Statistics

Simple Leveraged PnLThis script shows your live trade PnL, ROE, R:R ratio, margin, leverage, entry, TP, and SL directly on the chart.
It draws:
Green/red zones for your Take Profit and Stop Loss ranges.
A pinned info card (movable to any corner of the chart) showing all key trade details in one place.
You can fully customize:
Card position (top/middle/bottom × left/middle/right)
Text size, colors, and background
Zone transparency
It works for both Long and Short positions and updates in real time.

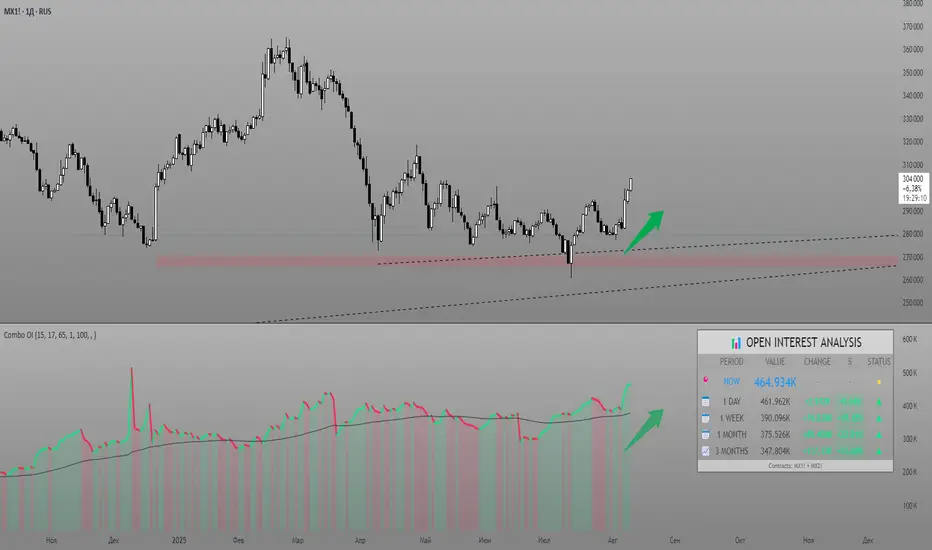
Combined Futures Open Interest [Sam SDF-Solutions]The Combined Futures Open Interest indicator is designed to provide comprehensive analysis of market positioning by aggregating open interest data from the two nearest futures contracts. This dual-contract approach captures the complete picture of market participation, including rollover dynamics between front and back month contracts, offering traders crucial insights into institutional positioning and market sentiment.
Key Features:
Dual-Contract Aggregation: Automatically identifies and combines open interest from the first and second nearest futures contracts (e.g., ES1! + ES2!), providing a complete view of market positioning that single-contract analysis might miss.
Multi-Period Analysis: Tracks open interest changes across multiple timeframes:
1 Day: Immediate market sentiment shifts
1 Week: Short-term positioning trends
1 Month: Medium-term institutional flows
3 Months: Quarterly positioning aligned with contract expiration cycles
Smart Data Handling: Utilizes last known values when data is temporarily unavailable, preventing false signals from data gaps while clearly indicating when stale data is being used.
EMA Smoothing: Incorporates a customizable Exponential Moving Average (default 65 periods) to identify the underlying trend in open interest, filtering out daily noise and highlighting significant deviations.
Dynamic Visualization:
Color-coded main line showing directional changes (green for increases, red for decreases)
Optional fill areas between OI and EMA to visualize momentum
Separate contract lines for detailed rollover analysis
Customizable labels for significant percentage changes
Comprehensive Information Table: Displays real-time statistics including:
Current total open interest across both contracts
Period-over-period changes in absolute and percentage terms
EMA deviation metrics
Visual status indicators for quick assessment
Contract symbols and data quality warnings
Alert System: Configurable alerts for:
Significant daily changes (customizable threshold)
EMA crossovers indicating trend changes
Large percentage movements suggesting institutional activity
How It Works:
Contract Detection: The indicator automatically identifies the base futures symbol and constructs the appropriate contract codes for the two nearest expirations, or accepts manual symbol input for non-standard contracts.
Data Aggregation: Open interest data from both contracts is retrieved and summed, providing a complete picture that accounts for positions rolling between contracts.
Historical Comparison: The indicator calculates changes from multiple lookback periods (1/5/22/66 days) to show how positioning has evolved across different time horizons.
Trend Analysis: The EMA overlay helps identify whether current open interest is above or below its smoothed average, indicating momentum in position building or reduction.
Visual Feedback: The main line changes color based on daily changes, while the optional table provides detailed numerical analysis for traders requiring precise data.
___________________
This indicator is essential for futures traders, particularly those focused on index futures, commodities, or currency futures where understanding the aggregate positioning across nearby contracts is crucial. It's especially valuable during rollover periods when positions shift between contracts, and for identifying institutional accumulation or distribution patterns that single-contract analysis might miss. By combining multiple timeframe analysis with intelligent data handling and clear visualization, it simplifies the complex task of monitoring open interest dynamics across the futures curve.
Quant Signals: Market Sentiment Monitor HUDWavelets & Scale Spectrum
This indicator is ideal for traders who adapt their strategy to market conditions — such as swing traders, intraday traders, and system developers.
Trend-followers can use it to confirm trending conditions before entering.
Mean-reversion traders can spot choppy markets where reversals are more likely.
Risk managers can monitor volatility shifts and regime changes to adjust position size or pause trading.
It works best as a market context filter — telling you the “weather” before you decide on the trade.
Wavelets are like tiny “measuring rulers” for price changes. Instead of looking at the whole chart at once, a wavelet looks at differences in price over a specific time scale — for example, 2 bars, 4 bars, 8 bars, and so on.
The scale spectrum is what you get when you measure volatility at several of these scales and then plot them against scale size.
If the spectrum forms a straight line on a log–log chart, it means price changes follow a consistent pattern across time scales (a power-law relationship).
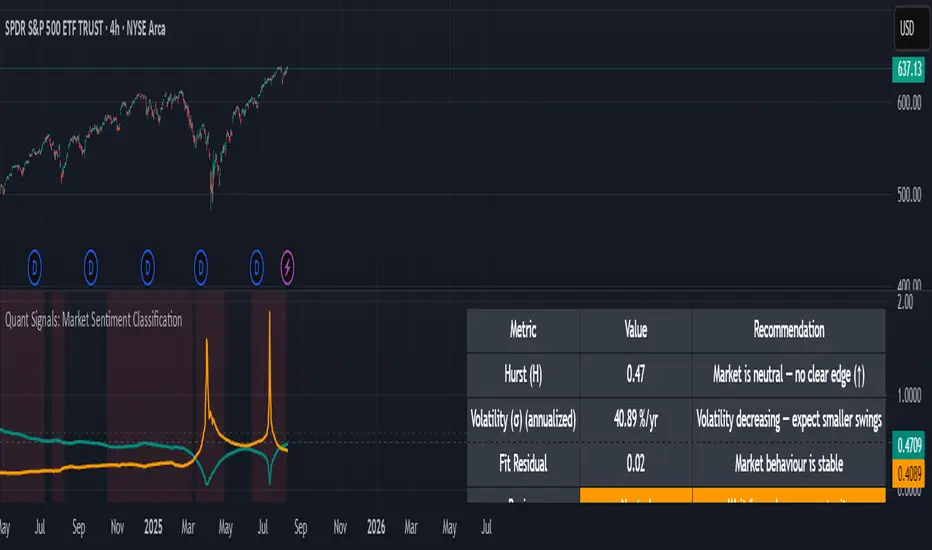
The slope of that line gives the Hurst exponent (H) — telling you whether moves tend to persist (trend) or reverse (mean-revert).
The height of the line gives you the volatility (σ) — the average size of moves.
This approach works like a microscope, revealing whether the market’s behaviour is consistent across short-term and long-term horizons, and when that behaviour changes.
