that minimal updates are done later on. Any updates on these libraries will impact all the dependent libraries and scripts.
🎯 Drawing
DrawingTypes - Defines basic drawing types Point, Line, Label, Box, Linefill and related property types.
DrawingMethods - All the methods or functionality surrounding Basic types are defined here.
🎲 Layer 1 Libraries
These are the libraries which has direct dependency on base libraries.
🎯 Zigzag
ZigzagTypes - Types required for defining Zigzag and Divergence
ZigzagMethods - Methods associated with Zigzag Type definitions.
🎲Indicator
Indicator draws zigzags based on given length. And then recursively derives next level zigzags based on previous levels. As per the utility, indicator is useful in several ways
Visualising price structure based on zigzag pivots - which in turn can help visualise patterns.
Ability to add any oscillator makes it easy to spot divergences with choice of indicators.
Programmers can use the derived values to build complex algorithms such as automatic pattern recognition.
🎯 Settings
Settings are explained via tooltips. These are very much straight forward and directly related to zigzag, oscillators and divergence.
Recursive Auto-Pitchfork [Trendoscope]"Say Hi" to object oriented programming with Pinescript using types and methods. This is the beginning of new era of Pinescript where we are moving from isolated scripts containing indicator and strategies to whole ecosystem of Object Oriented Programming with libraries of highly reusable components. Those who are familiar with programming would have already realised how big these improvements are and what it brings to the table.
With this script, I am not just providing an indicator for traders but also an introduction for programmers on how to design and build object oriented components in Pinescript using types and methods. Big thanks to Tradingview and Pine development team for making this happen. We look forward for many such gifts in the future :)
🎲 Architecture
As mentioned before, we are not just building an indicator here. But, an ecosystem of components. Using Types and Methods we can visualise libraries as Classes. Thus, we can build an ecosystem of libraries in layered approach to enhance effective code reusability.
Generic architecture can be visualised as below
Coming to the specific case of Auto Pitchfork indicator, the indicator code is less than 50 lines for logic and around 100 lines of inputs. But, most of the heavy-lifting is done by the libraries underneath. Here is a snapshot of related libraries and how they are connected.
All libraries are divided into two portions.
Types - Contains only type definitions
Methods - Contains only method definitions related to the types defined in the Types library
Together, these libraries can be visualised as Class. Methods are defined in such a way all exported methods are related to Types and no other functions or features are defined. If we need further functionality which does not depend on the types, we need to do this via some other library and use them here. Similarly, we should not define any methods related to these types in other libraries.
Reason for splitting the libraries to types and methods is to enable updating methods without disturbing types. Since libraries create interdependencies due to versioning, it is best if we do less updates on the type definitions. Splitting the two enables adding more features while keeping the type definition version intact.
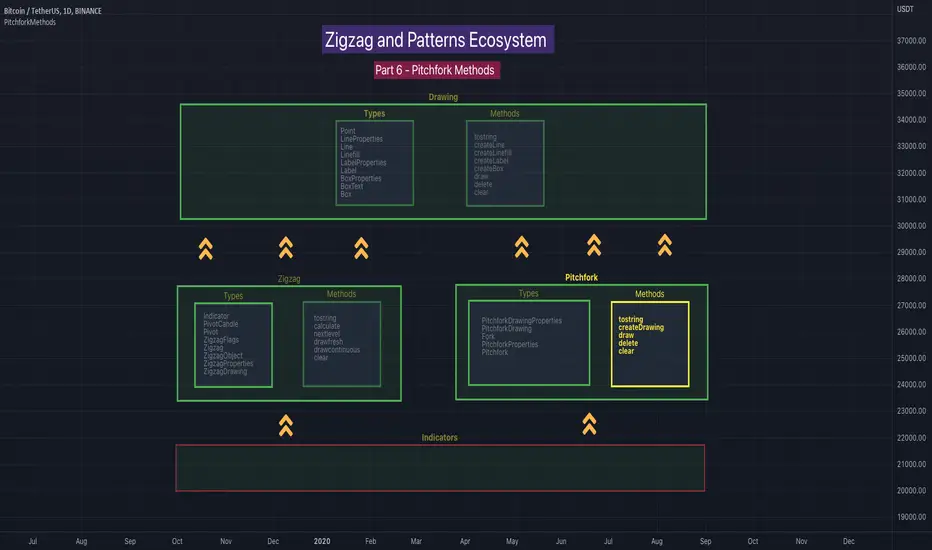
🎲 Base Libraries
Base libraries are those which does not have any dependency. They form basic structures which are later used in other libraries. These libraries need to be crafted carefully so that minimal updates are done later on. Any updates on these libraries will impact all the dependent libraries and scripts.
🎯 Drawing
DrawingTypes - Defines basic drawing types Point, Line, Label, Box, Linefill and related property types.
DrawingMethods - All the methods or functionality surrounding Basic types are defined here.
🎲 Layer 1 Libraries
These are the libraries which has direct dependency on base libraries.
🎯 Zigzag
ZigzagTypes - Types required for defining Zigzag and Divergence
ZigzagMethods - Methods associated with Zigzag Type definitions.
🎯Pitchfork
PitchforkTypes - Basic and Drawing Types for Pitchfork objects
PitchforkMethods - Methods associated with Pitchfork type definitions
🎲 Indicator and Settings
Indicator draws pitchfork based on recursive zigzag configurations. Recursive zigzag is derived with following logic:
Base level zigzag is calculated with regular zigzag algorithm with given length and depth
Next level zigzag is calculated based on base zigzag. And we recursively calculate higher level zigzags until we are left with 4 or less pivots or when no further reduction is possible
On every level of zigzag, we then check the last 3 pivots and draw pitchfork based on the retracement ratio.
Indicator settings are summarised in the tooltips and are as below.
Finally, big thanks to my partner @CryptoArch_ for bringing up the topic of pitchfork for our next development.
PitchforkMethodsLibrary "PitchforkMethods"
Methods associated with Pitchfork and Pitchfork Drawing. Depends on the library PitchforkTypes for Pitchfork/PitchforkDrawing objects which in turn use DrawingTypes for basic objects Point/Line/LineProperties. Also depends on DrawingMethods for related methods
tostring(this)
Converts PitchforkTypes/Fork object to string representation
Parameters:
this : PitchforkTypes/Fork object
Returns: string representation of PitchforkTypes/Fork
tostring(this)
Converts Array of PitchforkTypes/Fork object to string representation
Parameters:
this : Array of PitchforkTypes/Fork object
Returns: string representation of PitchforkTypes/Fork array
tostring(this, sortKeys, sortOrder)
Converts PitchforkTypes/PitchforkProperties object to string representation
Parameters:
this : PitchforkTypes/PitchforkProperties object
sortKeys : If set to true, string output is sorted by keys.
sortOrder : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
Returns: string representation of PitchforkTypes/PitchforkProperties
tostring(this, sortKeys, sortOrder)
Converts PitchforkTypes/PitchforkDrawingProperties object to string representation
Parameters:
this : PitchforkTypes/PitchforkDrawingProperties object
sortKeys : If set to true, string output is sorted by keys.
sortOrder : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
Returns: string representation of PitchforkTypes/PitchforkDrawingProperties
tostring(this, sortKeys, sortOrder)
Converts PitchforkTypes/Pitchfork object to string representation
Parameters:
this : PitchforkTypes/Pitchfork object
sortKeys : If set to true, string output is sorted by keys.
sortOrder : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
Returns: string representation of PitchforkTypes/Pitchfork
createDrawing(this)
Creates PitchforkTypes/PitchforkDrawing from PitchforkTypes/Pitchfork object
Parameters:
this : PitchforkTypes/Pitchfork object
Returns: PitchforkTypes/PitchforkDrawing object created
createDrawing(this)
Creates PitchforkTypes/PitchforkDrawing array from PitchforkTypes/Pitchfork array of objects
Parameters:
this : array of PitchforkTypes/Pitchfork object
Returns: array of PitchforkTypes/PitchforkDrawing object created
draw(this)
draws from PitchforkTypes/PitchforkDrawing object
Parameters:
this : PitchforkTypes/PitchforkDrawing object
Returns: PitchforkTypes/PitchforkDrawing object drawn
delete(this)
deletes PitchforkTypes/PitchforkDrawing object
Parameters:
this : PitchforkTypes/PitchforkDrawing object
Returns: PitchforkTypes/PitchforkDrawing object deleted
delete(this)
deletes underlying drawing of PitchforkTypes/Pitchfork object
Parameters:
this : PitchforkTypes/Pitchfork object
Returns: PitchforkTypes/Pitchfork object deleted
delete(this)
deletes array of PitchforkTypes/PitchforkDrawing objects
Parameters:
this : Array of PitchforkTypes/PitchforkDrawing object
Returns: Array of PitchforkTypes/PitchforkDrawing object deleted
delete(this)
deletes underlying drawing in array of PitchforkTypes/Pitchfork objects
Parameters:
this : Array of PitchforkTypes/Pitchfork object
Returns: Array of PitchforkTypes/Pitchfork object deleted
clear(this)
deletes array of PitchforkTypes/PitchforkDrawing objects and clears the array
Parameters:
this : Array of PitchforkTypes/PitchforkDrawing object
Returns: void
clear(this)
deletes array of PitchforkTypes/Pitchfork objects and clears the array
Parameters:
this : Array of Pitchfork/Pitchfork object
Returns: void
PitchforkTypesLibrary "PitchforkTypes"
User Defined Types to be used for Pitchfork and Drawing elements of Pitchfork. Depends on DrawingTypes for Point, Line, and LineProperties objects
PitchforkDrawingProperties
Pitchfork Drawing Properties object
Fields:
extend : If set to true, forks are extended towards right. Default is true
fill : Fill forklines with transparent color. Default is true
fillTransparency : Transparency at which fills are made. Only considered when fill is set. Default is 80
forceCommonColor : Force use of common color for forks and fills. Default is false
commonColor : common fill color. Used only if ratio specific fill colors are not available or if forceCommonColor is set to true.
PitchforkDrawing
Pitchfork drawing components
Fields:
medianLine : Median line of the pitchfork
baseLine : Base line of the pitchfork
forkLines : fork lines of the pitchfork
linefills : Linefills between forks
Fork
Fork object property
Fields:
ratio : Fork ratio
forkColor : color of fork. Default is blue
include : flag to include the fork in drawing. Default is true
PitchforkProperties
Pitchfork Properties
Fields:
forks : Array of Fork objects
type : Pitchfork type. Supported values are "regular", "schiff", "mschiff", Default is regular
inside : Flag to identify if to draw inside fork. If set to true, inside fork will be drawn
Pitchfork
Pitchfork object
Fields:
a : Pivot Point A of pitchfork
b : Pivot Point B of pitchfork
c : Pivot Point C of pitchfork
properties : PitchforkProperties object which determines type and composition of pitchfork
dProperties : Drawing properties for pitchfork
lProperties : Common line properties for Pitchfork lines
drawing : PitchforkDrawing object

ZigzagMethodsLibrary "ZigzagMethods"
Object oriented implementation of Zigzag methods. Please refer to ZigzagTypes library for User defined types used in this library
tostring(this, sortKeys, sortOrder, includeKeys)
Converts ZigzagTypes/Pivot object to string representation
Parameters:
this : ZigzagTypes/Pivot
sortKeys : If set to true, string output is sorted by keys.
sortOrder : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
includeKeys : Array of string containing selective keys. Optional parmaeter. If not provided, all the keys are considered
Returns: string representation of ZigzagTypes/Pivot
tostring(this, sortKeys, sortOrder, includeKeys)
Converts Array of Pivot objects to string representation
Parameters:
this : Pivot object array
sortKeys : If set to true, string output is sorted by keys.
sortOrder : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
includeKeys : Array of string containing selective keys. Optional parmaeter. If not provided, all the keys are considered
Returns: string representation of Pivot object array
tostring(this)
Converts ZigzagFlags object to string representation
Parameters:
this : ZigzagFlags object
Returns: string representation of ZigzagFlags
tostring(this, sortKeys, sortOrder, includeKeys)
Converts ZigzagTypes/Zigzag object to string representation
Parameters:
this : ZigzagTypes/Zigzagobject
sortKeys : If set to true, string output is sorted by keys.
sortOrder : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
includeKeys : Array of string containing selective keys. Optional parmaeter. If not provided, all the keys are considered
Returns: string representation of ZigzagTypes/Zigzag
calculate(this, ohlc, indicators, indicatorNames)
Calculate zigzag based on input values and indicator values
Parameters:
this : Zigzag object
ohlc : Array containing OHLC values. Can also have custom values for which zigzag to be calculated
indicators : Array of indicator values
indicatorNames : Array of indicator names for which values are present. Size of indicators array should be equal to that of indicatorNames
Returns: current Zigzag object
calculate(this)
Calculate zigzag based on properties embedded within Zigzag object
Parameters:
this : Zigzag object
Returns: current Zigzag object
nextlevel(this)
Calculate Next Level Zigzag based on the current calculated zigzag object
Parameters:
this : Zigzag object
Returns: Next Level Zigzag object
clear(this)
Clears zigzag drawings array
Parameters:
this : array
Returns: void
drawfresh(this)
draws fresh zigzag based on properties embedded in ZigzagDrawing object
Parameters:
this : ZigzagDrawing object
Returns: ZigzagDrawing object
drawcontinuous(this)
draws zigzag based on the zigzagmatrix input
Parameters:
this : ZigzagDrawing object
Returns:

ZigzagTypesLibrary "ZigzagTypes"
Zigzag related user defined types. Depends on DrawingTypes library for basic types
Indicator
Indicator is collection of indicator values applied on high, low and close
Fields:
indicatorHigh : Indicator Value applied on High
indicatorLow : Indicator Value applied on Low
PivotCandle
PivotCandle represents data of the candle which forms either pivot High or pivot low or both
Fields:
_high : High price of candle forming the pivot
_low : Low price of candle forming the pivot
length : Pivot length
pHighBar : represents number of bar back the pivot High occurred.
pLowBar : represents number of bar back the pivot Low occurred.
pHigh : Pivot High Price
pLow : Pivot Low Price
indicators : Array of Indicators - allows to add multiple
Pivot
Pivot refers to zigzag pivot. Each pivot can contain various data
Fields:
point : pivot point coordinates
dir : direction of the pivot. Valid values are 1, -1, 2, -2
level : is used for multi level zigzags. For single level, it will always be 0
ratio : Price Ratio based on previous two pivots
indicatorNames : Names of the indicators applied on zigzag
indicatorValues : Values of the indicators applied on zigzag
indicatorRatios : Ratios of the indicators applied on zigzag based on previous 2 pivots
ZigzagFlags
Flags required for drawing zigzag. Only used internally in zigzag calculation. Should not set the values explicitly
Fields:
newPivot : true if the calculation resulted in new pivot
doublePivot : true if the calculation resulted in two pivots on same bar
updateLastPivot : true if new pivot calculated replaces the old one.
Zigzag
Zigzag object which contains whole zigzag calculation parameters and pivots
Fields:
length : Zigzag length. Default value is 5
numberOfPivots : max number of pivots to hold in the calculation. Default value is 20
offset : Bar offset to be considered for calculation of zigzag. Default is 0 - which means calculation is done based on the latest bar.
level : Zigzag calculation level - used in multi level recursive zigzags
zigzagPivots : array which holds the last n pivots calculated.
flags : ZigzagFlags object which is required for continuous drawing of zigzag lines.
ZigzagObject
Zigzag Drawing Object
Fields:
zigzagLine : Line joining two pivots
zigzagLabel : Label which can be used for drawing the values, ratios, directions etc.
ZigzagProperties
Object which holds properties of zigzag drawing. To be used along with ZigzagDrawing
Fields:
lineColor : Zigzag line color. Default is color.blue
lineWidth : Zigzag line width. Default is 1
lineStyle : Zigzag line style. Default is line.style_solid.
showLabel : If set, the drawing will show labels on each pivot. Default is false
textColor : Text color of the labels. Only applicable if showLabel is set to true.
maxObjects : Max number of zigzag lines to display. Default is 300
xloc : Time/Bar reference to be used for zigzag drawing. Default is Time - xloc.bar_time.