This tool applies a wavelet-based scale-spectrum analysis to price data to estimate three key market state measures inside a rolling window:
Hurst exponent (H) — measures persistence in price moves:
H > ~0.55 → market is trending (moves tend to continue).
H < ~0.45 → market is choppy/mean-reverting (moves tend to reverse).
Values near 0.5 indicate a neutral, random-walk-like regime.
Volatility (σ) — the average size of price swings at your chart’s timeframe, optionally annualized. Rising volatility means larger price moves, falling volatility means smaller moves.
Fit residual — how well the observed multi-scale volatility fits a clean power-law line. Low residual = stable behaviour; high residual = structural change (possible regime shift).
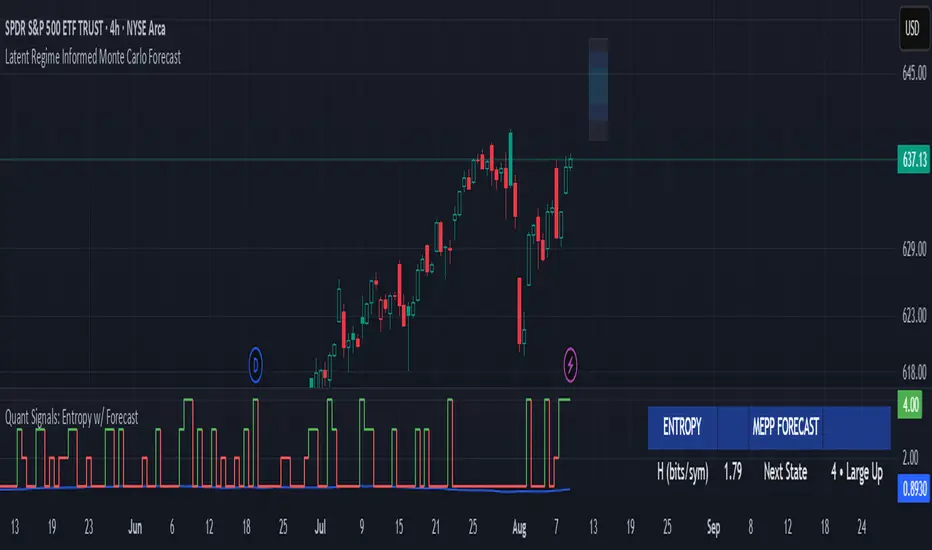
Quant Signals: Entropy w/ ForecastThis is the first of many quantitative signals I plan to create for TV users.
Most technical analysis (TA) tools—like moving averages, oscillators, or chart patterns—are heuristic: they’re based on visually identifiable shapes, threshold crossovers, or empirically chosen rules. These methods rarely quantify the information content or structural complexity of market data. By quantifying market predictability before making a forecast, this method filters out noise and focuses your trading only during statistically favorable conditions—something traditional TA cannot objectively measure.
This MEPP-based approach is quantitative and model-free:
It comes from information theory and measures Shannon entropy rate to assess how predictable the market is at any moment.
Instead of interpreting price formations, it uses a data-compression algorithm (Lempel–Ziv) to capture hidden structure in the sequence of returns.
Forecasts are generated using a principle from statistical physics (Maximum Entropy Production), not historical chart patterns.
In short, this method measures the market's predictability BEFORE deciding a directional forecast is worth trusting. This tool is to inform TA traders on the market's current regime, whether it is smooth and predictable or it is volatile and turbulent.
Technical Introduction:
In information theory, Shannon entropy measures the uncertainty (or information content) in a sequence of data. For markets, the entropy rate captures how much new information price returns generate over time:
Low entropy rate → price changes are more structured and predictable.
High entropy rate → price changes are more random and unpredictable.
By discretizing recent returns into quartile-based states, this indicator:
Calculates the normalized entropy rate as a regime filter.
Uses MEPP to forecast the next state that maximizes entropy production.
Displays both the regime status (predictable vs chaotic) and the forecast bias (bullish/bearish) in a dashboard.
Measurements & How to Use Them
TLDR: HIGH ENTROPY -> information generation/market shift -> Don't trust forecast/strategy
1. H (bits/sym)
Shannon entropy rate of the last μ discrete returns, in bits per symbol (0–2).
Lower → more predictable; higher → more random.
Use as a raw measure of market structure.
2. H_max (log₂Ω)
Theoretical maximum entropy for Ω states. Here Ω = 4 → H_max = 2.0 bits.
Reference value for normalization.
3. Entropy (norm)
H / H_max, scaled between 0 and 1.
< 0.5–0.6 → predictable regime; > 0.6 → chaotic regime.
Main regime filter — forecasts are more reliable when below your threshold.
4. Regime
Label based on Entropy (norm) vs your entThresh.
LOW (predictable) = higher odds forecast will be correct.
HIGH (chaotic) = forecasts less reliable.
5. Next State (MEPP Forecast)
Discrete return state (1–4) predicted to occur next, chosen to maximize entropy production:
Large Down (strong bearish)
Small Down (mild bearish)
Small Up (mild bullish)
Large Up (strong bullish)
Use as your bias direction.
6. Bias
Simplified label from the Next State:
States 1–2 = Bearish bias (red)
States 3–4 = Bullish bias (green)
Align strategy direction with bias only in LOW regime.
Relative Volume + Z-score + Normal Volume + Avg. VolumeA statistical way to visualize volume analytically compared to traditional volume. All Lookback Periods and Colors can be changed so user can make it feel personalized
- Relative Volume (RVOL) visualizer with the color of the histogram bar changing to represent exceeding a threshold specified by the user
For example --> (1.5 = Orange Bar) & (2 = Red Bar)
- Toggle View between RVOL visualization of volume vs. normal view of volume plot
- Z score lookback for volume across specified lookback per what user wants (dot/symbol above the bar)
- Average Volume Plot
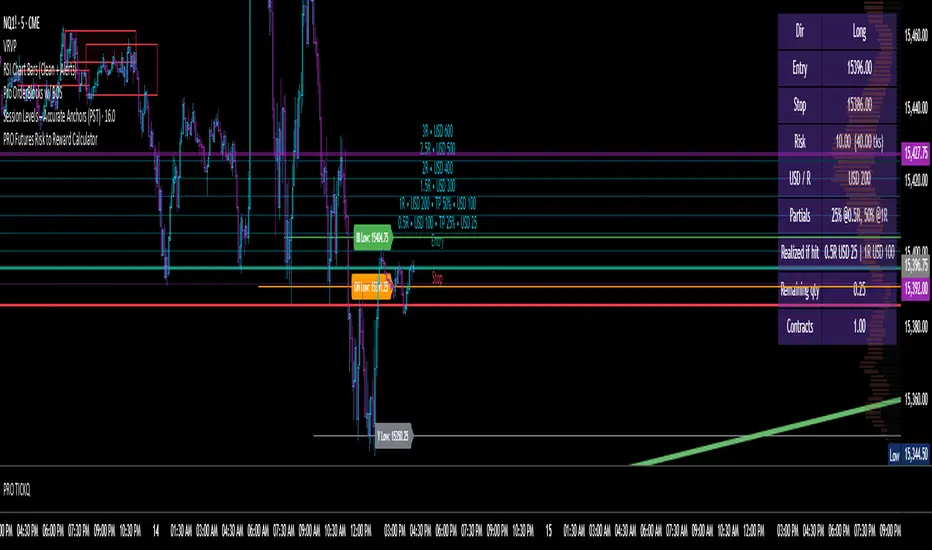
Futures Risk to Reward CalculatorFutures Risk to Reward Calculator with NQ, MNQ, ES, MES, etc price per tick built in.
ADR/ATR Session by LK## **Features**
1. **Custom ADR & ATR Calculation**
* Calculates **Average Daily Range (ADR)** and **Average True Range (ATR)** separately for:
* **Session timeframe** (default H4 / 06:00–13:00)
* **Daily timeframe**
* Independent smoothing method selection (**SMA, EMA, RMA, WMA**) for H4 ADR, H4 ATR, Daily ADR, and Daily ATR.