ZigzagDrawing
Object which holds complete zigzag drawing objects and properties.
Fields:
properties : ZigzagProperties object which is used for setting the display styles of zigzag
drawings : array which contains lines and labels of zigzag drawing.
zigzag : Zigzag object which holds the calculations.
DrawingMethodsLibrary "DrawingMethods"
tostring(this, sortKeys, sortOrder, includeKeys)
Converts DrawingTypes/Point object to string representation
Parameters:
this : DrawingTypes/Point object
sortKeys : If set to true, string output is sorted by keys.
sortOrder : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
includeKeys : Array of string containing selective keys. Optional parmaeter. If not provided, all the keys are considered
Returns: string representation of DrawingTypes/Point
tostring(this, sortKeys, sortOrder, includeKeys)
Converts DrawingTypes/LineProperties object to string representation
Parameters:
this : DrawingTypes/LineProperties object
sortKeys : If set to true, string output is sorted by keys.
sortOrder : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
includeKeys : Array of string containing selective keys. Optional parmaeter. If not provided, all the keys are considered
Returns: string representation of DrawingTypes/LineProperties
tostring(this, sortKeys, sortOrder, includeKeys)
Converts DrawingTypes/Line object to string representation
Parameters:
this : DrawingTypes/Line object
sortKeys : If set to true, string output is sorted by keys.
sortOrder : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
includeKeys : Array of string containing selective keys. Optional parmaeter. If not provided, all the keys are considered
Returns: string representation of DrawingTypes/Line
tostring(this, sortKeys, sortOrder, includeKeys)
Converts DrawingTypes/LabelProperties object to string representation
Parameters:
this : DrawingTypes/LabelProperties object
sortKeys : If set to true, string output is sorted by keys.
sortOrder : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
includeKeys : Array of string containing selective keys. Optional parmaeter. If not provided, all the keys are considered
Returns: string representation of DrawingTypes/LabelProperties
tostring(this, sortKeys, sortOrder, includeKeys)
Converts DrawingTypes/Label object to string representation
Parameters:
this : DrawingTypes/Label object
sortKeys : If set to true, string output is sorted by keys.
sortOrder : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
includeKeys : Array of string containing selective keys. Optional parmaeter. If not provided, all the keys are considered
Returns: string representation of DrawingTypes/Label
tostring(this, sortKeys, sortOrder, includeKeys)
Converts DrawingTypes/Linefill object to string representation
Parameters:
this : DrawingTypes/Linefill object
sortKeys : If set to true, string output is sorted by keys.
sortOrder : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
includeKeys : Array of string containing selective keys. Optional parmaeter. If not provided, all the keys are considered
Returns: string representation of DrawingTypes/Linefill
tostring(this, sortKeys, sortOrder, includeKeys)
Converts DrawingTypes/BoxProperties object to string representation
Parameters:
this : DrawingTypes/BoxProperties object
sortKeys : If set to true, string output is sorted by keys.
sortOrder : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
includeKeys : Array of string containing selective keys. Optional parmaeter. If not provided, all the keys are considered
Returns: string representation of DrawingTypes/BoxProperties
tostring(this, sortKeys, sortOrder, includeKeys)
Converts DrawingTypes/BoxText object to string representation
Parameters:
this : DrawingTypes/BoxText object
sortKeys : If set to true, string output is sorted by keys.
sortOrder : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
includeKeys : Array of string containing selective keys. Optional parmaeter. If not provided, all the keys are considered
Returns: string representation of DrawingTypes/BoxText
tostring(this, sortKeys, sortOrder, includeKeys)
Converts DrawingTypes/Box object to string representation
Parameters:
this : DrawingTypes/Box object
sortKeys : If set to true, string output is sorted by keys.
sortOrder : Applicable only if sortKeys is set to true. Positive number will sort them in ascending order whreas negative numer will sort them in descending order. Passing 0 will not sort the keys
includeKeys : Array of string containing selective keys. Optional parmaeter. If not provided, all the keys are considered
Returns: string representation of DrawingTypes/Box
delete(this)
Deletes line from DrawingTypes/Line object
Parameters:
this : DrawingTypes/Line object
Returns: Line object deleted
delete(this)
Deletes label from DrawingTypes/Label object
Parameters:
this : DrawingTypes/Label object
Returns: Label object deleted
delete(this)
Deletes Linefill from DrawingTypes/Linefill object
Parameters:
this : DrawingTypes/Linefill object
Returns: Linefill object deleted
delete(this)
Deletes box from DrawingTypes/Box object
Parameters:
this : DrawingTypes/Box object
Returns: DrawingTypes/Box object deleted
delete(this)
Deletes lines from array of DrawingTypes/Line objects
Parameters:
this : Array of DrawingTypes/Line objects
Returns: Array of DrawingTypes/Line objects
delete(this)
Deletes labels from array of DrawingTypes/Label objects
Parameters:
this : Array of DrawingTypes/Label objects
Returns: Array of DrawingTypes/Label objects
delete(this)
Deletes linefill from array of DrawingTypes/Linefill objects
Parameters:
this : Array of DrawingTypes/Linefill objects
Returns: Array of DrawingTypes/Linefill objects
delete(this)
Deletes boxes from array of DrawingTypes/Box objects
Parameters:
this : Array of DrawingTypes/Box objects
Returns: Array of DrawingTypes/Box objects
clear(this)
clear items from array of DrawingTypes/Line while deleting underlying objects
Parameters:
this : array
Returns: void
clear(this)
clear items from array of DrawingTypes/Label while deleting underlying objects
Parameters:
this : array
Returns: void
clear(this)
clear items from array of DrawingTypes/Linefill while deleting underlying objects
Parameters:
this : array
Returns: void
clear(this)
clear items from array of DrawingTypes/Box while deleting underlying objects
Parameters:
this : array
Returns: void
draw(this)
Creates line from DrawingTypes/Line object
Parameters:
this : DrawingTypes/Line object
Returns: line created from DrawingTypes/Line object
draw(this)
Creates lines from array of DrawingTypes/Line objects
Parameters:
this : Array of DrawingTypes/Line objects
Returns: Array of DrawingTypes/Line objects
draw(this)
Creates label from DrawingTypes/Label object
Parameters:
this : DrawingTypes/Label object
Returns: label created from DrawingTypes/Label object
draw(this)
Creates labels from array of DrawingTypes/Label objects
Parameters:
this : Array of DrawingTypes/Label objects
Returns: Array of DrawingTypes/Label objects
draw(this)
Creates linefill object from DrawingTypes/Linefill
Parameters:
this : DrawingTypes/Linefill objects
Returns: linefill object created
draw(this)
Creates linefill objects from array of DrawingTypes/Linefill objects
Parameters:
this : Array of DrawingTypes/Linefill objects
Returns: Array of DrawingTypes/Linefill used for creating linefills
draw(this)
Creates box from DrawingTypes/Box object
Parameters:
this : DrawingTypes/Box object
Returns: box created from DrawingTypes/Box object
draw(this)
Creates labels from array of DrawingTypes/Label objects
Parameters:
this : Array of DrawingTypes/Label objects
Returns: Array of DrawingTypes/Label objects
createLabel(this, lblText, tooltip, properties)
Creates DrawingTypes/Label object from DrawingTypes/Point
Parameters:
this : DrawingTypes/Point object
lblText : Label text
tooltip : Tooltip text. Default is na
properties : DrawingTypes/LabelProperties object. Default is na - meaning default values are used.
Returns: DrawingTypes/Label object
createLine(this, other, properties)
Creates DrawingTypes/Line object from one DrawingTypes/Point to other
Parameters:
this : First DrawingTypes/Point object
other : Second DrawingTypes/Point object
properties : DrawingTypes/LineProperties object. Default set to na - meaning default values are used.
Returns: DrawingTypes/Line object
createLinefill(this, other, fillColor, transparency)
Creates DrawingTypes/Linefill object from DrawingTypes/Line object to other DrawingTypes/Line object
Parameters:
this : First DrawingTypes/Line object
other : Other DrawingTypes/Line object
fillColor : fill color of linefill. Default is color.blue
transparency : fill transparency for linefill. Default is 80
Returns: Array of DrawingTypes/Linefill object
createBox(this, other, properties, textProperties)
Creates DrawingTypes/Box object from one DrawingTypes/Point to other
Parameters:
this : First DrawingTypes/Point object
other : Second DrawingTypes/Point object
properties : DrawingTypes/BoxProperties object. Default set to na - meaning default values are used.
textProperties : DrawingTypes/BoxText object. Default is na - meaning no text will be drawn
Returns: DrawingTypes/Box object
createBox(this, properties, textProperties)
Creates DrawingTypes/Box object from DrawingTypes/Line as diagonal line
Parameters:
this : Diagonal DrawingTypes/PoLineint object
properties : DrawingTypes/BoxProperties object. Default set to na - meaning default values are used.
textProperties : DrawingTypes/BoxText object. Default is na - meaning no text will be drawn
Returns: DrawingTypes/Box object

DrawingTypesLibrary "DrawingTypes"
User Defined Types for basic drawing structure. Other types and methods will be built on these.
Point
Point refers to point on chart
Fields:
price : pivot price
bar : pivot bar
bartime : pivot bar time
LineProperties
Properties of line object
Fields:
xloc : X Reference - can be either xloc.bar_index or xloc.bar_time. Default is xloc.bar_index
extend : Property which sets line to extend towards either right or left or both. Valid values are extend.right, extend.left, extend.both, extend.none. Default is extend.none
color : Line color
style : Line style, valid values are line.style_solid, line.style_dashed, line.style_dotted, line.style_arrow_left, line.style_arrow_right, line.style_arrow_both. Default is line.style_solid
width : Line width. Default is 1
Line
Line object created from points
Fields:
start : Starting point of the line
end : Ending point of the line
properties : LineProperties object which defines the style of line
object : Derived line object
LabelProperties
Properties of label object
Fields:
xloc : X Reference - can be either xloc.bar_index or xloc.bar_time. Default is xloc.bar_index
yloc : Y reference - can be yloc.price, yloc.abovebar, yloc.belowbar. Default is yloc.price
color : Label fill color
style : Label style as defined in www.tradingview.com Default is label.style_none
textcolor : text color. Default is color.black
size : Label text size. Default is size.normal. Other values are size.auto, size.tiny, size.small, size.normal, size.large, size.huge
textalign : Label text alignment. Default if text.align_center. Other allowed values - text.align_right, text.align_left, text.align_top, text.align_bottom
text_font_family : The font family of the text. Default value is font.family_default. Other available option is font.family_monospace
Label
Label object
Fields:
point : Point where label is drawn
lblText : label text
tooltip : Tooltip text. Default is na
properties : LabelProperties object
object : Pine label object
Linefill
Linefill object
Fields:
line1 : First line to create linefill
line2 : Second line to create linefill
fillColor : Fill color
transparency : Fill transparency range from 0 to 100
object : linefill object created from wrapper
BoxProperties
BoxProperties object
Fields:
border_color : Box border color. Default is color.blue
bgcolor : box background color
border_width : Box border width. Default is 1
border_style : Box border style. Default is line.style_solid
extend : Extend property of box. default is extend.none
xloc : defines if drawing needs to be done based on bar index or time. default is xloc.bar_index
BoxText
Box Text properties.
Fields:
boxText : Text to be printed on the box
text_size : Text size. Default is size.auto
text_color : Box text color. Default is color.yellow.
text_halign : horizontal align style - default is text.align_center
text_valign : vertical align style - default is text.align_center
text_wrap : text wrap style - default is text.wrap_auto
text_font_family : Text font. Default is
Box
Box object
Fields:
p1 : Diagonal point one
p2 : Diagonal point two
properties : Box properties
textProperties : Box text properties
object : Box object created

RSI Impact Heat Map [Trendoscope]Here is a simple tool to measure and display outcome of certain RSI event over heat map.
🎲 Process
🎯Event
Event can be either Crossover or Crossunder of RSI on certain value.
🎯Measuring Impact
Impact of the event after N number of bars is measured in terms of highest and lowest displacement from the last close price. Impact can be collected as either number of times of ATR or percentage of price. Impact for each trigger is recorded separately and stored in array of custom type.
🎯Plotting Heat Map
Heat map is displayed using pine tables. Users can select heat map size - which can vary from 10 to 90. Selecting optimal size is important in order to get right interpretation of data. Having higher number of cells can give more granular data. But, chart may not fit into the window. Having lower size means, stats are combined together to get less granular data which may not give right picture of the results. Default value for size is 50 - meaning data is displayed in 51X51 cells.
Range of the heat map is adjusted automatically based on min and max value of the displacement. In order to filter out or merge extreme values, range is calculated based on certain percentile of the values. This will avoid displaying lots of empty cells which can obscure the actual impact.
🎲 Settings
Settings allow users to define their event, impact duration and reference, and few display related properties. The description of these parameters are as below:
🎲 Use Cases
In this script, we have taken RSI as an example to measure impact. But, we can do this for any event. This can be price crossing over/under upper/lower bollinger bands, moving average crossovers or even complex entry or exit conditions. Overall, we can use this to plot and evaluate our trade criteria.
🎲 Interpretation
Q1 - If more coloured dots appear on the top right corner of the table, then the event is considered to trigger high volatility and high risk environment.
Q2 - If more coloured dots appear on the top left corner, then the events are considered to trigger bearish environment.
Q3 - If more coloured dots appear on the bottom left corner of the chart, then the events are considered insignificant as they neither generate higher displacement in positive or negative side. You can further alter outlier percentage to reduce the bracket and hence have higher distribution move towards
Q4 - If more coloured dots appear on the bottom right corner, then the events are considered to trigger bullish environment.
Will also look forward to implement this as library so that any conditions or events can be plugged into it.

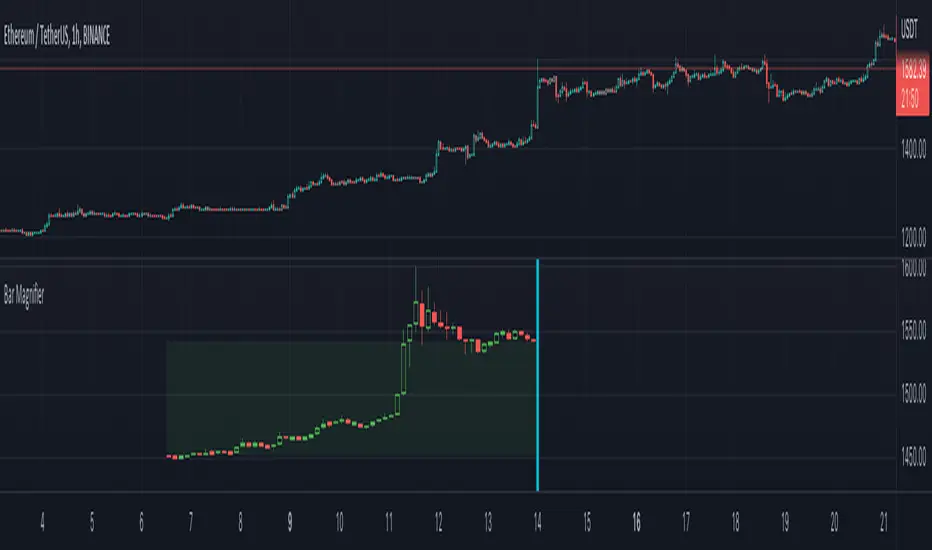
Bar MagnifierMany times while developing algos based on patterns and reversals, I come across issues which needs lower timeframe inspection. Loading multiple charts and comparing equivalent lower timeframe is slightly cumbersome at times. Hence, I thought of building this simple tool - which will instantly provide me lower timeframe candles for given candle. Since the candle selection happen via confirmed time input, we can use this as slider to move from one candle to other for inspection.
🎲 Usage
🎯Loading the script
When you load the script, a prompt appears which asks you to select a time by clicking on the chart.
Select the bar you want to magnify and study
🎯Components
Once loaded, you can see the marker which tells which bar is magnified. And you can also see all the lower timeframe candles before that point. Please note that due to pine restrictions, we can only show last 250 lower timeframe bars. You can change the lower timeframe via settings to cover if the chart timeframe is very high.