2. **Percentage Metrics**
* % of ADR / ATR covered by the **current H4 bar**.
* ADR / ATR expressed as a percentage of the **current price**.
* % of ADR already reached for the **current day**.
* % of Daily ATR vs current day’s True Range.
3. **Dynamic Chart Lines**
* Draws **3 lines for H4**: Session Open, ADR High, ADR Low.
* Draws **3 lines for Daily**: Daily Open, ADR High, ADR Low.
* Lines **extend to the right** so they stay visible across the chart.
* Colors and widths are fully customizable.
4. **Real-Time Data Table**
* Compact table displaying all ADR/ATR values and percentages.
* Adjustable table font size (**tiny, small, normal, large, huge**).
* Transparent background option for minimal chart obstruction.
5. **Flexible Session Settings**
* Select session start and end time in hours/minutes.
* Choose session timezone (chart timezone or major financial centers).
* Toggle H4 lines, Daily lines separately.
6. **Lookahead Control**
* Option to wait for higher-timeframe candle close before updating values (more accurate, less repainting).
---
## **How to Use**
### **1. Adding the Indicator**
* Copy and paste the Pine Script into TradingView’s Pine Editor.
* Click **“Add to chart”**.
* Make sure your chart supports the higher timeframes you choose (e.g., H4 and Daily).
### **2. Setting Your Session**
* **Session Start Hour** & **End Hour** → Defines the intraday session to measure ADR/ATR (default: 06:00–13:00).
* **Session Timezone** → Pick “Chart” or a major financial center (e.g., New York, London, Tokyo).
### **3. Choosing Smoothing Methods**
* For each ADR/ATR (H4 and Daily), choose:
* SMA (Simple)
* EMA (Exponential)
* RMA (Wilder’s smoothing)
* WMA (Weighted)
### **4. Adjusting Chart Display**
* **Show H4 Lines** → Displays session open and ADR High/Low for the current H4 session.
* **Show Daily Lines** → Displays daily open and ADR High/Low.
* Customize line colors and widths.
### **5. Reading the Table**
* **H4 Section**
* ADR / ATR values for the selected session.
* % of ADR/ATR covered by the **current H4 bar**.
* ADR/ATR as % of the current price.
* **Daily Section**
* ADR / ATR for the daily timeframe.
* % of ADR already covered by today’s range.
* ADR/ATR as % of price.
### **6. Pro Tips**
* Use **H4 ADR %** to gauge intraday exhaustion — if current range is near 100%, market may slow or reverse.
* Use **Daily ADR %** for swing trade context — if a day has moved beyond its ADR, expect lower continuation probability.
* Combine with support/resistance to identify high-probability reversal zones.

Cycle Phase & ETA Tracker [Robust v4]
Cycle Phase & ETA Tracker
Description
The Cycle Phase & ETA Tracker is a powerful tool for analyzing market cycles and predicting the completion of the current cycle (Estimated Time of Arrival, or ETA). It visualizes the cycle phase (0–100%) using a smoothed signal and displays the forecasted completion date with an optional confidence band based on cycle length variability. Ideal for traders looking to time their trades based on cyclical patterns, this indicator offers flexible settings for robust cycle analysis.
Key Features
Cycle Phase Visualization: Tracks the current cycle phase (0–100%) with color-coded zones: green (0–33%), blue (33–66%), orange (66–100%).
ETA Forecast: Shows a vertical line and label indicating the estimated date of cycle completion.
Confidence Band (±σ): Displays a band around the ETA to reflect uncertainty, calculated using the standard deviation of cycle lengths.
Multiple Averaging Methods: Choose from three methods to calculate average cycle length:
Median (Robust): Uses the median for resilience against outliers.
Weighted Mean: Prioritizes recent cycles with linear or quadratic weights.
Simple Mean: Applies equal weights to all cycles.
Adaptive Cycle Length: Automatically adjusts cycle length based on the timeframe or allows a fixed length.
Debug Histogram: Optionally displays the smoothed signal for diagnostic purposes.
Setup and Usage
Add the Indicator:
Search for "Cycle Phase & ETA Tracker " in TradingView’s indicator library and apply it to your chart.
Configure Parameters:
Core Settings:
Track Last N Cycles: Sets the number of recent cycles used to calculate the average cycle length (default: 20). Higher values provide stability but may lag market shifts.
Source: Selects the data source for analysis (e.g., close, open, high; default: close price).
Use Adaptive Cycle Length?: Enables automatic cycle length adjustment based on timeframe (e.g., shorter for intraday, longer for daily) or uses a fixed length if disabled.
Fixed Cycle Length: Defines the cycle length in bars when adaptive mode is off (default: 14). Smaller values increase sensitivity to short-term cycles.
Show Debug Histogram: Enables a histogram of the smoothed signal for debugging signal behavior.
Cycle Length Estimation:
Average Mode: Selects the method for calculating average cycle length: "Median (Robust)", "Weighted Mean", or "Simple Mean".
Weights (for Weighted Mean): For "Weighted Mean", chooses "linear" (moderate emphasis on recent cycles) or "quadratic" (strong emphasis on recent cycles).
ETA Visualization:
Show ETA Line & Label: Toggles the display of the ETA line and date label.
Show ETA Confidence Band (±σ): Toggles the confidence band around the ETA, showing the uncertainty range.
Band Transparency: Adjusts the transparency of the confidence band (0 = fully transparent, 100 = fully opaque; default: 85).
ETA Color: Sets the color for the ETA line, label, and confidence band (default: orange).
Interpretation:
The cycle phase (0–100%) indicates progress: green for the start, blue for the middle, and orange for the end of the cycle.
The ETA line and label show the predicted cycle completion date.
The confidence band reflects the uncertainty range (±1 standard deviation) of the ETA.
If a warning "Insufficient cycles for ETA" appears, wait for the indicator to collect at least 3 cycles.
Limitations
Requires at least 3 cycles for reliable ETA and confidence band calculations.
On low timeframes or low-volatility markets, zero-crossings may be infrequent, delaying ETA updates.
Accuracy depends on proper cycle length settings (adaptive or fixed).
Notes
Test the indicator across different assets and timeframes to optimize settings.
Use the debug histogram to troubleshoot if the ETA appears inaccurate.
For feedback or suggestions, contact the author via TradingView.
Cycle Phase & ETA Tracker
Описание
Индикатор Cycle Phase & ETA Tracker предназначен для анализа рыночных циклов и прогнозирования времени завершения текущего цикла (ETA — Estimated Time of Arrival). Он отслеживает фазы цикла (0–100%) на основе сглаженного сигнала и отображает предполагаемую дату завершения цикла с опциональной доверительной полосой, основанной на стандартном отклонении длин циклов. Индикатор идеально подходит для трейдеров, которые хотят выявлять циклические закономерности и планировать свои действия на основе прогнозируемого времени.
Ключевые особенности
Фазы цикла: Визуализирует текущую фазу цикла (0–100%) с цветовой кодировкой: зеленый (0–33%), синий (33–66%), оранжевый (66–100%).
Прогноз ETA: Показывает вертикальную линию и метку с предполагаемой датой завершения цикла.
Доверительная полоса (±σ): Отображает зону неопределенности вокруг ETA, основанную на стандартном отклонении длин циклов.
Гибкие методы усреднения: Поддерживает три метода расчета средней длины цикла:
Median (Robust): Медиана, устойчивая к выбросам.
Weighted Mean: Взвешенное среднее, где недавние циклы имеют больший вес (линейный или квадратичный).
Simple Mean: Простое среднее с равными весами.
Адаптивная длина цикла: Автоматически подстраивает длину цикла под таймфрейм или позволяет задать фиксированную длину.
Отладочная гистограмма: Опционально отображает сглаженный сигнал для анализа.
Настройка и использование
Добавьте индикатор:
Найдите "Cycle Phase & ETA Tracker " в библиотеке индикаторов TradingView и добавьте его на график.