🎯Moving to different bars
Click on the middle of the marker, you will see slider which you can slide to move from one bar to other.
Example, after sliding, you will see the lower timeframe data of new candle.
🎯Settings
Settings has only two inputs.
Bar time - selects the bar which needs to be inspected.
Lower timeframe - Default is 1 min. And select a timeframe according to your chart timeframe. Less than 1 min is not supported by security.lower_tf function. Hence, will not work.
eHarmonicpatternsLogScaleLibrary "eHarmonicpatternsLogScale"
Library provides functions to scan harmonic patterns both or normal and log scale
getSupportedPatterns()
get_prz_range(x, a, b, c, patternArray, errorPercent, start_adj, end_adj, logScale)
Provides PRZ range based on BCD and XAD ranges
Parameters:
x : X coordinate value
a : A coordinate value
b : B coordinate value
c : C coordinate value
patternArray : Pattern flags for which PRZ range needs to be calculated
errorPercent : Error threshold
start_adj : - Adjustments for entry levels
end_adj : - Adjustments for stop levels
logScale : - calculate on log scale. Default is false
Returns: Start and end of consolidated PRZ range
get_prz_range_xad(x, a, b, c, patternArray, errorPercent, start_adj, end_adj, logScale)
Provides PRZ range based on XAD range only
Parameters:
x : X coordinate value
a : A coordinate value
b : B coordinate value
c : C coordinate value
patternArray : Pattern flags for which PRZ range needs to be calculated
errorPercent : Error threshold
start_adj : - Adjustments for entry levels
end_adj : - Adjustments for stop levels
logScale : - calculate on log scale. Default is false
Returns: Start and end of consolidated PRZ range
get_projection_range(x, a, b, c, patternArray, errorPercent, start_adj, end_adj, logScale)
Provides Projection range based on BCD and XAD ranges
Parameters:
x : X coordinate value
a : A coordinate value
b : B coordinate value
c : C coordinate value
patternArray : Pattern flags for which PRZ range needs to be calculated
errorPercent : Error threshold
start_adj : - Adjustments for entry levels
end_adj : - Adjustments for stop levels
logScale : - calculate on log scale. Default is false
Returns: Array containing start and end ranges
isHarmonicPattern(x, a, b, c, d, flags, defaultEnabled, errorPercent, logScale)
Checks for harmonic patterns
Parameters:
x : X coordinate value
a : A coordinate value
b : B coordinate value
c : C coordinate value
d : D coordinate value
flags : flags to check patterns. Send empty array to enable all
defaultEnabled
errorPercent : Error threshold
logScale : - calculate on log scale. Default is false
Returns: Array of boolean values which says whether valid pattern exist and array of corresponding pattern names
isHarmonicProjection(x, a, b, c, flags, defaultEnabled, errorPercent, logScale)
Checks for harmonic pattern projection
Parameters:
x : X coordinate value
a : A coordinate value
b : B coordinate value
c : C coordinate value
flags : flags to check patterns. Send empty array to enable all
defaultEnabled
errorPercent : Error threshold
logScale : - calculate on log scale. Default is false
Returns: Array of boolean values which says whether valid pattern exist and array of corresponding pattern names.

Band-Zigzag - TrendFollower Strategy [Trendoscope]Strategy Time!!!
Have built this on my earlier published indicator Band-Zigzag-Trend-Follower . This is just one possible implementation of strategy on Band-Based-Zigzag .
🎲 Notes
Experimental prototype. Not financial advise and strategy not guaranteed to make money despite backtest results
Not created or tested for any specific instrument or timeframe
Test and adopt with own risk
🎲 Strategy
This is trend following strategy built based on Bands and Zigzag. Traits of trend following strategies are
Lower win rate (Yes, thats right)
High risk reward (Compensates low win rate)
Higher drawdown
If market is choppy, trend following methods suffer.
The script implements few points to overcome the negatives such as lower win rate and higher drawdown by actively assessing pivots on the direction of trend along. This helps us take regular profits and exit on time during the end of trend. Most of the other concepts are defined and explained in indicator - Band-Zigzag-Trend-Follower and Band-Based-Zigzag
Defining a trend following method is simple. Basic rule of trend following is Buy High and Sell Low (Yes, you heard it right). To explain further - methodology involve finding an established trend which is flying high and join the trend with proper risk and optimal stop. Once you get into the trade, you will not exit unless there is change in the trend. Or in other words, the parameters which you used to define trend has reversed and the trend is not valid anymore.
🎯 Using bands
When price breaks out of upper bands (example, Bollinger Band , Keltener Channel, or Donchian Channel), with a pre determined length and multiplier, we can consider the trend to be bullish and similarly when price breaks down the lower band, we can consider the trend to be bearish .
🎯 Using Pivots
Simple logic using zigzag or pivot points is that when price starts making higher highs and higher lows, we can consider this as uptrend. And when price starts making lower highs and lower lows, we can consider this as downtrend. There are few supertrend implementations I have published in the past based on zigzags and pivot points .
Drawbacks of both of these methods is that there will be too many fluctuations in both cases unless we increase the reference length. And if we increase the reference length, we will have higher drawdown.
🎯 Band Based Zigzag Method
Here we use bands to define our pivot high and pivot low - this makes sure that we are identifying trend only on breakouts as pivots are only formed on breakouts
Our method also includes pivot ratio to cross over 1.0 to be able to consider it as trend. This means, we are waiting for price also to make new high high or lower low before making the decision on trend. But, this helps us ignore smaller pivot movements due to the usage of bands.
I have also implemented few tricks such as sticky bands (Bands will not contract unless there is breakout) and Adaptive Bands (Band will not expand unless price is moving in the direction of band). This makes the trend following method very robust.
To avoid fakeouts, we also use percentB of high/low in comparison with price retracement to define breakout.
🎲 Settings
Settings are fairly simpler and are explained as below. You will find most of the required information in tooltips.

FibRatiosLibrary "FibRatios"
Library with calculation logic for fib retracement, extension and ratios
retracement(a, b, ratio, logScale, precision)
Calculates the retracement for points a, b with given ratio and scale
Parameters:
a : Starting point a
b : Second point b
ratio : Ratio for which we need to calculate retracement c
logScale : Flag to get calculations in log scale. Default is false
precision : rounding precision. If set to netagive number, round_to_mintick is applied. Default is -1
Returns: retracement point c for points a,b with given ratio and scale
retracementRatio(a, b, c, logScale, precision)
Calculates the retracement ratio for points a, b, c with given scale
Parameters:
a : Starting point a
b : Second point b
c : Retracement point. c should be placed between a and b
logScale : Flag to get calculations in log scale. Default is false
precision : rounding precision. If set to netagive number, round_to_mintick is applied. Default is 3
Returns: retracement ratio for points a,b,c on given scale
extension(a, b, c, ratio, logScale, precision)
Calculates the extensions for points a, b, c with given ratio and scale
Parameters:
a : Starting point a
b : Second point b
c : Retracement point. c should be placed between a and b
ratio : Ratio for which we need to calculate extension d
logScale : Flag to get calculations in log scale. Default is false
precision : rounding precision. If set to netagive number, round_to_mintick is applied. Default is -1
Returns: extensoin point d for points a,b,c with given ratio and scale
extensionRatio(a, b, c, d, logScale, precision)
Calculates the extension ratio for points a, b, c, d with given scale
Parameters:
a : Starting point a
b : Second point b
c : Retracement point. c should be placed between a and b
d : Extension point. d should be placed beyond a, c. But, can be with b,c or beyond b
logScale : Flag to get calculations in log scale. Default is false
precision : rounding precision. If set to netagive number, round_to_mintick is applied. Default is 3
Returns: extension ratio for points a,b,c,d on given scale

DataCorrelationLibrary "DataCorrelation"
Implementation of functions related to data correlation calculations. Formulas have been transformed in such a way that we avoid running loops and instead make use of time series to gradually build the data we need to perform calculation. This allows the calculations to run on unbound series, and/or higher number of samples
🎲 Simplifying Covariance
Original Formula
//For Sample
Covₓᵧ = ∑ ((xᵢ-x̄)(yᵢ-ȳ)) / (n-1)
//For Population
Covₓᵧ = ∑ ((xᵢ-x̄)(yᵢ-ȳ)) / n
Now, if we look at numerator, this can be simplified as follows
∑ ((xᵢ-x̄)(yᵢ-ȳ))
=> (x₁-x̄)(y₁-ȳ) + (x₂-x̄)(y₂-ȳ) + (x₃-x̄)(y₃-ȳ) ... + (xₙ-x̄)(yₙ-ȳ)
=> (x₁y₁ + x̄ȳ - x₁ȳ - y₁x̄) + (x₂y₂ + x̄ȳ - x₂ȳ - y₂x̄) + (x₃y₃ + x̄ȳ - x₃ȳ - y₃x̄) ... + (xₙyₙ + x̄ȳ - xₙȳ - yₙx̄)
=> (x₁y₁ + x₂y₂ + x₃y₃ ... + xₙyₙ) + (x̄ȳ + x̄ȳ + x̄ȳ ... + x̄ȳ) - (x₁ȳ + x₂ȳ + x₃ȳ ... xₙȳ) - (y₁x̄ + y₂x̄ + y₃x̄ + yₙx̄)
=> ∑xᵢyᵢ + n(x̄ȳ) - ȳ∑xᵢ - x̄∑yᵢ
So, overall formula can be simplified to be used in pine as
//For Sample
Covₓᵧ = (∑xᵢyᵢ + n(x̄ȳ) - ȳ∑xᵢ - x̄∑yᵢ) / (n-1)
//For Population
Covₓᵧ = (∑xᵢyᵢ + n(x̄ȳ) - ȳ∑xᵢ - x̄∑yᵢ) / n
🎲 Simplifying Standard Deviation
Original Formula
//For Sample
σ = √(∑(xᵢ-x̄)² / (n-1))
//For Population
σ = √(∑(xᵢ-x̄)² / n)
Now, if we look at numerator within square root
∑(xᵢ-x̄)²
=> (x₁² + x̄² - 2x₁x̄) + (x₂² + x̄² - 2x₂x̄) + (x₃² + x̄² - 2x₃x̄) ... + (xₙ² + x̄² - 2xₙx̄)
=> (x₁² + x₂² + x₃² ... + xₙ²) + (x̄² + x̄² + x̄² ... + x̄²) - (2x₁x̄ + 2x₂x̄ + 2x₃x̄ ... + 2xₙx̄)
=> ∑xᵢ² + nx̄² - 2x̄∑xᵢ
=> ∑xᵢ² + x̄(nx̄ - 2∑xᵢ)
So, overall formula can be simplified to be used in pine as
//For Sample
σ = √(∑xᵢ² + x̄(nx̄ - 2∑xᵢ) / (n-1))
//For Population
σ = √(∑xᵢ² + x̄(nx̄ - 2∑xᵢ) / n)
🎲 Using BinaryInsertionSort library
Chatterjee Correlation and Spearman Correlation functions make use of BinaryInsertionSort library to speed up sorting. The library in turn implements mechanism to insert values into sorted order so that load on sorting is reduced by higher extent allowing the functions to work on higher sample size.
🎲 Function Documentation
chatterjeeCorrelation(x, y, sampleSize, plotSize)
Calculates chatterjee correlation between two series. Formula is - ξnₓᵧ = 1 - (3 * ∑ |rᵢ₊₁ - rᵢ|)/ (n²-1)
Parameters:
x : First series for which correlation need to be calculated
y : Second series for which correlation need to be calculated
sampleSize : number of samples to be considered for calculattion of correlation. Default is 20000
plotSize : How many historical values need to be plotted on chart.
Returns: float correlation - Chatterjee correlation value if falls within plotSize, else returns na
spearmanCorrelation(x, y, sampleSize, plotSize)
Calculates spearman correlation between two series. Formula is - ρ = 1 - (6∑dᵢ²/n(n²-1))
Parameters:
x : First series for which correlation need to be calculated
y : Second series for which correlation need to be calculated
sampleSize : number of samples to be considered for calculattion of correlation. Default is 20000
plotSize : How many historical values need to be plotted on chart.
Returns: float correlation - Spearman correlation value if falls within plotSize, else returns na
covariance(x, y, include, biased)
Calculates covariance between two series of unbound length. Formula is Covₓᵧ = ∑ ((xᵢ-x̄)(yᵢ-ȳ)) / (n-1) for sample and Covₓᵧ = ∑ ((xᵢ-x̄)(yᵢ-ȳ)) / n for population
Parameters:
x : First series for which covariance need to be calculated
y : Second series for which covariance need to be calculated
include : boolean flag used for selectively including sample
biased : boolean flag representing population covariance instead of sample covariance
Returns: float covariance - covariance of selective samples of two series x, y
stddev(x, include, biased)
Calculates Standard Deviation of a series. Formula is σ = √( ∑(xᵢ-x̄)² / n ) for sample and σ = √( ∑(xᵢ-x̄)² / (n-1) ) for population
Parameters:
x : Series for which Standard Deviation need to be calculated
include : boolean flag used for selectively including sample
biased : boolean flag representing population covariance instead of sample covariance
Returns: float stddev - standard deviation of selective samples of series x
correlation(x, y, include)
Calculates pearson correlation between two series of unbound length. Formula is r = Covₓᵧ / σₓσᵧ
Parameters:
x : First series for which correlation need to be calculated
y : Second series for which correlation need to be calculated
include : boolean flag used for selectively including sample
Returns: float correlation - correlation between selective samples of two series x, y

Band-Zigzag Based Trend FollowerWe defined new method to derive zigzag last month - which is called Channel-Based-Zigzag . This script is an example of one of the use case of this method.
🎲 Trend Following
Defining a trend following method is simple. Basic rule of trend following is Buy High and Sell Low (Yes, you heard it right). To explain further - methodology involve finding an established trend which is flying high and join the trend with proper risk and optimal stop. Once you get into the trade, you will not exit unless there is change in the trend. Or in other words, the parameters which you used to define trend has reversed and the trend is not valid anymore.
Few examples are:
🎯 Using bands
When price breaks out of upper bands (example, Bollinger Band, Keltener Channel, or Donchian Channel), with a pre determined length and multiplier, we can consider the trend to be bullish and similarly when price breaks down the lower band, we can consider the trend to be bearish.
Here are few examples where I have used bands for identifying trend
Band-Based-Supertrend
Donchian-Channel-Trend-Filter
🎯 Using Pivots
Simple logic using zigzag or pivot points is that when price starts making higher highs and higher lows, we can consider this as uptrend. And when price starts making lower highs and lower lows, we can consider this as downtrend. There are few supertrend implementations I have published in the past based on zigzags and pivot points.
Adoptive-Supertrend-Pivots
Zigzag-Supertrend
Drawbacks of both of these methods is that there will be too many fluctuations in both cases unless we increase the reference length. And if we increase the reference length, we will have higher drawdown.
🎲 Band Based Zigzag Method
Band Based Zigzag will help overcome these issues by combining both the methods.
Here we use bands to define our pivot high and pivot low - this makes sure that we are identifying trend only on breakouts as pivots are only formed on breakouts.
Our method also includes pivot ratio to cross over 1.0 to be able to consider it as trend. This means, we are waiting for price also to make new high high or lower low before making the decision on trend. But, this helps us ignore smaller pivot movements due to the usage of bands.
I have also implemented few tricks such as sticky bands (Bands will not contract unless there is breakout) and Adaptive Bands (Band will not expand unless price is moving in the direction of band). This makes the trend following method very robust.
To avoid fakeouts, we also use percentB of high/low in comparison with price retracement to define breakout.
🎲 The indicator
The output of indicator is simple and intuitive to understand.
🎯 Trend Criteria
Uptrend when last confirmed pivot is pivot high and has higher retracement ratio than PercentB of High. Else, considered as downtrend.
Downtrend when last confirmed pivot is pivot low and has higher retracement ratio than PercentB of High. Else, considered as uptrend.
🎯 Settings
Settings allow you to select the band type and parameters used for calculating zigzag and then trend. Also has few options to hide the display.