Настройте параметры:
Core Settings:
Track Last N Cycles: Количество последних циклов для расчета средней длины (по умолчанию 20). Большие значения дают более стабильные результаты, но могут запаздывать.
Source: Источник данных (по умолчанию цена закрытия).
Use Adaptive Cycle Length?: Включите для автоматической настройки длины цикла по таймфрейму или отключите для использования фиксированной длины.
Fixed Cycle Length: Длина цикла в барах, если адаптивная длина отключена (по умолчанию 14).
Show Debug Histogram: Включите для отображения сглаженного сигнала (полезно для отладки).
Cycle Length Estimation:
Average Mode: Выберите метод усреднения: "Median (Robust)", "Weighted Mean" или "Simple Mean".
Weights (for Weighted Mean): Для режима "Weighted Mean" выберите "linear" (умеренный вес для новых циклов) или "quadratic" (сильный вес для новых циклов).
ETA Visualization:
Show ETA Line & Label: Включите для отображения линии и метки ETA.
Show ETA Confidence Band (±σ): Включите для отображения доверительной полосы.
Band Transparency: Прозрачность полосы (0 — полностью прозрачная, 100 — полностью непрозрачная, по умолчанию 85).
ETA Color: Цвет для линии, метки и полосы (по умолчанию оранжевый).
Интерпретация:
Фаза цикла (0–100%) показывает прогресс текущего цикла: зеленый — начало, синий — середина, оранжевый — конец.
Линия и метка ETA указывают предполагаемую дату завершения цикла.
Доверительная полоса показывает диапазон неопределенности (±1 стандартное отклонение).
Если отображается предупреждение "Insufficient cycles for ETA", дождитесь, пока индикатор соберет минимум 3 цикла.
Ограничения
Требуется минимум 3 цикла для надежного расчета ETA и доверительной полосы.
На низких таймфреймах или рынках с низкой волатильностью пересечения нуля могут быть редкими, что замедляет обновление ETA.
Эффективность зависит от правильной настройки длины цикла (fixedL или адаптивной).
Примечания
Протестируйте индикатор на разных таймфреймах и активах, чтобы подобрать оптимальные параметры.
Используйте отладочную гистограмму для анализа сигнала, если ETA кажется неточным.
Для вопросов или предложений по улучшению свяжитесь через TradingView.

Entropy (Fiedor/Kontoyiannis) - Part 2 of Fiedor's TheoryThis indicator estimates the Shannon entropy of a price series using a Markov chain model of binary returns, following the approach of Fiedor (2014) and Kontoyiannis (1997).
% of Max shows current entropy as a percentage of its theoretical maximum (1 bit for binary up/down moves).
Percentile ranks the current entropy against historical values in the chosen lookback window.
High entropy suggests price movement is less predictable by frequentist models; low entropy implies more structure and predictability.
Use this as an informational oscillator, not a trading signal.
This is a visualization of Part 1 of Fiedor's Theory. The same entropy logic is already embedded in Part 1 however the second pane is a nice reminder of why it works.

Binance Funding Rates [vichtoreb]Source: www.binance.com
The funding rate has two components: the interest rate and the average Premium Index.
Binance furnishes the Premium Index data for crypto assets on the TradingView platform. This script uses that data to calculate the funding rate.
Binance updates the Premium Index every 5 seconds.
The average Premium Index (denoted **P\_avg**) is the time-weighted average of all Premium Index data points:
P_avg = wma(Premium Index, n)
where **n** is the averaging length.
At each change time—8:00 PM, 4:00 AM, and 12:00 PM (UTC-4)—Binance sets
P_avg = wma(Premium Index, 5 760)
This is the weighted moving average of the last 8 hours because 5 760 × 5 s = 8 h. Binance then calculates the new funding rate:
Funding Rate = P_avg + clamp(interest rate − P_avg, −0.05 %, 0.05 %)
This value updates only at those change times (8:00 PM, 4:00 AM, and 12:00 PM, UTC-4).
**Indicator precision**
TradingView limits historical requests to 5 000 candles. To match Binance exactly, 5 760 candles are required. As a workaround, the script samples the Premium Index every *resolution* seconds (or minutes), where *resolution* is the indicator’s timeframe input.
If it weren't for this limitation, setting resolution = 5 sec, we would get EXACTLY the same result as the official one
**Interest rate**
On Binance Futures, the interest rate is 0.03 % per day by default (0.01 % per funding interval, as funding occurs every 8 hours). This does not apply to certain contracts, such as ETH/BTC, for which the interest rate is 0 %.
**Estimate line**
If the “show estimate” input is enabled, the indicator plots
wma(Premium Index, n) + clamp(interest rate − P_avg, −0.05 %, 0.05 %)
with **n** equal to the number of bars that have elapsed since the last funding-rate change.

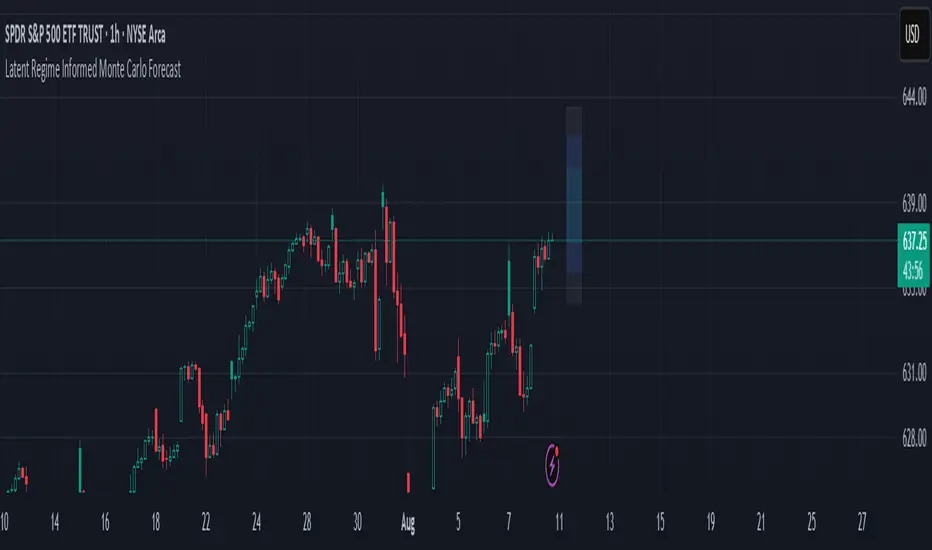
Latent Regime Informed Monte Carlo ForecastThis script uses a Monte Carlo simulation to forecast where price might be a set number of bars into the future (default 6 bars ahead). It generates hundreds of possible future price paths based on an average move (drift) and random shocks (volatility). The result is a distribution of outcomes, displayed as probability zones: the median (most likely), inner bands (50% confidence), and wider bands (80% and 95% confidence). Due to the randomness assumption in Monte Carlo simulations, the paths are not very important so to minimize cluttering on the graphs we only plot bands. These zones help you visualize uncertainty, set stops and targets based on probabilities, and spot when market behavior changes.
The accuracy of any Monte Carlo forecast depends heavily on how well you estimate trend and volatility. By default and no prior information the Monte Carlo simulation gives you a parabolic forecast that assumes absolute randomness. This is where the Kalman filter comes in. The filter (derived from control theory) aims to detect latent (unobservable) traits about the system by continuously updating its transition probabilities to better understand how the latent traits affect the observable measurement (price). With each new observable state we get better and better transition probabilities and enhances our understanding about the latent and unobservable market characteristics like trend and volatility. Both crucial measurements for short term market sentiment.
Extracting these measurements for market sentiment informs us how to better parametrize the Monte Carlo simulation for a better forecast. Each bar, the KF updates its estimates based on how close its last prediction was to reality. In calm periods, it holds estimates steady; in volatile periods, it adapts quickly. This gives you real-time, low-lag measurements of both trend and volatility.
By feeding these adaptive estimates into the Monte Carlo simulation, the forecast becomes much more responsive to current market conditions. In trends, the predicted paths tilt toward the direction of movement; in choppy markets, they spread wider but stay centered; when volatility spikes, the probability zones expand immediately. The result is a dynamic forecast tool that adjusts on every bar, giving you a clearer, probability-based picture of where the market could go next.
This is my very first script and I would love feedback/ideas for different topics.
My background is in economics/mathematics and interests lie in time series analysis/exploring financial features for DS
Adaptive Correlation Engine (ACE)🧠 Adaptive Correlation Engine (ACE)
Quantify inter-asset relationships with adaptive lag detection and actionable insights.
📌 What is ACE?
The Adaptive Correlation Engine (ACE) is a precision tool for seeking to uncover meaningful relationships between two assets — not just raw correlation, but also lag dynamics, leader detection, and alignment vs. divergence classification.
Unlike static correlation tools, ACE intelligently scans multiple lag windows to find:
✅ The maximum correlation between the base asset and a comparison symbol
⏱️ The optimal lag (if any) at which the correlation is strongest
🧭 Whether the assets are Aligned (positive correlation) or Divergent (inverse)
🔁 Which symbol is leading, and by how many bars
📈 Actionable signal strength based on a user-defined correlation threshold
⚙️ How It Works
Correlation Scan:
For each bar, ACE checks the correlation between the charted asset (close) and a lagged version of the comparison asset across a sliding window of lookback periods.
Lag Optimization:
The engine searches from lag 0 up to your specified Max Lag to find where the correlation (positive or negative) is most significant.
Relationship Classification:
The indicator classifies the relationship as:
Aligned: Positive correlation above the threshold
Divergent: Negative correlation above the threshold
Synchronous: No lag detected
Low Signal: Correlation is weak or noisy
Visual & Tabular Insights:
ACE plots the highest detected correlation on the chart and shows an insight table displaying:
- Correlation value
- Detected lag
- Direction type (aligned/divergent)
- Leading asset
- Suggested action (e.g., “Likely continuation” or “Possible mean reversion”)
💡 How to Use It
Use ACE to identify leadership patterns between assets (e.g., ETH leads altcoins, SPX leads crypto, etc.)
Spot potential lagging trade setups where one asset’s move may soon echo in another
Confirm or challenge correlation-based trading assumptions with data
Combine with technical indicators or price action to time entries and exits more confidently
🔔 Alerts
Built-in alerts notify you when correlation strength crosses your actionable threshold, classified by alignment or divergence.
🛠️ Inputs
Compare Symbol: The asset to compare against (e.g., INDEX:ETHUSD)
Correlation Lookback: Rolling window for calculating correlation
Max Lag Bars: Maximum lag shift to test
Minimum Actionable Correlation: Signal threshold for trade-worthy insights
⚠️ Disclaimer
This tool is for research and informational purposes only. It does not constitute financial advice or a trading signal. Always perform your own due diligence and consult a financial advisor before making investment decisions.

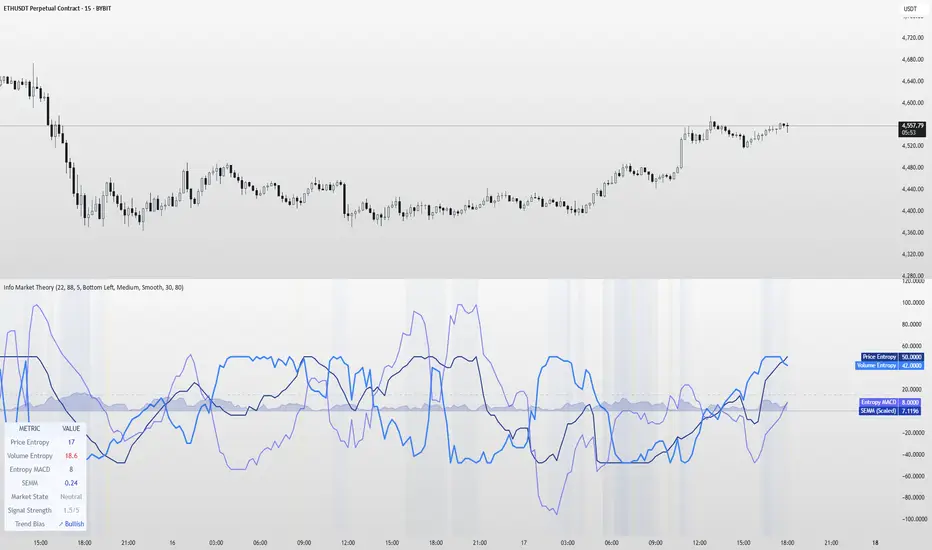
Information Theory Market AnalysisINFORMATION THEORY MARKET ANALYSIS
OVERVIEW
This indicator applies mathematical concepts from information theory to analyze market behavior, measuring the randomness and predictability of price and volume movements through entropy calculations. Unlike traditional technical indicators, it provides insight into market structure and regime changes.
KEY COMPONENTS
Four Main Signals:
• Price Entropy (Deep Blue): Measures randomness in price movements
• Volume Entropy (Bright Blue): Analyzes volume pattern predictability
• Entropy MACD (Purple): Shows relationship between price and volume entropy
• SEMM (Royal Blue): Stochastic Entropy Market Monitor - overall market randomness gauge
Market State Detection:
The indicator identifies seven distinct market states:
• Strong Trending (SEMM < 0.1)
• Weak Trending (0.1-0.2)
• Neutral (0.2-0.3)
• Moderate Random (0.3-0.5)
• High Randomness (0.5-0.8)
• Very Random (0.8-1.0)
• Chaotic (>1.0)
KEY FEATURES
Advanced Analytics:
• Signal Strength Confluence: 0-5 scale measuring alignment of multiple factors
• Entropy Crossovers: Detects shifts between accumulation and distribution phases
• Extreme Readings: Identifies statistical outliers for potential reversals
• Trend Bias Analysis: Directional momentum assessment
Information Dashboard:
• Real-time entropy values and market state
• Signal strength indicator with visual highlighting
• Trend bias with directional arrows
• Color-coded alerts for extreme conditions
Customizable Display:
• Adjustable SEMM scaling (5x to 100x) for optimal visibility
• Multiple line styles: Smooth, Stepped, Dotted
• 9 table positions with 3 size options
• Professional blue color scheme with transparency controls
Comprehensive Alert System - 15 Alert Types Including:
• Extreme entropy readings (price/volume)
• Crossover signals (dominance shifts)
• Market state changes (trending ↔ random)
• High confluence signals (3+ factors aligned)
HOW TO USE
Reading the Signals:
• Entropy Values > ±25: Strong structural signals
• Entropy Values > ±40: Extreme readings, potential reversals
• SEMM < 0.2: Trending market favors directional strategies
• SEMM > 0.5: Random market favors range/scalping strategies
Signal Confluence:
Look for multiple factors aligning:
• Signal Strength ≥ 3.0 for higher probability setups
• Background highlighting indicates confluence
• Table shows real-time strength assessment
Timeframe Optimization:
• Short-term (1m-15m): Entropy Length 14-22, Sensitivity 3-5
• Swing Trading (1H-4H): Default settings optimal
• Position Trading (Daily+): Entropy Length 34-55, Sensitivity 8-12
EDUCATIONAL APPLICATIONS
Market Structure Analysis:
• Understand when markets are trending vs. ranging
• Identify accumulation and distribution phases
• Recognize extreme market conditions
• Measure information content in price movements
Information Theory Concepts:
• Binary entropy calculations applied to financial data
• Probability distribution analysis of returns
• Statistical ranking and percentile analysis
• Momentum-adjusted randomness measurement
TECHNICAL DETAILS
Calculations:
• Uses binary entropy formula: -
• Percentile ranking across multiple timeframes
• Volume-weighted probability distributions
• RSI-adjusted momentum entropy (SEMM)
Customization Options:
• Entropy Length: 5-100 bars (default: 22)
• Average Length: 10-200 bars (default: 88)
• Sensitivity: 1.0-20.0 (default: 5.0, lower = more sensitive)
• SEMM Scaling: 5.0-100.0x (default: 30.0)
IMPORTANT NOTES
Risk Considerations:
• Indicator measures probabilities, not certainties
• High SEMM values (>0.5) suggest increased market randomness
• Extreme readings may persist longer than expected
• Always combine with proper risk management
Educational Purpose:
This indicator is designed for:
• Market structure analysis and education
• Understanding information theory applications in finance
• Developing probabilistic thinking about markets
• Research and analytical purposes
Performance Tips:
• Allow 200+ bars for proper initialization
• Adjust scaling and transparency for optimal visibility
• Use confluence signals for higher probability analysis
• Consider multiple timeframes for comprehensive analysis
DISCLAIMER
This indicator is for educational and analytical purposes. It does not constitute financial advice. Past performance does not guarantee future results. Always conduct your own research and consider your risk tolerance before making trading decisions.