Chatterjee CorrelationThis is my first attempt on implementing a statistical method. This problem was given to me by @lejmer (who also helped me later on building more efficient code to achieve this) when we were debating on the need for higher resource allocation to run scripts so it can run longer and faster. The major problem faced by those who want to implement statistics based methods is that they run out of processing time or need to limit the data samples. My point was that such things need be implemented with an algorithm which suits pine instead of trying to port a python code directly. And yes, I am able to demonstrate that by using this implementation of Chatterjee Correlation.
🎲 What is Chatterjee Correlation?
The Chatterjee rank Correlation Coefficient (CCC) is a method developed by Sourav Chatterjee which can be used to study non linear correlation between two series.
Full documentation on the method can be found here:
arxiv.org
In short, the formula which we are implementing here is:
Algorithm can be simplified as follows:
1. Get the ranks of X
2. Get the ranks of Y
3. Sort ranks of Y in the order of X (Lets call this SortedYIndices)
4. Calculate the sum of adjacent Y ranks in SortedYIndices (Lets call it as SumOfAdjacentSortedIndices)
5. And finally the correlation coefficient can be calculated by using simple formula
CCC = 1 - (3*SumOfAdjacentSortedIndices)/(n^2 - 1)
🎲 Looks simple? What is the catch?
Mistake many people do here is that they think in Python/Java/C etc while coding in Pine. This makes code less efficient if it involves arrays and loops. And the simple code may look something like this.
var xArray = array.new()
var yArray = array.new()
array.push(xArray, x)
array.push(yArray, y)
sortX = array.sort_indices(xArray)
sortY = array.sort_indices(yArray)
SumOfAdjacentSortedIndices = 0.0
index = array.get(xSortIndices, 0)
for i=1 to n > 1? n -1 : na
indexNext = array.get(sortX, i)
SumOfAdjacentSortedIndices += math.abs(array.get(sortY, indexNext)-array.get(sortY, index))
index := indexNext
correlation := 1 - 3*SumOfAdjacentSortedIndices/(math.pow(n,2)-1)
But, problem here is the number of loops run. Remember pine executes the code on every bar. There are loops run in array.sort_indices and another loop we are running to calculate SumOfAdjacentSortedIndices. Due to this, chances of program throwing runtime errors due to script running for too long are pretty high. This limits greatly the number of samples against which we can run the study. The options to overcome are
Limit the sample size and calculate only between certain bars - this is not ideal as smaller sets are more likely to yield false or inconsistent results.
Start thinking in pine instead of python and code in such a way that it is optimised for pine. - This is exactly what we have done in the published code.
🎲 How to think in Pine?
In order to think in pine, you should try to eliminate the loops as much as possible. Specially on the data which is continuously growing.
My first thought was that sorting takes lots of time and need to find a better way to sort series - specially when it is a growing data set. Hence, I came up with this library which implements Binary Insertion Sort.
Replacing array.sort_indices with binary insertion sort will greatly reduce the number of loops run on each bar. In binary insertion sort, the array will remain sorted and any item we add, it will keep adding it in the existing sort order so that there is no need to run separate sort. This allows us to work with bigger data sets and can utilise full 20,000 bars for calculation instead of few 100s.
However, last loop where we calculate SumOfAdjacentSortedIndices is not replaceable easily. Hence, we only limit these iterations to certain bars (Even though we use complete sample size). Plots are made for only those bars where the results need to be printed.
🎲 Implementation
Current implementation is limited to few combinations of x and fixed y. But, will be converting this into library soon - which means, programmers can plug any x and y and get the correlation.
Our X here can be
Average volume
ATR
And our Y is distance of price from moving average - which identifies trend.
Thus, the indicator here helps to understand the correlation coefficient between volume and trend OR volatility and trend for given ticker and timeframe. Value closer to 1 means highly correlated and value closer to 0 means least correlated. Please note that this method will not tell how these values are correlated. That is, we will not be able to know if higher volume leads to higher trend or lower trend. But, we can say whether volume impacts trend or not.
Please note that values can differ by great extent for different timeframes. For example, if you look at 1D timeframe, you may get higher value of correlation coefficient whereas lower value for 1m timeframe. This means, volume to trend correlation is higher in 1D timeframe and lower in lower timeframes.

HSupertrendLibrary "HSupertrend"
Supertrend implementation based on harmonic patterns
hsupertrend(zProperties, pProperties, errorPercent, showPatterns, patternColor)
derives supertrend based on harmonic patterns
Parameters:
zProperties : ZigzagProperties containing Zigzag length and source array
pProperties : PatternProperties used for calculation
errorPercent : Error threshold for scanning patterns
showPatterns : Draw identified patterns structure on chart
patternColor : Color of the pattern lines to be drawn
Returns:
ZigzagProperties
ZigzagProperties contains values required for zigzag calculation
Fields:
length : Zigzag length
source : Array containing custom OHLC. If not set, array.from(high, low) is used
PatternProperties
PatternProperties are essential pattern parameters used for calculation of bullish and bearish zones
Fields:
base : Base for calculating entry and stop of pattern. Can be CD, minmax or correction. Default is CD
entryPercent : Distance from D in terms of percent of Base in the direction of pattern
stopPercent : Distance from D in terms of percent of Base in the opposite direction of pattern
useClosePrices : When set uses close price for calculation of supertrend breakout

Harmonic Patterns Based SupertrendExtending the earlier implemented concept of Harmonic-Patterns-Based-Trend-Follower , in this script, lets make it work as supertrend so that it is more easier to operate.
🎲 Process
🎯 Derive Zigzag and scan harmonic patterns for last 5 confirmed pivots
🎯 If a pattern is found, bullish and bearish zones are calculated based on parameter Base
🎯 These bullish and bearish zones act as supertrend based on current trade in progress.
🎯 When in bullish mode, bearish zone will only go up irrespective of new pattern forming new low. Similarly when in bearish mode, bullish zones will only come down - this is done to imitate the standard supertrend behaviour.
🎲 Note
Patterns are not created on latest pivot as last pivot will be unconfirmed and moving. Due to this, patterns appear after certain delay - patterns will not be real time. But, this is expected and does not impact the overall process.
Here are few chart captures to demonstrate how it works.
🎲 Settings
Settings are explained in the screenshot below.

Harmonic Patterns Based Trend FollowerEarlier this week, published an idea on how harmonic patterns can be used for trend following. This script is an attempt to implement the same.
🎲 Process
🎯 Derive Zigzag and scan harmonic patterns for last 5 confirmed pivots
🎯 If a pattern is found, highest point of pattern will become the bullish zone and lower point of the pattern will become bearish zone.
🎯 Since it is trend following method, when price reaches bullish zone, then the trend is considered as bullish and when price reaches bearish zone, the trend is considered as bearish.
🎯 If price does not touch both regions, then trend remains unchanged.
🎯 Bullish and bearish zone will change as and when new patterns are formed.
🎲 Note
Patterns are not created on latest pivot as last pivot will be unconfirmed and moving. Due to this, patterns appear after certain delay - patterns will not be real time. But, this is expected and does not impact the overall process.
When new pattern formed
When price breaks over the zones
🎲 Output
🎯 Patterns formed are drawn in blue coloured lines. Due to pine limitation of max 500 lines, older patterns automatically get deleted when new ones come.
🎯 Bullish Zone and Bearish Zone are plotted in green and red colours and the zone will change whenever new pattern comes along.
🎯 Bar colors are changed according to calculated trend. Trend value can be 1 or -1 based on the current trend. You can also find the value in data window.
🎯 For simplicity purpose, input option for selection of specific patterns are not provided and also pattern names are not displayed on the chart.
Auto Harmonic Pattern - Backtester [Trendoscope]We are finally here with the implementation of backtesting tool for Auto-Harmonic-Pattern-UltimateX .
CAUTION: THIS IS NOT A STRATEGY AND SHOULD NOT BE FOLLOWED BLINDLY. WE ENCOURAGE USERS TO UTILISE THIS AS BACKTESTING TOOL FOR BUILDING THEIR STRATEGY BASED ON HARMONIC PATTERNS
This script is based on our premium indicator - Auto-Harmonic-Pattern-UltimateX . In this script, along with implementation of scanning harmonic patterns, we provide various options via settings which enables users to build their own strategy based on harmonic patterns, use them with custom coded filters, backtest them on various tickers and timeframes.