Version: 5.0
Category: Oscillators, Volume, Market Structure
Best For: All timeframes, trending and ranging markets
Complexity: Intermediate to Advanced
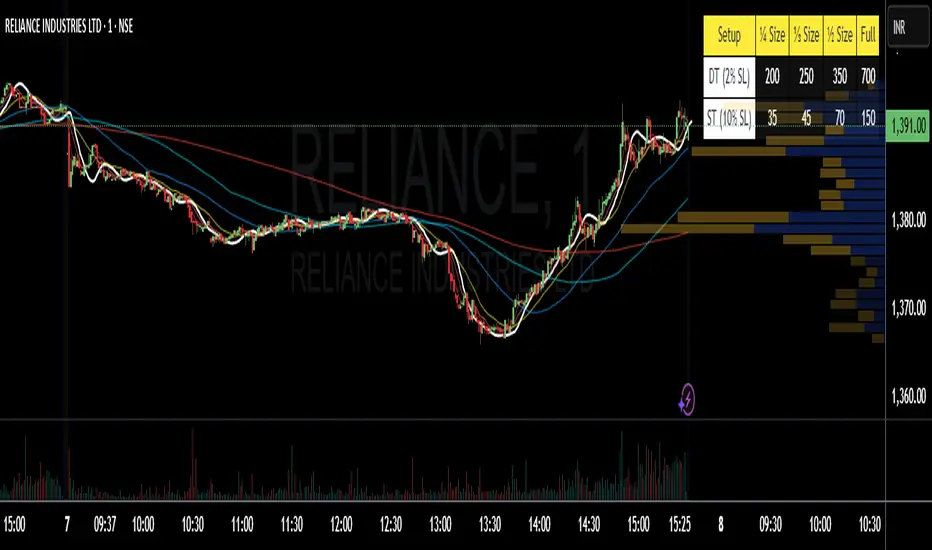
Position Size 📐 DT/ST (Today's Open)💡 Purpose:
This indicator automatically calculates intraday (DT) and swing trading (ST) position sizes based on your account capital, risk per trade, and stop-loss percentage, using today’s daily open price as the entry price reference.
⚙️ Main Functionalities:
Dynamic Position Sizing
Calculates Full size position based on the maximum risk you allow per trade.
Breaks it down into ¼ Size, ⅓ Size, and ½ Size positions for flexible scaling.
Two Distinct Trading Styles:
DT (Day Trading) – Uses your specified intraday stop-loss % (default: 2%).
ST (Swing Trading) – Uses your specified swing stop-loss % (default: 10%).
Lot Size Rounding
Automatically rounds quantities to a chosen lot size (e.g., 1 for cash equity or futures lot size for derivatives).
Customizable Table Position
Display the table anywhere on your chart: Top Right, Top Left, Bottom Right, or Bottom Left.
Optimized for Dark or Light Themes
Yellow header with black text for visibility.
Blue row labels for strategy type.
Grey background with white text for calculated values.
Live Market Adaptation
All values update in real-time as today’s daily open price changes (on new daily candles).
Works for any symbol, asset class, or time frame.
🧮 Formula:
Position Size (Full) = Max Risk ₹ / (Price × StopLoss%)
¼, ⅓, and ½ Sizes = Scaled from Full size
📌 Ideal For:
Traders who want quick, ready-to-use position sizes right on their chart.
Those who follow fixed risk-per-trade and need fast decision-making without manual calculations.
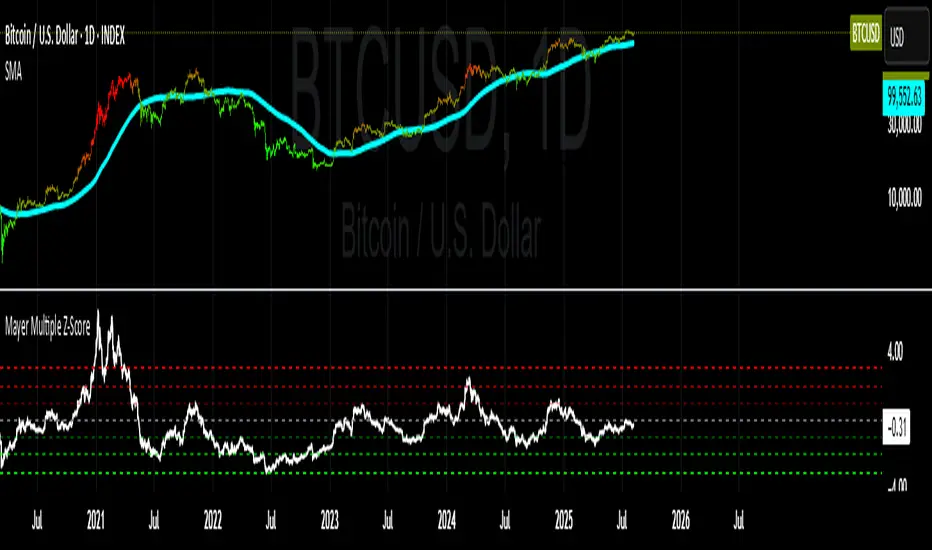
Mayer Multiple Z-ScoreMayer Multiple is a ratio between the current Market Price and its 200 days moving average.
Being a lagging indicator it shows periods of relative value for the asset but does not have much predictive power.
It is worth noting that the indicator relies on a fairly responsive moving average on the scale of a Bitcoin market cycle and as such may be best suited for the swing traders to find zones where price is overbought and oversold within a market cycle.
Added the Z-Score metric for easy classification of the value of Bitcoin according to this indicator. Customizable thresholds from Z-Score calculation as the metric suffers alpha decay / compression.
Created for TRW
SMC Structure IndicatorTitle: SMC Structures Indicator
Description:
The SMC Structures indicator is a powerful tool designed to identify and visualize key structural elements in price action, based on the principles of Smart Money Concepts (SMC). This indicator helps traders identify potential areas of support, resistance, and price reversals by highlighting significant market structures.
Key Features:
Structure Identification: The indicator automatically detects and marks important high and low structures in the market.
Break of Structure (BOS) Detection: It identifies and labels instances where previous structures are broken, indicating potential trend changes or continuations.
Change of Character (CHoCH) Detection: The indicator recognizes and marks Changes of Character, which are significant shifts in market behavior.
Customizable Visuals: Users can personalize the appearance of BOS and CHoCH markings, including colors, line styles, and widths.
Current Structure Display: The indicator can optionally show the current active structure, helping traders understand the immediate market context.
Historical Structure Tracking: Users can specify the number of historical structure breaks to display, allowing for a cleaner chart while maintaining relevant information.
Flexible Break Confirmation: The indicator offers the option to confirm structure breaks using either the candle body or wick, accommodating different trading styles.
Technical Details:
The indicator uses advanced algorithms to identify significant price structures based on local highs and lows.
It employs a lookback period of 10 bars for structure detection, ensuring relevance to current market conditions.
The code includes safeguards to handle different market phases and avoid false signals during ranging periods.
Customization Options:
Colors for Bullish and Bearish BOS and CHoCH markings
Line styles and widths for all structure markings
Number of historical breaks to display
Option to show or hide the current active structure
Choice between candle body or wick for structure break confirmation
Use Cases:
Trend Analysis: Identify the start of new trends or potential trend reversals.
Support and Resistance: Pinpoint key levels where price may react.
Trade Entry and Exit: Use structure breaks as potential entry or exit signals.
Market Context: Understand the broader market structure to make informed trading decisions.

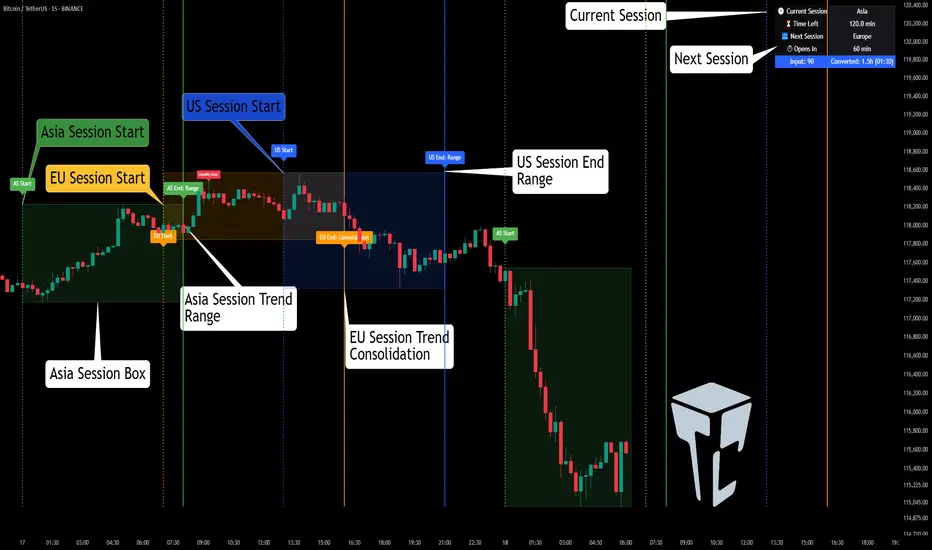
TCP | Market Session | Session Analyzer📌 TCP | Market Session Indicator | Crypto Version
A powerful, real-time market session visualization tool tailored for crypto traders. Track the heartbeat of Asia, Europe, and US trading hours directly on your chart with live session boxes, behavioral analysis, liquidity grab detection, and countdown timers. Know when the action starts, how the market behaves, and where the traps lie.
🔰 Introduction:
Trade the Right Hours with the Right Tools
Time matters in trading. Most significant moves happen during key sessions—and knowing when and how each session unfolds can give you a sharp edge. The TCP Market Session Indicator, developed by Trade City Pro (TCP), puts professional session tracking and behavioral insights at your fingertips.
Whether you're a scalper or swing trader, this indicator gives you the timing context to enter and exit trades with greater confidence and clarity.
🕒 Core Features
• Live Session Boxes :
Highlight active ranges during Asia, Europe, and US sessions with dynamic high/low updates.
• Session Start/End Labels :
Know exactly when each session begins and ends plotted clearly on your chart with context.
• Session Behavior Analysis :
At the end of each session, the indicator classifies the price action as:
- Trend Up
- Trend Down
- Consolidation
- Manipulation
• Liquidity Grab Detection: Automatically detects possible stop hunts (fake breakouts) and marks them on the chart with precision filters (volume, ATR, reversal).
• Session Countdown Table: A live dashboard showing:
- Current active session
- Time left in session
- Upcoming session and how many minutes until it starts
- Utility time converter (e.g. 90 min = 01:30)
• Vertical Session Lines: Visualize past and upcoming session boundaries with customizable history and future range.
• Multi-Day Support: Draw session ranges for previous, current, and future days for better backtesting and forecasting.
⚙️ Settings Panel
Customize everything to fit your trading style and schedule:
• Session Time Settings:
Set the opening and closing time for each session manually using UTC-based minute inputs.
→ For example, enter Asia Start: 0, Asia End: 480 for 00:00–08:00 UTC.
This gives full flexibility to adjust session hours to match your preferred market behavior.
• Enable or Disable Elements:
Toggle the visibility of each session (Asia, Europe, US), as well as:
- Session Boxes
- Countdown Table
- Session Lines
- Liquidity Grab Labels
• Timezone Selection:
Choose between using UTC or your chart’s local timezone for session calculations.
• Customization Options:
Select number of past and future days to draw session data
Adjust vertical line transparency
Fine-tune label offset and spacing for clean layout
📊 Smart Session Boxes
Each session box tracks high, low, open, and close in real time, providing visual clarity on market structure. Once a session ends, the box closes, and the behavior type is saved and labeled ideal for spotting patterns across sessions.
• Asia: Green Box
• Europe: Orange Box
• US: Blue Box
💡 Why Use This Tool?
• Perfect Timing: Don’t get chopped in low-liquidity hours. Focus on sessions where volume and volatility align.
• Pattern Recognition: Study how price behaves session-to-session to build better strategies.
• Trap Detection: Spot manipulation moves (liquidity grabs) early and avoid common retail pitfalls.
• Macro Session Mapping: Use as a foundational layer to align trades with market structure and news cycles.
🔍 Example Use Case
You're watching BTC at 12:45 UTC. The indicator tells you:
The Asia session just ended (label shows “Asia Session End: Trend Up”)
Europe session starts in 15 minutes
A liquidity grab just triggered at the previous high—label confirmed
Now you know who’s active, what the market just did, and what’s about to start—all in one glance.
✅ Why Traders Trust It
• Visual & Intuitive: Fully chart-based, no clutter, no guessing
• Crypto-Focused: Designed specifically for 24/7 crypto markets (not outdated forex models)
• Non-Repainting: All labels and boxes stay as printed—no tricks
• Reliable: Tested across multiple exchanges, pairs, and timeframes
🧩 Built by Trade City Pro (TCP)
The TCP Market Session Indicator is part of a suite of professional tools used by over 150,000 traders. It’s coded in Pine Script v6 for full compatibility with TradingView’s latest capabilities.
🔗 Resources
• Tutorial: Learn how to analyze sessions like a pro in our TradingView guide:
"TradeCityPro Academy: Session Mapping & Liquidity Traps"
• More Tools: Explore our full library of indicators on
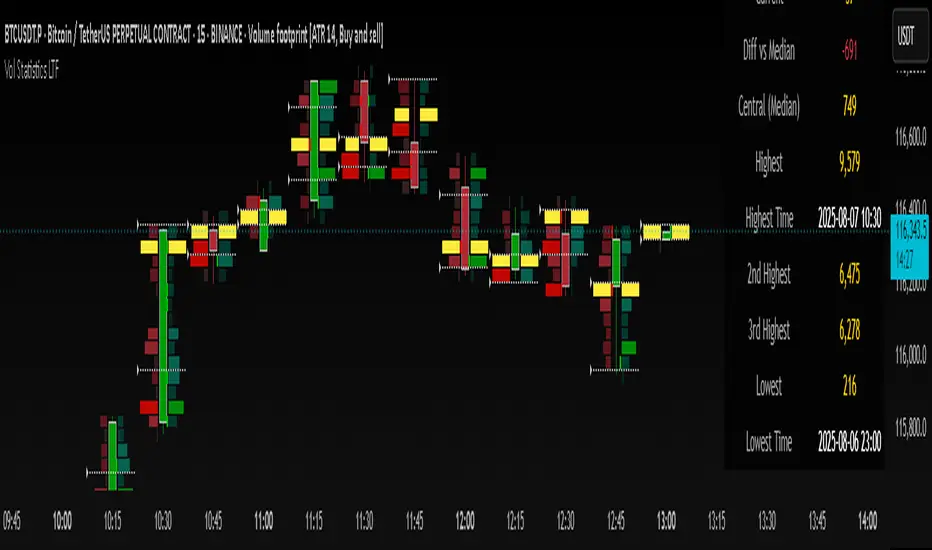
Volume Statistics - IntraweekVolume Statistics - Intraweek: For Orderflow Traders
This tool is designed for traders using volume footprint charts and orderflow methods.