Harmonic Patterns is concept and we can trade harmonic pattern in many ways. While general interest around harmonic patterns is to find reversal zones and use them for short term swing trades. But, using it along trend following strategies can also be very rewarding. Here is one of the educational idea I shared about using harmonic patterns for trend following. These are just few possibilities where users can explore further on how they want to trade this. The settings of this script are crafted in such a way that it enables users to explore all these possibilities.
🎲 Components
Chart components of this script is lighter compared to Auto Harmonic Pattern - UltimateX. This is because we want to keep lighter interface in order to support seamless execution of emulator. Since pine strategy framework does most of the things such as calculating profitability, keeping track of trades and results etc, display with respect to - "Closed Trade Stats" are removed from this script and "Open Trade Stats" are made lighter.
🎲 Settings
🎯 Trade Settings : Few important settings under this section are
Due to pine limitations, we will not be able to support both long and short in a same setup. Hence, users need to chose either long or short trade setup.
Entry/Base/Target play important role in defining your strategy.
Confluence is another important factor which lets users use multiple patterns at once as confirmation.
🎯 Zigzag Settings : Zigzag settings determine the size of patterns being formed.
Please note that smaller patterns may not yield very good results and larger patterns may take time to complete trade. Similarly higher depth can cause runtime issues. Recursive zigzag option is alternative to deep search algorithm.
🎯 Filters :
Filters enable users to select trades based on specific conditions. Ability to use external filter even allows writing and using custom filters to be used with this algorithm. Here is a video which explains how this can be done. HOW-TO-Use-external-filters
Pattern filters allow users to pick and chose patterns they want to trade. This can be done either individually or based on category
🎯 Alerts :
Apart from strategy specific alerts, the script also implements customisable alerts via pine alert() function. Alerts can be configured to send upon three conditions
When new pattern is created
When an existing pattern updates entry/stop/target due to safe repaint of D (Only happens when Trail Entry Price is selected)
When a pattern in trade closes either due to hitting stop or target
Important Note: Alerts fired via this method may not match the trades shown on chart as trades which are controlled via pine strategy emulator depends on various other factors such as pyramiding.
Alert template is customisable and users can make use of available placeholders to get dynamic data in alerts. Valid placeholders are
{alertType} - Alert type - New/Update/Close
{id} - Pattern Id
{ticker} - Ticker
{timeframe} - Chart timeframe
{price} - Current price
{patterns} - Identified pattern names
{direction} - Direction - Long/Short
{entry} - Entry Price
{stop} - Stop Price
{target} - Target Price
{orderType} - Limit/Stop - applicable for only New and Update types
{status} - Trade status. Valid values are Pending/Cancelled/Stopped/Success
Template is common for all custom alert types. Hence, updating the template will impact all custom alerts - New/Update/Close
{
"alert" : "{alertType}",
"id" : {id},
"ticker" : "{ticker}",
"timeframe" : "{timeframe}",
"price" : {price},
"patterns" : "{patterns}",
"direction" : "{direction}",
"entry" : {entry},
"stop" : {stop},
"target" : {target},
"orderType" : {orderType}
"status" : {status}
}
Here is a video on how to customise the alerts using templates and placeholders - HOW-TO-Customize-Alerts-With-Placeholders
🎯 Miscellaneous :
These are simple settings to control display and backtest bars. If you are running alerts, we suggest turning of Open Trades and Drawings and limit backtest to minimal value in order to improve efficiency of
🎯 Backtest Engine Parameters :
Default settings are optimised for trend following. Users are encouraged to play around with settings and filters to build strategy out of this tool.
Position sizing is not leveraged. Margin settings makes sure that trades cannot exceed capital.
All measures are taken to avoid repainting. Script does not use request.security and real time bars. This drastically reduces the risk of repainting in scripts.
If you are premium user, please select "Bar Magnifier".

Band Based Trend FilterSimilar to RelativeBandwidthFilter , this script is also a simple trend filter which can be used to define your trading zone.
🎲 Concept
On contrary to reversal mindset, we define trend when price hits either side of the band. If close price hits upper band then it is considered as bullish and if close price hits lower band, then it is considered bearish. Further, trend strength is measured in terms of how many times the price hits one side of the band without hitting other side. Hit is counted only if price has touched middle line in between the touches. This way price walks on the bands are considered as just one hit.
🎲 Settings
Settings are minimal and details can be found in the tooltips against each parameters
🎲 Usage
This can be used with your own strategy to filter your trading/non-trading zones based on trend . Script plots a variable called "Trend" - which is not shown on chart pane. But, it is available in the data window. This can be used in another script as external input and apply logic.
Trend values can be
1 : Allow only Long
-1 : Allow only short
0 : Do not allow any trades
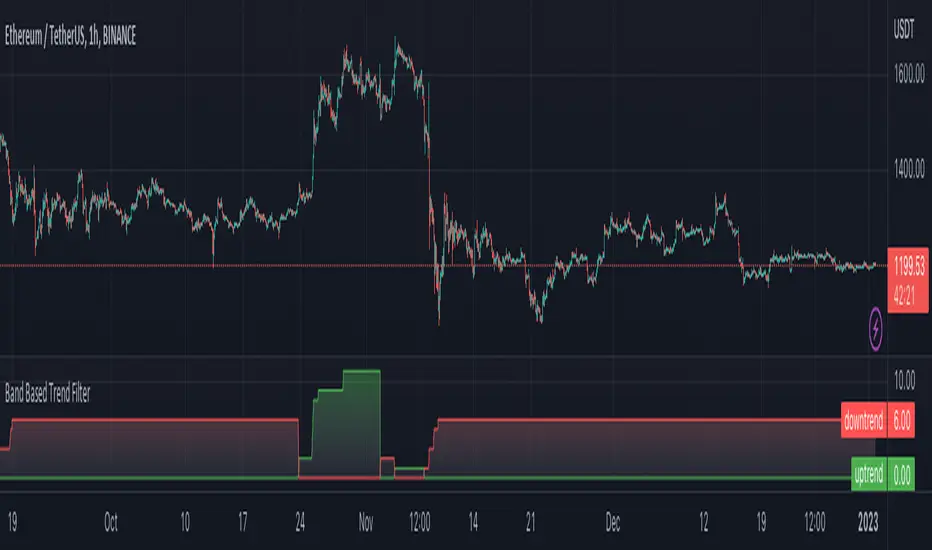
Wolfe Strategy [Trendoscope]Hello Everyone,
Wish you all Merry X-Mas and happy new year. Lets start 2023 with fresh new strategy built on Wolfe Indicator. Details of the indicator can be found here
🎲 Wolfe Concept
Wolfe concept is simple. Whenever a wedge is formed, draw a line joining pivot 1 and 4 as shown in the chart below:
For simplicity, we will only consider static value for Target and Stop. But, entry is done based on breaking the triangle. Revised strategy looks something like this:
🎲 Settings
Settings are simple and details of each are provided via tooltips.
Out of these, the most important one is minimum risk reward ratio. If you set lower risk reward threshold then losing few trades may generate more losses than more winning trades. Similarly higher value will filter out most of the trades and may not work efficiently. Default value set to 1 to make sure optimal risk reward is present before placing trade. Also make note that since the entry bar is always moving towards stop, as and when pattern progress, the RR will also increase. Hence, a pattern which is below RR threshold may become good to trade at certain point of time in future.
🎲 Strategy Parameters
Default strategy parameters are initialised via definition. Margins are set to 100 to disable leveraged trades. Appropriate values are chosen for other parameters. These can be altered based on individual strategy and trading plan.
As the strategy concentrates on the single pattern, number of trades generated are comparatively less. But, there is chance to increase the algorithm further to catch more such patterns on larger scale. Will try to work on them in next versions.
🎲 Pine Strategy limitations
Backtest can only be done on one direction as pine strategy cannot have both long and short open trades together. Hence, it is mandatory to chose either long/short trades in settings.
Since pyramiding is limited to 1, there is possibility of a pattern not generating trade even though the entry conditions are met. They are just based on pine limitations and not necessarily mean patterns are not good for placing trades.