Why it matters:
In orderflow trading, you care about the quality of volume behind each move. You’re not just watching price; you’re watching how much aggression is behind that price move. That’s where this indicator helps.
What to look at:
* Current Volume shows you how much volume is trading right now.
* Central Volume (median or average over 24h or 7D) gives you a baseline for what's normal volume VS abnormal volume.
* The Diff vs Central tells you immediately if current volume is above or below normal.
How this helps:
* If volume is above normal, it suggested elevated levels of buyer or seller aggression. Look for strong follow-through or continuation.
* If volume is below normal, it may signal low interest, passive participation, a lack of conviction, or a fake move.
* Use this context to decide if what you're seeing in the footprint (imbalances, absorption, traps) is actually worth acting on.
Extra context:
* The highest and lowest volume levels and their timestamps help you spot prior key reactions.
* Second and third highest bars help you see other major effort points in the recent window.
Comment with any suggestions on how to improve this indicator.
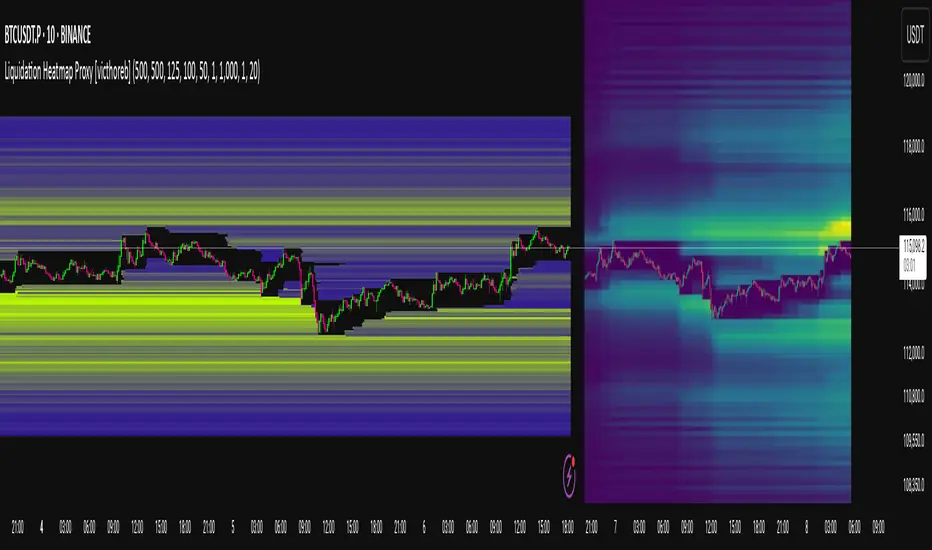
Liquidation Heatmap Proxy [victhoreb]Author: victhoreb
This script was inspired by the Coinglass indicator: www.coinglass.com
It divides each bar into subbars determined by the intrabar period. For each bar, it considers subbars with a positive OID (open interest delta) (if the user sets "Filter by Signal" to true, it only considers subbars with OID > 0 from a main bar that had a peak in open interest). In these subbars, it considers opened long/short positions based on the intrabar price movement and the dispersion factor (which becomes completely unnecessary if the user is using Intrabar Resolution in ticks; in this case, set the dispersion factor = 0).
After determining the opened long and short positions, it determines, based on the user-selected leverages, the liquidation level for each position. The width of each level is given by syminfo.mintick * scale. The script uses the intrabar OID from the previous step to store an estimate of the number of contracts to be liquidated at each level. This estimate is used to color the levels by order of magnitude.
If there is a subsequent increase in liquidations at a pre-existing level, the script accumulates the estimated number of contracts to be liquidated and repaints the level. A note about a visual limitation of the script is important: in Coinglass' version, when there is a subsequent increase in liquidations at a pre-existing level, Coinglass paints the level a brighter color ONLY from the moment of the increase—however, this script does not do this; it repaints the entire level with the brighter color. Note: While accurate, this script is only a proxy. Use at your own risk.
This script has alerts for when there is liquidation in the long or short direction.
Bollinger Heatmap [Quantitative]Overview
The Bollinger Heatmap is a composite indicator that synthesizes data derived from 30 Bollinger bands distributed over multiple time horizons, offering a high-dimensional characterization of the underlying asset.
Algorithm
The algorithm quantifies the current price’s relative position within each Bollinger band ensemble, generating a normalized position ratio. This ratio is subsequently transformed into a scalar heat value, which is then rendered on a continuous color gradient from red to blue. Red hues correspond to price proximity to or extension below the lower band, while blue hues denote price proximity to or extension above the upper band.
Using default parameters, the indicator maps bands over timeframes increasing in a pattern approximating exponential growth, constrained to multiples of seven days. The lower region encodes relationships with shorter-term bands spanning between 1 and 14 weeks, whereas the upper region portrays interactions with longer-term bands ranging from 15 to 52 weeks.
Conclusion
By integrating Bollinger bands across a diverse array of time horizons, the heatmap indicator aims to mitigate the model risk inherent in selecting a single band length, capturing exposure across a richer parameter space.

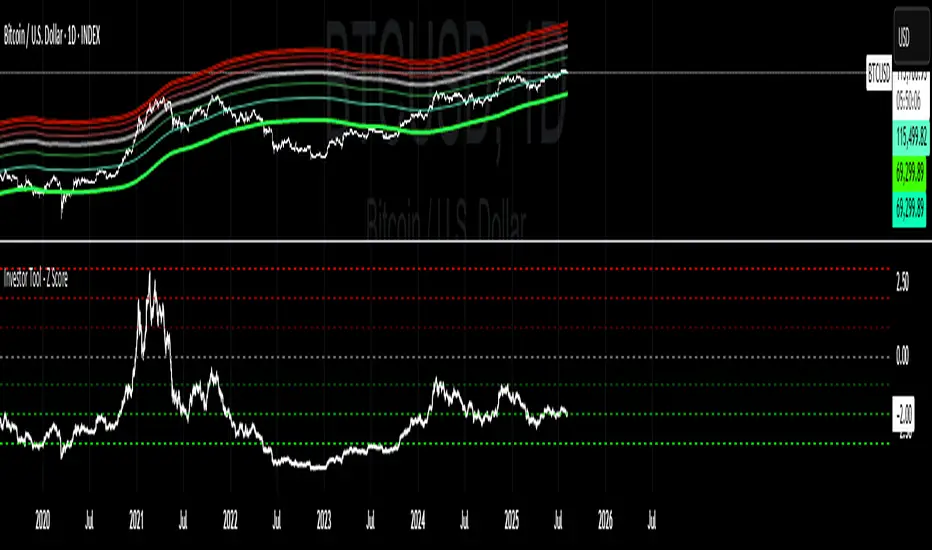
Investor Tool - Z ScoreThe Investor Tool is intended as a tool for long term investors, indicating periods where prices are likely approaching cyclical tops or bottoms. The tool uses two simple moving averages of price as the basis for under/overvalued conditions: the 2-year MA (green) and a 5x multiple of the 2-year MA (red).
Price trading below the 2-year MA has historically generated outsized returns, and signalled bear cycle lows.
Price trading above the 2-year MA x5 has been historically signalled bull cycle tops and a zone where investors de-risk.
Just like the Glassnode one, but here on TV and with StDev bands
Now with Z-SCORE calculation:
The Z-Score is calculated to be -3 Z at the bottom bands and 3 Z at the top bands
mean = (upper_sma + bottom_sma) / 2
bands_range = upper_sma - bottom_sma
stdDev = bands_range != 0 ? bands_range / 6 : 0
zScore = stdDev != 0 ? (close - mean) / stdDev : 0
Created for TRW